数据库约束
约束的定义
定义:创建表时,给这个表制定一些规则,后续插入/修改/删除都要保证数据能够遵守这些规则.
约束类型
共分为not null, unique, default, primary key, check这几种
null约束
);
unique:唯一约束
);
default:默认值约束
定义:规定没有给列赋值时赋默认值.(默认情况下的默认值设置为null)
);
primary key:主键约束(重要)
定义:not null和unique的结合.确保某列(或两个列,多个列的组合)有唯一标识(就是一个记录的身份标识),有助于更容易更快速地找到表中的一个特定记录.(通常用xxx id作为主键,通常一个表中只有一个主键).
);

foreign key:外键约束(描述两个表之间的关联)
— 字段名是指本表的哪个列— 主表是指被关联的表— 列就是被关联的表的哪个列
);
1.把约束别的表的表称为”父表”.
把被约束的表,称为”子表“.
2.外键约束,也是双向的,要想删除父表的记录,就必须先删除子表中的相关数据,以确保子表中没有数据.
3.使用外键约束时,操作子表,要查询父表;操作父表,也要查询子表.子表和父表中被引用的列都要带有”索引“.表里有了主键之后,就会自动创建出索引,加快查询速度
4.扩展知识:对电脑上的文件进行删除,也只是逻辑上的删除,不是真的删除.把文件删除掉,其实也是在系统中,把硬盘对应的盘块数据标记为无效了(所以不是真正意义上的删除)
表的设计
一般思路
三大范式
一对一

一对多
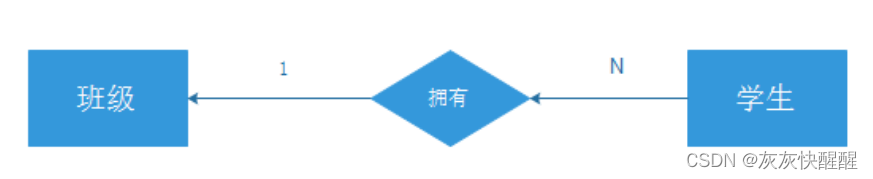

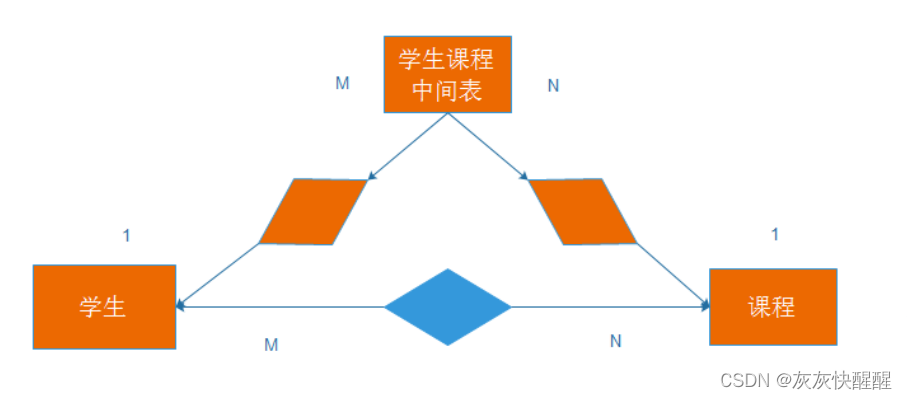
多对多
创建课程表
name
VARCHAR
(
20
));
FOREIGN KEY (student_id) REFERENCES student(id),);
新增
案例:创建一张用户表,设计有name姓名,email邮箱,sex性别,mobile手机号字段.需要把已有的学生数据复制进来,可以复制的字段有name, qq_mail.
);
查询
聚合查询
定义:就是”行和行”之间的运算,但此处行之间的运算具有一定限制,不像表达式查询(表达式查询是操作列).
聚合函数
使用聚合函数时,列和列之间,已经被”打散了”,如果查询中包含聚合函数,和非聚合的列,各自是各自的.大部分情况,聚合的列和非聚合的列是不能混用的,一种情况除外(group by(后面讲))
| 函数 | 说明 |
| count([distinct] expr) | 返回查询到数据的数量 |
| sum([distinct] expr) | 返回查询到的数据的总和,不是数字则没有意义 |
| avg([distinct] expr) | 返回查询到数据的平均值,不是数字则没有意义 |
| max([distinct] expr) | 返回查询到数据的最大值,不是数字则没有意义 |
| min([distinct] expr) |
案例:
SELECT COUNT
(*)
FROM
student;SELECT COUNT
(
0
)
FROM
student;SELECT COUNT
(qq_mail)
FROM
student;
sum:
注意:
max:
— 返回英语最高分
min:
group by字句
在select中使用group by可以对指定列进行分组查询.需要满足:使用group by进行分组查询时,select指定的字段必须是”分组依据字段”, 其它字段如想出现在select中,必须包含在聚合函数中.
实际效果就是把这个指定的列,值相同的记录划分到一组,针对这些组就可以分别聚合查询了,分组操作,往往是和”聚合“配合使用的.
案例:
准备测试表及数据:职员表,有id(主键), name(姓名), role(角色), salary(薪水)
);(
‘
隔壁老王
‘
,
‘
董事长
‘
,
12000.66
);
having
group字句进行分组之后,需要对分组结果再进行条件过滤时,不能使用where语句,而需要用having语句.(即分组之前的条件,使用where表示;分组之后的条件,使用having表示)
联合查询(也称多表查询)
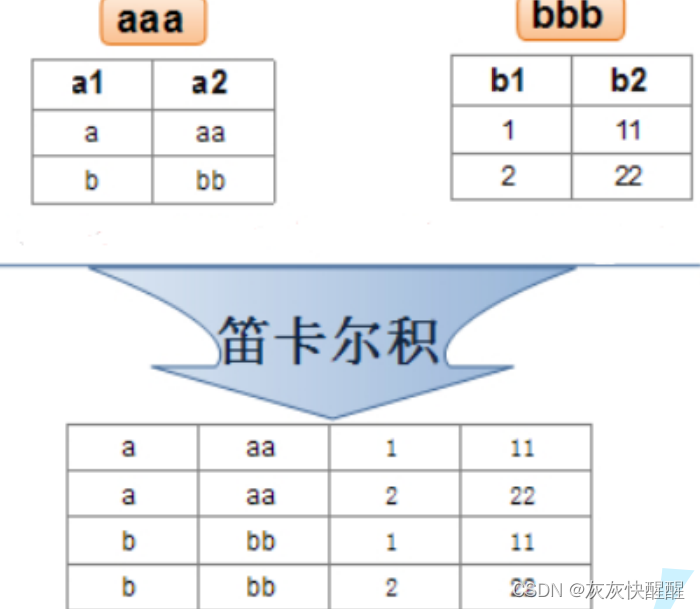
所谓多表联合查询,核心操作为笛卡尔积,然后指定一些条件之类的,来实现需求中的一些查询结果.
实际开发中往往数据来自不同的表,所以需要多表联合查询.多表查询是对多张表的数据取笛卡尔积:
(
‘00835’
,
‘
菩提老祖
‘
,
null
,
1
),(
‘00391’
,
‘
白素贞
‘
,
null
,
1
),(
‘00054’
,
‘
不想毕业
‘
,
null
,
1
),);—
黑旋风李逵(
70.5
,
1
,
1
),(
98.5
,
1
,
3
),(
33
,
1
,
5
),(
98
,
1
,
6
),—
菩提老祖(
60
,
2
,
1
),(
59.5
,
2
,
5
),—
白素贞(
33
,
3
,
1
),(
68
,
3
,
3
),(
99
,
3
,
5
),—
许仙(
67
,
4
,
1
),(
23
,
4
,
3
),(
56
,
4
,
5
),(
72
,
4
,
6
),—
不想毕业(
81
,
5
,
1
),(
37
,
5
,
5
),—
好好说话(
56
,
6
,
2
),(
43
,
6
,
4
),(
79
,
6
,
6
),— tellme(
80
,
7
,
2
),(
92
,
7
,
6
);
1.笛卡尔积2.连接条件3.根据需求指定其他条件(筛选行)
内连接
定义:是内连接查询中一种特殊的等值连接,所谓的自连接就是指表与其自己当前表进行连接。自己和自己做连接。
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;(个人最推荐第二种,嘎嘎好用)
案例:
—
或者stu
.name
=
‘
许仙
‘
;
SELECTstu
.id
,stu
.sn
,stu
.NAME
,stu
.qq_mail
,sco
.course_id
,cou
.NAMEFROMstudent stuJOIN
course cou
ON
sco
.course_id
= cou
.idORDER BYstu.id;
外连接
外连接分为左外连接和右外连接.如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接. 外连接也是多表查询的一种表现形式,一般使用比较少,属于特殊情况特殊处理.
语法:
— 左外连接,表一完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
— 右外连接,表二完全显示
为了形象展示内连接,左外连接和右外连接的区别,下面我们来看这一组图:

案例:查询所有学生的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示
SELECTstu
.id
,stu
.sn
,stu
.NAME
,stu
.qq_mail
,sco
.course_id
,cou
.NAMEFROMstudent stuLEFT
JOIN
course cou
ON
sco
.course_id
= cou
.idORDER BYstu
.id
;
自连接
顾名思义,自连接就是指在同一张表中进行查询.
案例:
显示所有”计算机原理“成绩比”Java”成绩高的成绩信息(在这个例子中,要想完成不同科目的比较,就需要比较行之间的大小,因为sql是无法实现这个功能的,所以只能将行转为列)
— 让我们使用四部曲来写一下(1)将所有内容进行笛卡尔积select * from score as s1, score as s2;(2)连接条件:两张表student_id相同select * from score as s1, score as s2 where s1.student_id = s2.student_id;(3)只筛选出要比较的课程id的数据select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1;(4)找出结果
子查询
子查询是指嵌入在其它sql语句中的select语句,也叫嵌套查询(这个查询方法虽然很装逼但不建议用,所以了解这个即可,自己写的时候尽量不要这样写)
举个例子:查询与”不想毕业”同班的同学:
name=
‘
不想毕业
‘
);
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符union, union all.使用union和union all时,前后查询结果集中,字段需要一致.(合并查询其实用的很少,了解即可)
union
原文地址:https://blog.csdn.net/asdssadddd/article/details/134318145
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_31656.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!