声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及一些参考资料:多表连接的三种方式详解 hash join、merge join、 nested loop、openGauss数据库源码解析系列文章——执行器解析(二)
连接算子
连接算子用于处理表关联,openGauss支持 12 种连接类型(inner join、left join、right join、full join、semi join、anti join等),提供了 3 种连接算子:hash join、Merge join、nested loop join 算子;其中,在先前的学习中,【OpenGauss源码学习 —— 执行算子(hash join 算子)】一文中详细介绍了 hash join 算子的执行过程。本文则来继续学习另一个扫描算子:Merge Join 算子。
Merge Join 算子
merge join 算子用于支持排序结果集连接,对应的代码源文件是“src/gausskernel/runtime/executor/nodeMergejoin.cpp”。通常情况下 hash 连接的效果都比排序合并连接要好,但如果元组已经被排序,在执行排序合并连接时不需要再排序,这时排序合并连接的性能会优于 hash 连接。Merge join 算子连接处理的逻辑同经典的归并排序算法相似,需要首先找到匹配位置,然后迭代获取外表与内表匹配位置。
以下是 Merge Join 算法的原理和执行过程:
算法原理:
- 输入有序性要求: Merge Join 要求输入的两个关系已经按连接属性进行排序。这通常通过对关系进行排序操作来实现。
- 双指针遍历: Merge Join 使用两个指针,分别指向两个输入关系的当前位置。这两个指针按顺序遍历两个关系。
- 比较连接属性: 在每一步迭代中,算法比较两个指针所指位置的连接属性的值。如果这两个值相等,表示找到了匹配的元组,将它们合并并输出。如果不相等,移动指向较小值的指针。
- 处理相等值: 当找到相等的连接属性值时,Merge Join 需要处理可能存在的多个匹配元组。具体处理方式取决于连接类型(INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN 等)。
执行过程:
算子对应的主要函数如下表所示。
| 主要函数 | 说 明 |
|---|---|
| ExecInitMergeJoin | 初始化 Merge join 状态节点 |
| ExecMergeJoin | 处理归并连接 |
| ExecEndMergeJoin | 清理 Merge join 状态节点 |
| ExecReScanMergeJoin | 重置 Merge join 状态节点 |
为了更好地理解和学习 Merge join 算子的相关操作,我们还是从一个实际案例来入手吧。首先执行以下 sql 语句:
-- 创建 employees 表并插入数据
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
employee_name VARCHAR(100),
department_id INT
);
-- 给 employees 表插入一些数据
INSERT INTO employees (employee_name, department_id) VALUES
('Alice', 1),
('Bob', 2),
('Charlie', 1),
('David', 3);
-- 创建 departments 表并插入数据
CREATE TABLE departments (
department_id SERIAL PRIMARY KEY,
department_name VARCHAR(100)
);
-- 给 departments 表插入一些数据
INSERT INTO departments (department_name) VALUES
('HR'),
('IT'),
('Finance');
-- 关闭 hash join 和 nest loop
set enable_hashjoin = off;
set enable_nestloop = off;
-- 使用 Merge Join 执行等值连接
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
JOIN
departments ON employees.department_id = departments.department_id;
employee_id | employee_name | department_id | department_name
-------------+---------------+---------------+-----------------
1 | Alice | 1 | HR
2 | Bob | 2 | IT
3 | Charlie | 1 | HR
4 | David | 3 | Finance
(4 rows)
-- 查看执行信息
EXPLAIN ANALYZE
SELECT
employees.employee_id,
employees.employee_name,
employees.department_id,
departments.department_name
FROM
employees
JOIN
departments ON employees.department_id = departments.department_id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
Merge Join (cost=53.21..59.61 rows=319 width=444) (actual time=0.110..0.130 rows=4 loops=1)
Merge Cond: (employees.department_id = departments.department_id)
-> Sort (cost=26.46..27.25 rows=319 width=226) (actual time=0.082..0.084 rows=4 loops=1)
Sort Key: employees.department_id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on employees (cost=0.00..13.19 rows=319 width=226) (actual time=0.015..0.016 rows=4 loops=1)
-> Sort (cost=26.75..27.56 rows=324 width=222) (actual time=0.023..0.023 rows=4 loops=1)
Sort Key: departments.department_id
Sort Method: quicksort Memory: 25kB
-> Seq Scan on departments (cost=0.00..13.24 rows=324 width=222) (actual time=0.006..0.008 rows=3 loops=1)
Total runtime: 1.123 ms
(11 rows)
ExecInitMergeJoin 函数
首先,在函数 ExecInitMergeJoin 中插入断点,调试信息如下,通过打印可以看到函数的调用关系。
ExecInitMergeJoin 函数是对 Merge Join 节点进行初始化的核心部分。它设置了节点的状态、表达式上下文、子节点的初始化,元组表的初始化,以及连接状态的初始化。它还处理了左右连接的情况、额外的 MARK 标志、元组的填充等情况。最后,它预处理了连接条件,并设置连接状态为初始化外部。
┌──nodeMergejoin.cpp─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│1387 (node->js.ps.plan)->plan_node_id, │
│1388 getSessionMemoryUsageMB())); │
│1389 │
│1390 return NULL; │
│1391 } │
│1392 │
│1393 /* ---------------------------------------------------------------- │
│1394 * ExecInitMergeJoin │
│1395 * ---------------------------------------------------------------- │
│1396 */ │
│1397 MergeJoinState* ExecInitMergeJoin(MergeJoin* node, EState* estate, int eflags) │
│1398 { │
│1399 /* check for unsupported flags */ │
B+>│1400 Assert(!(eflags & (EXEC_FLAG_BACKWARD | EXEC_FLAG_MARK))); │
│1401 │
│1402 MJ1_printf("ExecInitMergeJoin: %sn", "initializing node"); │
│1403 │
│1404 /* │
│1405 * create state structure │
│1406 */ │
│1407 MergeJoinState* merge_state = makeNode(MergeJoinState); │
│1408 merge_state->js.ps.plan = (Plan*)node; │
│1409 merge_state->js.ps.state = estate; │
│1410 │
│1411 /* │
│1412 * Miscellaneous initialization │
│1413 * │
│1414 * create expression context for node │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
multi-thre Thread 0x7f15a In: ExecInitMergeJoin Line: 1400 PC: 0x15f4bef
#0 ExecInitMergeJoin (node=0x7f15b89fb4b8, estate=0x7f15ac404060, eflags=16) at nodeMergejoin.cpp:1400
#1 0x000000000159930b in ExecInitNodeByType (node=0x7f15b89fb4b8, estate=0x7f15ac404060, eflags=16) at execProcnode.cpp:300
#2 0x0000000001599bf0 in ExecInitNode (node=0x7f15b89fb4b8, estate=0x7f15ac404060, e_flags=16) at execProcnode.cpp:497
#3 0x00000000015939ba in InitPlan (queryDesc=0x7f15b8af5c60, eflags=16) at execMain.cpp:1437
#4 0x0000000001591404 in standard_ExecutorStart (queryDesc=0x7f15b8af5c60, eflags=16) at execMain.cpp:382
#5 0x00007f160055e78a in gs_audit_executor_start_hook (queryDesc=0x7f15b8af5c60, eflags=0) at gs_policy_plugin.cpp:1907
#6 0x000000000139a43d in explain_ExecutorStart (queryDesc=0x7f15b8af5c60, eflags=0) at auto_explain.cpp:83
#7 0x0000000001590e1b in ExecutorStart (queryDesc=0x7f15b8af5c60, eflags=0) at execMain.cpp:228
#8 0x0000000001470c03 in PortalStart (portal=0x7f15ac3ae060, params=0x0, eflags=0, snapshot=0x0) at pquery.cpp:784
#9 0x000000000145d184 in exec_simple_query (
query_string=0x7f15ac346060 "SELECTn employees.employee_id,n employees.employee_name,n employees.department_id,n departments.department_name
nFROMn employeesnJOINn departments ON employees.department_id = departm"..., messageType=QUERY_MESSAGE, msg=0x7f15aa518110) at postgres.cpp:2549
#10 0x0000000001467c73 in PostgresMain (argc=1, argv=0x7f15b8b6eef0, dbname=0x7f15b8b6e2a0 "postgres", username=0x7f15b8b6e258 "kuchiki") at postgres.cpp:7855
#11 0x00000000013dfaa0 in BackendRun (port=0x7f15aa5186f0) at postmaster.cpp:6905
---Type <return> to continue, or q <return> to quit---
可以看到,无论是 ExecInitMergeJoin 函数还是 ExecInitHashJoin函数,其上层调用都是 ExecInitNodeByType 函数。ExecInitHashJoin 函数的源码如下所示:(路径:src/gausskernel/runtime/executor/nodeHashjoin.cpp)。
/**
* @brief 初始化 Merge Join 节点的执行状态
* @param node Merge Join 节点
* @param estate 执行状态信息
* @param eflags 执行标志
* @return 返回 Merge Join 节点的执行状态
*/
MergeJoinState* ExecInitMergeJoin(MergeJoin* node, EState* estate, int eflags)
{
/* 检查不支持的标志 */
Assert(!(eflags & (EXEC_FLAG_BACKWARD | EXEC_FLAG_MARK)));
MJ1_printf("ExecInitMergeJoin: %sn", "initializing node");
/*
* 创建状态结构体
*/
MergeJoinState* merge_state = makeNode(MergeJoinState);
merge_state->js.ps.plan = (Plan*)node;
merge_state->js.ps.state = estate;
/*
* 杂项初始化
*
* 为节点创建表达式上下文
*/
ExecAssignExprContext(estate, &merge_state->js.ps);
/*
* 我们需要两个额外的上下文,用于计算左右输入元组的连接表达式。
* 节点的常规上下文不适用,因为它经常被重置。
*/
merge_state->mj_OuterEContext = CreateExprContext(estate);
merge_state->mj_InnerEContext = CreateExprContext(estate);
/*
* 初始化子表达式
*/
merge_state->js.ps.targetlist = (List*)ExecInitExpr((Expr*)node->join.plan.targetlist, (PlanState*)merge_state);
merge_state->js.ps.qual = (List*)ExecInitExpr((Expr*)node->join.plan.qual, (PlanState*)merge_state);
merge_state->js.jointype = node->join.jointype;
merge_state->js.joinqual = (List*)ExecInitExpr((Expr*)node->join.joinqual, (PlanState*)merge_state);
merge_state->js.nulleqqual = (List*)ExecInitExpr((Expr*)node->join.nulleqqual, (PlanState*)merge_state);
merge_state->mj_ConstFalseJoin = false;
/* merge_clauses 在下面处理 */
/*
* 初始化子节点
*
* 内部子节点必须支持 MARK/RESTORE。
*/
outerPlanState(merge_state) = ExecInitNode(outerPlan(node), estate, eflags);
innerPlanState(merge_state) = ExecInitNode(innerPlan(node), estate, eflags | EXEC_FLAG_MARK);
/*
* 对于某些类型的内部子节点,每次我们越过一个永远不会返回的内部元组时发出 MARK 是有利的。
* 对于其他类型,对于我们永远不会返回的元组发出 MARK 是浪费时间。检测哪种情况适用,
* 如果我们想发出“不必要”的 MARK 调用,则设置 mj_ExtraMarks。
*
* 目前,只有 Material 需要额外的 MARK,并且仅在 eflags 没有指定 REWIND 时才有帮助。
*/
if (IsA(innerPlan(node), Material) && (eflags & EXEC_FLAG_REWIND) == 0)
merge_state->mj_ExtraMarks = true;
else
merge_state->mj_ExtraMarks = false;
/*
* 元组表初始化
*/
ExecInitResultTupleSlot(estate, &merge_state->js.ps);
merge_state->mj_MarkedTupleSlot = ExecInitExtraTupleSlot(estate);
ExecSetSlotDescriptor(merge_state->mj_MarkedTupleSlot, ExecGetResultType(innerPlanState(merge_state)));
switch (node->join.jointype) {
case JOIN_INNER:
case JOIN_SEMI:
merge_state->mj_FillOuter = false;
merge_state->mj_FillInner = false;
break;
case JOIN_LEFT:
case JOIN_ANTI:
case JOIN_LEFT_ANTI_FULL:
merge_state->mj_FillOuter = true;
merge_state->mj_FillInner = false;
merge_state->mj_NullInnerTupleSlot =
ExecInitNullTupleSlot(estate, ExecGetResultType(innerPlanState(merge_state)));
break;
case JOIN_RIGHT:
/* JOIN_RIGHT_ANTI_FULL 不能创建 mergejoin 计划,忽略它。 */
merge_state->mj_FillOuter = false;
merge_state->mj_FillInner = true;
merge_state->mj_NullOuterTupleSlot =
ExecInitNullTupleSlot(estate, ExecGetResultType(outerPlanState(merge_state)));
/*
* 不能处理具有非常量额外 joinclauses 的 right 或 full join。计划程序应该已经捕捉到这种情况。
*/
if (!check_constant_qual(node->join.joinqual, &merge_state->mj_ConstFalseJoin))
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("RIGHT JOIN is only supported with merge-joinable join conditions."),
errhint("Try other join methods like nestloop or hashjoin.")));
break;
case JOIN_FULL:
merge_state->mj_FillOuter = true;
merge_state->mj_FillInner = true;
merge_state->mj_NullOuterTupleSlot =
ExecInitNullTupleSlot(estate, ExecGetResultType(outerPlanState(merge_state)));
merge_state->mj_NullInnerTupleSlot =
ExecInitNullTupleSlot(estate, ExecGetResultType(innerPlanState(merge_state)));
/*
* 不能处理具有非常量额外 joinclauses 的 right 或 full join。计划程序应该已经捕捉到这种情况。
*/
if (!check_constant_qual(node->join.joinqual, &merge_state->mj_ConstFalseJoin))
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED),
errmsg("FULL JOIN is only supported with merge-joinable join conditions."),
errhint("Try other join methods like nestloop or hashjoin.")));
break;
default:
ereport(ERROR,
(errcode(ERRCODE_UNRECOGNIZED_NODE_TYPE),
errmsg("unrecognized join type: %d for mergejoin.", (int)node->join.jointype)));
}
/*
* 初始化元组类型和投影信息
* merge join 的结果表元组槽包含虚拟元组,因此默认的 tableAm 类型设置为 HEAP。
*/
ExecAssignResultTypeFromTL(&merge_state->js.ps, TAM_HEAP);
ExecAssignProjectionInfo(&merge_state->js.ps, NULL);
/*
* 预处理合并子句
*/
merge_state->mj_NumClauses = list_length(node->mergeclauses);
merge_state->mj_Clauses = MJExamineQuals(node->mergeclauses,
node->mergeFamilies,
node->mergeCollations,
node->mergeStrategies,
node->mergeNullsFirst,
(PlanState*)merge_state);
/*
* 初始化连接状态
*/
merge_state->mj_JoinState = EXEC_MJ_INITIALIZE_OUTER;
merge_state->js.ps.ps_TupFromTlist = false;
merge_state->mj_MatchedOuter = false;
merge_state->mj_MatchedInner = false;
merge_state->mj_OuterTupleSlot = NULL;
merge_state->mj_InnerTupleSlot = NULL;
/*
* 初始化成功
*/
MJ1_printf("ExecInitMergeJoin: %sn", "node initialized");
return merge_state;
}
(gdb) p * node
$1 = {join = {plan = {type = T_MergeJoin, plan_node_id = 1, parent_node_id = 0, exec_type = EXEC_ON_COORDS, startup_cost = 53.206830123628066,
total_cost = 59.611830123628067, plan_rows = 319, multiple = 1, plan_width = 444, dop = 1, pred_rows = 0, pred_startup_time = 0, pred_total_time = 0,
pred_max_memory = 0, recursive_union_plan_nodeid = 0, recursive_union_controller = false, control_plan_nodeid = 0, is_sync_plannode = false,
targetlist = 0x7f15b89fb6e0, qual = 0x0, lefttree = 0x7f15b89fbcc8, righttree = 0x7f15b89fcbe8, ispwj = false, paramno = -1, initPlan = 0x0,
distributed_keys = 0x0, exec_nodes = 0x7f15b89fd8d8, extParam = 0x0, allParam = 0x0, vec_output = false, hasUniqueResults = false, isDeltaTable = false,
operatorMemKB = {0, 0}, operatorMaxMem = 0, parallel_enabled = false, hasHashFilter = false, var_list = 0x0, filterIndexList = 0x0,
ng_operatorMemKBArray = 0x0, ng_num = 0, innerdistinct = 0, outerdistinct = 0}, jointype = JOIN_INNER, joinqual = 0x0, optimizable = false,
nulleqqual = 0x0, skewoptimize = 0}, mergeclauses = 0x7f15b89fda00, mergeFamilies = 0x7f15b89fdce0, mergeCollations = 0x7f15b89fdd28,
mergeStrategies = 0x7f15b89fdd70, mergeNullsFirst = 0x7f15b89fddb8}
(gdb) p * estate
$2 = {type = T_EState, es_direction = ForwardScanDirection, es_snapshot = 0x7f15ac3484f8, es_crosscheck_snapshot = 0x0, es_range_table = 0x7f15b89fde00,
es_plannedstmt = 0x7f15b89ff388, es_junkFilter = 0x0, es_output_cid = 0, es_result_relations = 0x0, es_num_result_relations = 0,
es_result_relation_info = 0x0, esCurrentPartition = 0x0, esfRelations = 0x0, es_result_remoterel = 0x0, es_result_insert_remoterel = 0x0,
es_result_update_remoterel = 0x0, es_result_delete_remoterel = 0x0, es_trig_target_relations = 0x0, es_trig_tuple_slot = 0x0, es_trig_oldtup_slot = 0x0,
es_trig_newtup_slot = 0x0, es_param_list_info = 0x0, es_param_exec_vals = 0x0, es_query_cxt = 0x7f15ac3b2d50, es_const_query_cxt = 0x7f15ac401a40,
es_tupleTable = 0x0, es_rowMarks = 0x0, es_processed = 0, es_last_processed = 0, es_lastoid = 0, es_top_eflags = 16, es_instrument = 0, es_finished = false,
es_exprcontexts = 0x0, es_subplanstates = 0x0, es_auxmodifytables = 0x0, es_remotequerystates = 0x0, es_per_tuple_exprcontext = 0x0, es_epqTuple = 0x0,
es_epqTupleSet = 0x0, es_epqScanDone = 0x0, es_subplan_ids = 0x0, es_skip_early_free = false, es_skip_early_deinit_consumer = false,
es_under_subplan = false, es_material_of_subplan = 0x0, es_recursive_next_iteration = false, dataDestRelIndex = 0, es_bloom_filter = {bfarray = 0x0,
array_size = 0}, es_can_realtime_statistics = false, es_can_history_statistics = false, isRowTriggerShippable = false}
(gdb) p eflags
$3 = 16
(gdb) p merge_state
$4 = (MergeJoinState *) 0x7ff9a6f4a060
(gdb) p *merge_state
$5 = {js = {ps = {type = T_MergeJoinState, plan = 0x7ff9a97b2a68, state = 0x7ff9a6f44060, instrument = 0x0, targetlist = 0x7ff9a6f4ac58, qual = 0x0,
lefttree = 0x7ff9a6f48060, righttree = 0x7ff9a6f84060, initPlan = 0x0, subPlan = 0x0, chgParam = 0x0, hbktScanSlot = {currSlot = 0},
ps_ResultTupleSlot = 0x7ff9a6f4b308, ps_ExprContext = 0x7ff9a6f4a288, ps_ProjInfo = 0x7ff9a6f4bb50, ps_TupFromTlist = false, vectorized = false,
nodeContext = 0x0, earlyFreed = false, stubType = 0 '00', jitted_vectarget = 0x0, plan_issues = 0x0, recursive_reset = false, qual_is_inited = false,
ps_rownum = 0}, jointype = JOIN_INNER, joinqual = 0x0, nulleqqual = 0x0}, mj_NumClauses = 1, mj_Clauses = 0x7ff9a6f4bce0, mj_JoinState = 1,
mj_ExtraMarks = false, mj_ConstFalseJoin = false, mj_FillOuter = false, mj_FillInner = false, mj_MatchedOuter = false, mj_MatchedInner = false,
mj_OuterTupleSlot = 0x0, mj_InnerTupleSlot = 0x0, mj_MarkedTupleSlot = 0x7ff9a6f4b478, mj_NullOuterTupleSlot = 0x0, mj_NullInnerTupleSlot = 0x0,
mj_OuterEContext = 0x7ff9a6f4a560, mj_InnerEContext = 0x7ff9a6f4a7d0}
此外,ExecInitNodeByType 函数中所涉及到的几种 JOIN 类型的含义如下:
| JOIN 类型 | 含 义 |
|---|---|
| JOIN_INNER: 内连接 | 返回两个表中匹配的行,不包括不匹配的行。 |
| JOIN_SEMI: 半连接 | 返回左表中有匹配行的行,不包括右表的列。 |
| JOIN_LEFT: 左外连接 | 返回左表中的所有行和右表中匹配的行。如果右表中没有匹配的行,返回 NULL 值。 |
| JOIN_ANTI: 反向半连接 | 返回左表中没有匹配行的行。 |
| JOIN_LEFT_ANTI_FULL: 左反向外连接 | 返回左表中没有匹配行的行,同时包括右表中没有匹配的行。 |
| JOIN_RIGHT: 右外连接 | 返回右表中的所有行和左表中匹配的行。如果左表中没有匹配的行,返回 NULL 值。 |
| JOIN_FULL: 完全外连接 | 返回左表和右表中的所有行。如果没有匹配的行,返回 NULL 值。 |
MergeJoin 结构体
MergeJoin 结构体作为 Merge Join 算子的结构体定义,其主要用于描述 Merge Join 算子的属性和参数。下面是对结构体中各字段的简要说明:(路径:src/include/nodes/plannodes.h)
/*
* Merge Join算子结构体
*
* 每个可合并列的预期排序方式由B树操作符族OID、排序规则OID、排序方向(BTLessStrategyNumber或BTGreaterStrategyNumber)和空值优先标志表示。
* 注意,每个连接条件的两侧可能具有不同的数据类型,但根据共同的操作符族和排序规则以相同的方式排序。
* 每个合并条件的操作符必须是指定的操作符族中的相等操作符。
*/
typedef struct MergeJoin {
Join join; // 继承自Join结构体,表示Merge Join算子的基本属性,包括连接的关系、连接类型等信息
List* mergeclauses; // 保存Merge Join算子的连接条件,以表达式树的形式表示,每个表达式树表示一个连接条件,可能包含多个合并键
Oid* mergeFamilies; // 数组,存储每个连接条件对应的B树操作符族(btree opfamily)的OID
Oid* mergeCollations; // 数组,存储每个连接条件对应的排序规则(collation)的OID
int* mergeStrategies; // 数组,存储每个连接条件的排序方式,是升序(ASC)还是降序(DESC)
bool* mergeNullsFirst; // 数组,存储每个连接条件的空值(NULL)排序方式,是在前面还是在后面
} MergeJoin;
ExecMergeJoin 函数
/* ----------------------------------------------------------------
* 执行Merge Join算子的主函数
*
* 参数:
* - node: Merge Join算子的状态信息
*
* 返回:
* - TupleTableSlot类型的指针,表示Merge Join算子的输出结果
* ----------------------------------------------------------------
*/
TupleTableSlot* ExecMergeJoin(MergeJoinState* node)
{
bool qual_result = false; // 存储连接条件的判定结果
int compare_result; // 存储合并键的比较结果
TupleTableSlot* inner_tuple_slot = NULL; // 存储内部表的元组槽
TupleTableSlot* outer_tuple_slot = NULL; // 存储外部表的元组槽
/*
* 从节点中获取相关信息
*/
PlanState* inner_plan = innerPlanState(node); // 获取内部表的计划状态
PlanState* outer_plan = outerPlanState(node); // 获取外部表的计划状态
ExprContext* econtext = node->js.ps.ps_ExprContext; // 获取表达式上下文
List* join_qual = node->js.joinqual; // 获取连接条件
List* other_qual = node->js.ps.qual; // 获取其他限制条件
bool do_fill_outer = node->mj_FillOuter; // 是否填充外部表的标志
bool do_fill_inner = node->mj_FillInner; // 是否填充内部表的标志
/*
* 检查是否仍在从先前的连接中投影出元组
* (因为在投影表达式中存在返回集的函数)。如果是这样,尝试投影另一个。
*/
if (node->js.ps.ps_TupFromTlist) {
TupleTableSlot* result = NULL;
ExprDoneCond isDone;
result = ExecProject(node->js.ps.ps_ProjInfo, &isDone);
if (isDone == ExprMultipleResult)
return result;
/* 完成对源元组的处理... */
node->js.ps.ps_TupFromTlist = false;
}
/*
* 重置每个元组的内存上下文,以释放在前一个元组周期中分配的任何表达式评估存储。
* 请注意,这只能在我们完成了从连接元组投影出元组之后发生。
*/
ResetExprContext(econtext);
/*
* 好的,一切都准备就绪,让我们开始工作
*/
for (;;) {
MJ_dump(node);
/*
* 获取连接的当前状态并根据需要执行相应的操作。
*/
switch (node->mj_JoinState) {
/*
* EXEC_MJ_INITIALIZE_OUTER表示这是第一次调用ExecMergeJoin(),
* 因此我们需要获取外部和内部子计划的第一个可匹配元组。
* 我们在INITIALIZE_OUTER状态下处理外部子计划,然后转到INITIALIZE_INNER状态处理内部子计划。
*/
case EXEC_MJ_INITIALIZE_OUTER:
MJ_printf("ExecMergeJoin: EXEC_MJ_INITIALIZE_OUTERn");
outer_tuple_slot = ExecProcNode(outer_plan);
node->mj_OuterTupleSlot = outer_tuple_slot;
/* 计算连接值并检查是否不可匹配 */
switch (MJEvalOuterValues(node)) {
case MJEVAL_MATCHABLE:
/* 可以开始获取第一个内部元组 */
node->mj_JoinState = EXEC_MJ_INITIALIZE_INNER;
break;
case MJEVAL_NONMATCHABLE:
/* 保持在相同的状态以获取下一个外部元组 */
if (do_fill_outer) {
/*
* 为内部元组生成一个带有空值的虚拟连接元组,
* 如果通过非连接条件,则返回该元组。
*/
TupleTableSlot* result = NULL;
result = MJFillOuter(node);
if (result != NULL)
return result;
}
break;
case MJEVAL_ENDOFJOIN:
/* 不再有外部元组 */
MJ_printf("ExecMergeJoin: nothing in outer subplann");
if (do_fill_inner) {
/*
* 需要为剩余的内部元组发出右连接元组。
* 我们设置MatchedInner = true以强制ENDOUTER状态推进内部。
*/
node->mj_JoinState = EXEC_MJ_ENDOUTER;
node->mj_MatchedInner = true;
break;
}
/*
* 如果MergeJoin的一侧返回0个元组,并且不需要生成具有null的虚构连接元组,
* 那么我们应该更早地在MergeJoin下取消初始化消费者。
* 应该注意,我们不能在predpush中提前取消初始化。
*/
if (((PlanState*)node) != NULL && !CheckParamWalker((PlanState*)node)) {
ExecEarlyDeinitConsumer((PlanState*)node);
}
/* Otherwise we're done. */
goto done;
default:
break;
}
break;
case EXEC_MJ_INITIALIZE_INNER:
MJ_printf("ExecMergeJoin: EXEC_MJ_INITIALIZE_INNERn");
inner_tuple_slot = ExecProcNode(inner_plan);
node->mj_InnerTupleSlot = inner_tuple_slot;
/* 计算连接值并检查不匹配 */
switch (MJEvalInnerValues(node, inner_tuple_slot)) {
case MJEVAL_MATCHABLE:
/*
* OK,我们有了初始元组。首先跳过非匹配的元组。
*/
node->mj_JoinState = EXEC_MJ_SKIP_TEST;
break;
case MJEVAL_NONMATCHABLE:
/* 在前进之前进行标记,如果需要的话 */
if (node->mj_ExtraMarks)
ExecMarkPos(inner_plan);
/* 保持相同的状态以获取下一个内部元组 */
if (do_fill_inner) {
/*
* 为外部元组生成带有 null 值的假连接元组,并在它通过非连接条件时返回
*/
TupleTableSlot* result = NULL;
result = MJFillInner(node);
if (result != NULL)
return result;
}
break;
case MJEVAL_ENDOFJOIN:
/* 不再有内连接 */
MJ_printf("ExecMergeJoin: nothing in inner subplann");
if (do_fill_outer) {
/*
* 需要为所有外部元组生成左连接元组,包括我们刚刚获取的元组。
* 我们设置 MatchedOuter = false,以强制在推进外部之前在 ENDINNER 状态下发出第一个元组。
*/
node->mj_JoinState = EXEC_MJ_ENDINNER;
node->mj_MatchedOuter = false;
break;
}
/*
* 如果 MergeJoin 的一侧返回 0 元组并且不需要生成具有空值的虚假连接元组,
* 我们应该更早地在 MergeJoin 下去初始化消费者。
* 注意我们不能在 predpush 内部进行提前的去初始化。
*/
if (((PlanState*)node) != NULL && !CheckParamWalker((PlanState*)node)) {
ExecEarlyDeinitConsumer((PlanState*)node);
}
/* Otherwise we're done. */
goto done;
default:
break;
}
break;
/*
* EXEC_MJ_JOINTUPLES 表示我们有两个满足合并条件的元组,所以我们将它们连接起来,
* 然后继续获取下一个内部元组(EXEC_MJ_NEXTINNER)。
*/
case EXEC_MJ_JOINTUPLES:
MJ_printf("ExecMergeJoin: EXEC_MJ_JOINTUPLESn");
/*
* 设置下一个状态机状态。如果我们返回了这个连接元组,或者只是继续执行状态机,都会发生正确的事情。
*/
node->mj_JoinState = EXEC_MJ_NEXTINNER;
/*
* 检查额外的条件,以查看我们是否真的想要返回这个连接元组。如果不是,可以继续合并。
* 我们必须区分额外的 joinquals(必须通过以考虑元组对于外连接逻辑是“匹配的”)和其他quals
* (在我们实际返回元组之前必须通过)。
*
* 我们不在这里使用 ResetExprContext,假设我们在检查合并条件时刚刚使用了一个。
* 每个元组应该足够了。我们必须为 ExecQual 设置表达式上下文链接,以便使用这些元组。
*/
outer_tuple_slot = node->mj_OuterTupleSlot;
econtext->ecxt_outertuple = outer_tuple_slot;
inner_tuple_slot = node->mj_InnerTupleSlot;
econtext->ecxt_innertuple = inner_tuple_slot;
qual_result = (join_qual == NIL || ExecQual(join_qual, econtext, false));
MJ_DEBUG_QUAL(join_qual, qual_result);
if (qual_result) {
node->mj_MatchedOuter = true;
node->mj_MatchedInner = true;
/*
* 在反连接中,我们从不返回匹配的元组。
* JOIN_RIGHT_ANTI_FULL 不能创建 mergejoin 计划,所以我们在这里不考虑它。
*/
if (node->js.jointype == JOIN_ANTI || node->js.jointype == JOIN_LEFT_ANTI_FULL) {
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
break;
}
/*
* 在半连接中,我们会考虑返回第一次匹配,但之后我们就完成了这个外部元组的处理。
*/
if (node->js.jointype == JOIN_SEMI)
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
qual_result = (other_qual == NIL || ExecQual(other_qual, econtext, false));
MJ_DEBUG_QUAL(other_qual, qual_result);
if (qual_result) {
/*
* 资格鉴定成功。现在形成所需的投影元组,并返回包含它的槽。
*/
ExprDoneCond isDone;
MJ_printf("ExecMergeJoin: returning tuplen");
TupleTableSlot* result = ExecProject(node->js.ps.ps_ProjInfo, &isDone);
if (isDone != ExprEndResult) {
node->js.ps.ps_TupFromTlist = (isDone == ExprMultipleResult);
return result;
}
} else
InstrCountFiltered2(node, 1);
} else
InstrCountFiltered1(node, 1);
break;
/*
* EXEC_MJ_NEXTINNER 表示将内部扫描器前进到下一个元组。
* 如果元组不是 nil,然后我们继续测试它是否符合连接条件。
*
* 在前进之前,我们检查是否必须为此内部元组发出外连接填充元组。
*/
case EXEC_MJ_NEXTINNER:
MJ_printf("ExecMergeJoin: EXEC_MJ_NEXTINNERn");
if (do_fill_inner && !node->mj_MatchedInner) {
/*
* 为外部生成具有null的伪联接元组,
* 并在它通过非联接quals时返回它。
*/
node->mj_MatchedInner = true; /* do it only once */
TupleTableSlot* result = MJFillInner(node);
if (result != NULL)
return result;
}
/*
* 现在我们获取下一个内部元组(如果有的话)。
* 如果没有,则前进到下一个外部元组(它可能能够连接到先前标记的元组)。
*
* 注意:这里不能执行“extraMarks”,因为我们可能需要返回到先前标记的元组。
*/
inner_tuple_slot = ExecProcNode(inner_plan);
node->mj_InnerTupleSlot = inner_tuple_slot;
MJ_DEBUG_PROC_NODE(inner_tuple_slot);
node->mj_MatchedInner = false;
/* 计算联接值并检查不匹配性 */
switch (MJEvalInnerValues(node, inner_tuple_slot)) {
case MJEVAL_MATCHABLE:
/*
* 测试新的内部元组,看看它是否与外部元组匹配。
*
* 如果它们匹配,则将它们连接并转到下一个内部元组(EXEC_MJ_JOINTUPLES)。
*
* 如果它们不匹配,则前进到下一个外部元组。
*/
compare_result = MJCompare(node);
MJ_DEBUG_COMPARE(compare_result);
if (compare_result == 0)
node->mj_JoinState = EXEC_MJ_JOINTUPLES;
else {
Assert(compare_result < 0);
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
}
break;
case MJEVAL_NONMATCHABLE:
/*
* 该元组包含一个NULL,因此不能与任何外部元组匹配,
* 因此我们可以跳过比较,假定新元组大于当前外部元组。
*/
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
break;
case MJEVAL_ENDOFJOIN:
/*
* 没有更多的内部元组。然而,这可能只是内部计划的有效结束而不是物理结束,所以强制 mj_InnerTupleSlot 为 null,以确保我们不会获取更多的内部元组。
* (我们需要这个hack,因为我们没有过渡到内部计划被假定已用尽的状态。)
*/
node->mj_InnerTupleSlot = NULL;
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
break;
default:
break;
}
break;
/*
* EXEC_MJ_NEXTOUTER 表示
*
* outer inner
* 外部元组 - 5 5 - 标记的元组
* 5 5
* 6 6 - 内部元组
* 7 7
*
* 我们知道我们刚刚碰到了第一个大于当前外部元组的内部元组(或者可能是内部流的结束),
* 所以获取一个新的外部元组,然后继续测试它是否与标记的元组匹配(EXEC_MJ_TESTOUTER)。
*
* 在推进之前,我们检查是否必须为这个外部元组发出外连接填充元组。
*/
case EXEC_MJ_NEXTOUTER:
MJ_printf("ExecMergeJoin: EXEC_MJ_NEXTOUTERn");
if (do_fill_outer && !node->mj_MatchedOuter) {
/*
* 生成一个具有内部元组的空值的虚拟连接元组,如果通过非连接限定符,则返回它。
*/
node->mj_MatchedOuter = true; /* 只做一次 */
TupleTableSlot* result = MJFillOuter(node);
if (result != NULL)
return result;
}
/*
* 现在我们得到下一个外部元组,如果有的话
*/
outer_tuple_slot = ExecProcNode(outer_plan);
node->mj_OuterTupleSlot = outer_tuple_slot;
MJ_DEBUG_PROC_NODE(outer_tuple_slot);
node->mj_MatchedOuter = false;
/* 计算联接值并检查不匹配性 */
switch (MJEvalOuterValues(node)) {
case MJEVAL_MATCHABLE:
/* 根据标记的元组测试新元组 */
node->mj_JoinState = EXEC_MJ_TESTOUTER;
break;
case MJEVAL_NONMATCHABLE:
/* 无法匹配,所以获取下一个外部元组 */
node->mj_JoinState = EXEC_MJ_NEXTOUTER;
break;
case MJEVAL_ENDOFJOIN:
/* 不再有外部元组*/
MJ_printf("ExecMergeJoin: end of outer subplann");
inner_tuple_slot = node->mj_InnerTupleSlot;
if (do_fill_inner && !TupIsNull(inner_tuple_slot)) {
/*
* 需要为剩余的内部元组发出右联接元组。
*/
node->mj_JoinState = EXEC_MJ_ENDOUTER;
break;
}
/* 否则我们就结束。 */
goto done;
default:
break;
}
break;
/*
* 如果新的外部元组和标记的元组满足合并子句,
* 则我们知道在外部扫描中存在重复项,因此我们必须将内部扫描恢复到标记的元组,
* 然后继续将新的外部元组与内部元组连接。
*
* 这种情况是当
* outer inner
* 4 5 - 标记的元组
* outer tuple - 5 5
* new outer tuple - 5 5
* 6 8 - 内部元组
* 7 12
*
* 新的外部元组 == 标记的元组
*
* 如果外部元组未通过测试,则我们已经完成了标记的元组,
* 并且必须寻找与当前内部元组的匹配项。
* 因此,我们将继续跳过外部元组,直到 outer >= inner (EXEC_MJ_SKIP_TEST)。
*
* 这种情况是当
*
* outer inner
* 5 5 - 标记的元组
* outer tuple - 5 5
* new outer tuple - 6 8 - 内部元组
* 7 12
*
* 新的外部元组 > 标记的元组
*
*/
case EXEC_MJ_TESTOUTER:
MJ_printf("ExecMergeJoin: EXEC_MJ_TESTOUTERn");
/*
* 在这里,我们必须将外部元组与标记的内部元组进行比较。
* (我们可以忽略 MJEvalInnerValues 的结果,因为标记的内部元组肯定是可匹配的。)
*/
inner_tuple_slot = node->mj_MarkedTupleSlot;
(void)MJEvalInnerValues(node, inner_tuple_slot);
compare_result = MJCompare(node);
MJ_DEBUG_COMPARE(compare_result);
if (compare_result == 0) {
/*
* 合并子句匹配,所以现在我们将内部扫描位置还原为第一个标记,并继续将该元组(以及任何后续元组)与新外部元组进行连接。
*
* 注意:我们不需要担心 rescanned 内部元组的 MatchedInner 状态。
* 我们知道它们都将与这个新外部元组匹配,因此不会作为填充元组返回。
* 这仅在对右连接或全连接进行额外的 joinquals 时有效,因为我们要求额外的 joinquals 在这种情况下是常量。
* 否则,一些 rescanned 元组可能不符合额外的 joinquals,这就明显不会发生在常量为 true 的额外 join_qual 上,
* 而常量为 false 的情况则通过强制合并子句永不匹配来处理,因此我们永远不会到达这里。
*/
ExecRestrPos(inner_plan);
/*
* ExecRestrPos 可能会给我们返回一个新的 Slot,但由于它没有这样做,所以使用标记的 Slot。
* (不能假定先前返回的 mj_InnerTupleSlot 包含所需的元组。)
*/
node->mj_InnerTupleSlot = inner_tuple_slot;
/* 我们不需要再次执行MJEvalInnerValues */
node->mj_JoinState = EXEC_MJ_JOINTUPLES;
} else {
/* ----------------
* 如果新的外部元组与标记的内部元组不匹配,
* 则我们有一种情况,如下所示:
*
* 外部 内部
* 4 4 - 标记的元组
* 新外部 - 5 4
* 6 5 - 内部元组
* 7
*
* 这意味着所有随后的外部元组都将大于我们标记的内部元组。
* 因此,我们无需重新访问任何标记的元组,可以继续寻找与当前内部元组匹配的元组。
* 如果没有更多的内部元组,那么不可能再有更多的匹配。
* ----------------
*/
Assert(compare_result > 0);
inner_tuple_slot = node->mj_InnerTupleSlot;
/* 重新加载当前内部的比较数据 */
switch (MJEvalInnerValues(node, inner_tuple_slot)) {
case MJEVAL_MATCHABLE:
/* 继续将其与当前外部进行比较 */
node->mj_JoinState = EXEC_MJ_SKIP_TEST;
break;
case MJEVAL_NONMATCHABLE:
/*
* 当前内部元组不可能与任何外部元组匹配;
* 最好前进内部扫描而不是外部。
*/
node->mj_JoinState = EXEC_MJ_SKIPINNER_ADVANCE;
break;
case MJEVAL_ENDOFJOIN:
/* 不再有内部元组 */
if (do_fill_outer) {
/*
* 需要为剩余的外部元组发出左联接元组。
*/
node->mj_JoinState = EXEC_MJ_ENDINNER;
break;
}
/* Otherwise we're done. */
goto done;
default:
break;
}
}
break;
/* ----------------------------------------------------------
* EXEC_MJ_SKIP 意味着比较元组,如果它们不匹配,
* 则跳过较小的那个。
*
* 例如:
*
* 外部 内部
* 5 5
* 5 5
* 外部元组 - 6 8 - 内部元组
* 7 12
* 8 14
*
* 我们必须推进外部扫描,直到找到外部的 8。
*
* 另一方面:
*
* 外部 内部
* 5 5
* 5 5
* 外部元组 - 12 8 - 内部元组
* 14 10
* 17 12
*
* 我们必须推进内部扫描,直到找到内部的 12。
* ----------------------------------------------------------
*/
case EXEC_MJ_SKIP_TEST:
MJ_printf("ExecMergeJoin: EXEC_MJ_SKIP_TESTn");
/*
* 在我们继续之前,请确保当前的元组不满足 merge_clauses。
* 如果满足条件,那么我们更新标记的元组位置并进行连接。
*/
compare_result = MJCompare(node);
MJ_DEBUG_COMPARE(compare_result);
if (compare_result == 0) {
ExecMarkPos(inner_plan);
if (node->mj_InnerTupleSlot == NULL) {
ereport(ERROR,
(errcode(ERRCODE_UNEXPECTED_NULL_VALUE),
errmsg("mj_InnerTupleSlot cannot be NULL")));
}
MarkInnerTuple(node->mj_InnerTupleSlot, node);
node->mj_JoinState = EXEC_MJ_JOINTUPLES;
} else if (compare_result < 0)
node->mj_JoinState = EXEC_MJ_SKIPOUTER_ADVANCE;
else
/* compare_result > 0 */
node->mj_JoinState = EXEC_MJ_SKIPINNER_ADVANCE;
break;
/*
* SKIPOUTER_ADVANCE:前进到已知不与任何内部元组连接的外部元组。
*
* 在前进之前,我们检查是否必须为此外部元组发出外连接填充元组。
*/
case EXEC_MJ_SKIPOUTER_ADVANCE:
MJ_printf("ExecMergeJoin: EXEC_MJ_SKIPOUTER_ADVANCEn");
if (do_fill_outer && !node->mj_MatchedOuter) {
/*
* 生成一个带有内部元组的空值的虚拟连接元组,并且如果它通过了非连接限定条件,则返回它。
*/
node->mj_MatchedOuter = true; /* do it only once */
TupleTableSlot* result = MJFillOuter(node);
if (result != NULL)
return result;
}
/*
* 现在我们得到下一个外部元组,如果有的话
*/
outer_tuple_slot = ExecProcNode(outer_plan);
node->mj_OuterTupleSlot = outer_tuple_slot;
MJ_DEBUG_PROC_NODE(outer_tuple_slot);
node->mj_MatchedOuter = false;
/* 计算联接值并检查不匹配性 */
switch (MJEvalOuterValues(node)) {
case MJEVAL_MATCHABLE:
/* 用新元组测试当前内部元组 */
node->mj_JoinState = EXEC_MJ_SKIP_TEST;
break;
case MJEVAL_NONMATCHABLE:
/* 无法匹配,所以获取下一个外部元组 */
node->mj_JoinState = EXEC_MJ_SKIPOUTER_ADVANCE;
break;
case MJEVAL_ENDOFJOIN:
/* 不再有外部元组 */
MJ_printf("ExecMergeJoin: end of outer subplann");
inner_tuple_slot = node->mj_InnerTupleSlot;
if (do_fill_inner && !TupIsNull(inner_tuple_slot)) {
/*
* 需要为剩余的内部元组发出右联接元组。
*/
node->mj_JoinState = EXEC_MJ_ENDOUTER;
break;
}
/* Otherwise we're done. */
goto done;
default:
break;
}
break;
/*
* SKIPINNER_ADVANCE:前进到已知不与任何外部元组连接的内部元组。
*
* 在前进之前,我们检查是否必须为此内部元组发出外连接填充元组。
*/
case EXEC_MJ_SKIPINNER_ADVANCE:
MJ_printf("ExecMergeJoin: EXEC_MJ_SKIPINNER_ADVANCEn");
if (do_fill_inner && !node->mj_MatchedInner) {
/*
* 生成一个带有外部元组的空值的虚拟连接元组,并且如果它通过了非连接限定条件,则返回它。
*/
node->mj_MatchedInner = true; /* do it only once */
TupleTableSlot* result = MJFillInner(node);
if (result != NULL)
return result;
}
/* 如果需要,在前进前做好标记 */
if (node->mj_ExtraMarks)
ExecMarkPos(inner_plan);
/*
* 现在我们得到下一个内部元组,如果有的话
*/
inner_tuple_slot = ExecProcNode(inner_plan);
node->mj_InnerTupleSlot = inner_tuple_slot;
MJ_DEBUG_PROC_NODE(inner_tuple_slot);
node->mj_MatchedInner = false;
/* 计算联接值并检查不匹配性 */
switch (MJEvalInnerValues(node, inner_tuple_slot)) {
case MJEVAL_MATCHABLE:
/* 继续将其与当前外部进行比较 */
node->mj_JoinState = EXEC_MJ_SKIP_TEST;
break;
case MJEVAL_NONMATCHABLE:
/*
* 当前内部元组不可能与任何外部元组匹配;
* 最好前进内部扫描而不是外部。
*/
node->mj_JoinState = EXEC_MJ_SKIPINNER_ADVANCE;
break;
case MJEVAL_ENDOFJOIN:
/* 不再有内部元组 */
MJ_printf("ExecMergeJoin: end of inner subplann");
outer_tuple_slot = node->mj_OuterTupleSlot;
if (do_fill_outer && !TupIsNull(outer_tuple_slot)) {
/*
* 需要为剩余的外部元组发出左联接元组
*/
node->mj_JoinState = EXEC_MJ_ENDINNER;
break;
}
/* Otherwise we're done. */
goto done;
default:
break;
}
break;
/*
* EXEC_MJ_ENDOUTER 意味着我们已经用完了外部元组,
* 但正在进行右连接/全连接,因此必须对任何剩余的未匹配内部元组进行空值填充。
*/
case EXEC_MJ_ENDOUTER:
MJ_printf("ExecMergeJoin: EXEC_MJ_ENDOUTERn");
Assert(do_fill_inner);
if (!node->mj_MatchedInner) {
/*
* 生成一个带有外部元组的空值的虚拟连接元组,并且如果它通过了非连接限定条件,则返回它。
*/
node->mj_MatchedInner = true; /* do it only once */
TupleTableSlot* result = MJFillInner(node);
if (result != NULL)
return result;
}
/* 如果需要,在前进前做好标记 */
if (node->mj_ExtraMarks)
ExecMarkPos(inner_plan);
/*
* 现在我们得到下一个内部元组,如果有的话
*/
inner_tuple_slot = ExecProcNode(inner_plan);
node->mj_InnerTupleSlot = inner_tuple_slot;
MJ_DEBUG_PROC_NODE(inner_tuple_slot);
node->mj_MatchedInner = false;
if (TupIsNull(inner_tuple_slot)) {
MJ_printf("ExecMergeJoin: end of inner subplann");
goto done;
}
/* 否则将保持ENDOUTER状态并处理下一个元组。 */
break;
/*
* EXEC_MJ_ENDINNER 意味着我们已经用完了内部元组,
* 但正在进行左连接/全连接,因此必须对任何剩余的未匹配外部元组进行空值填充。
*/
case EXEC_MJ_ENDINNER:
MJ_printf("ExecMergeJoin: EXEC_MJ_ENDINNERn");
Assert(do_fill_outer);
if (!node->mj_MatchedOuter) {
/*
* 生成一个带有内部元组的空值的虚拟连接元组,并且如果它通过了非连接限定条件,则返回它。
*/
node->mj_MatchedOuter = true; /* do it only once */
TupleTableSlot* result = MJFillOuter(node);
if (result != NULL)
return result;
}
/*
* 现在我们得到下一个外部元组,如果有的话
*/
outer_tuple_slot = ExecProcNode(outer_plan);
node->mj_OuterTupleSlot = outer_tuple_slot;
MJ_DEBUG_PROC_NODE(outer_tuple_slot);
node->mj_MatchedOuter = false;
if (TupIsNull(outer_tuple_slot)) {
MJ_printf("ExecMergeJoin: end of outer subplann");
goto done;
}
/* 否则将保持ENDINNER状态并处理下一个元组。 */
break;
/*
* 破坏状态值?
*/
default:
ereport(ERROR,
(errcode(ERRCODE_UNRECOGNIZED_NODE_TYPE),
errmsg("unrecognized mergejoin state: %d", (int)node->mj_JoinState)));
}
}
done:
ExecEarlyFree(innerPlanState(node));
ExecEarlyFree(outerPlanState(node));
EARLY_FREE_LOG(elog(LOG,
"Early Free: MergeJoin is done "
"at node %d, memory used %d MB.",
(node->js.ps.plan)->plan_node_id,
getSessionMemoryUsageMB()));
return NULL;
}
可以看到,ExecMergeJoin 函数的执行流程非常的长。我们还是按照状态来进行总结梳理一下吧:
- EXEC_MJ_INITIALIZE_OUTER:
- 初始状态,用于初始化外部计划。
- 检查是否存在外部元组,如果没有,连接结束。
- 如果存在外部元组,则切换到 EXEC_MJ_INITIALIZE_INNER 状态。
- EXEC_MJ_INITIALIZE_INNER:
- 初始化内部计划。
- 检查是否存在内部元组,如果没有,连接结束。
- 如果存在内部元组,则切换到 EXEC_MJ_NEXTOUTER 状态。
- EXEC_MJ_JOINTUPLES:
- 处理连接的元组,进行连接操作。
- 切换到 EXEC_MJ_NEXTINNER 状态,继续处理下一个内部元组。
- EXEC_MJ_NEXTINNER:
- 将内部扫描器前进到下一个元组。
- 检查是否需要为当前内部元组发出外连接填充元组。
- 根据内部元组是否匹配当前外部元组,切换到 EXEC_MJ_JOINTUPLES、EXEC_MJ_NEXTOUTER 或其他适当状态。
- EXEC_MJ_NEXTOUTER:
- 将外部扫描器前进到下一个元组。
- 检查是否需要为当前外部元组发出外连接填充元组。
- 根据外部元组的值和匹配情况切换到 EXEC_MJ_TESTOUTER、EXEC_MJ_SKIPOUTER_ADVANCE或其他适当状态。
- EXEC_MJ_TESTOUTER:
- 在这个状态中,对比较外部元组和标记的内部元组。
- 根据比较结果,可能进行连接,也可能跳过外部或内部元组。
- 状态转换到 EXEC_MJ_JOINTUPLES、EXEC_MJ_SKIPOUTER_ADVANCE、EXEC_MJ_SKIPINNER_ADVANCE。
- EXEC_MJ_SKIP_TEST:
- 在这个状态中,比较元组并跳过较小的那个。
- 如果找到匹配的元组,则状态切换到 EXEC_MJ_JOINTUPLES。
- 否则,根据比较结果,跳过外部或内部元组,状态切换到 EXEC_MJ_SKIPOUTER_ADVANCE 或 EXEC_MJ_SKIPINNER_ADVANCE。
- EXEC_MJ_SKIPOUTER_ADVANCE:
- 跳过当前外部元组,前进到已知不与任何内部元组连接的外部元组。
- 检查是否需要为当前外部元组发出外连接填充元组。
- 根据外部元组的值和匹配情况切换到 EXEC_MJ_SKIP_TEST、EXEC_MJ_SKIPOUTER_ADVANCE、EXEC_MJ_ENDOUTER。
- EXEC_MJ_SKIPINNER_ADVANCE:
- 跳过当前内部元组,前进到已知不与任何外部元组连接的内部元组。
- 检查是否需要为当前内部元组发出外连接填充元组。
- 根据内部元组的值和匹配情况切换到 EXEC_MJ_SKIP_TEST、EXEC_MJ_SKIPINNER_ADVANCE、EXEC_MJ_ENDINNER。
- EXEC_MJ_ENDOUTER:
- 已经用完了外部元组,但正在进行右连接/全连接,因此对任何剩余的未匹配内部元组进行空值填充。
- 检查是否需要为当前内部元组发出外连接填充元组。
- EXEC_MJ_ENDINNER:
- 已经用完了内部元组,但正在进行左连接/全连接,因此对任何剩余的未匹配外部元组进行空值填充。
- 检查是否需要为当前外部元组发出外连接填充元组。
- 根据外部元组的值和匹配情况切换到 EXEC_MJ_SKIP_TEST、EXEC_MJ_SKIPOUTER_ADVANCE、EXEC_MJ_ENDINNER。
状态转移图如下所示:
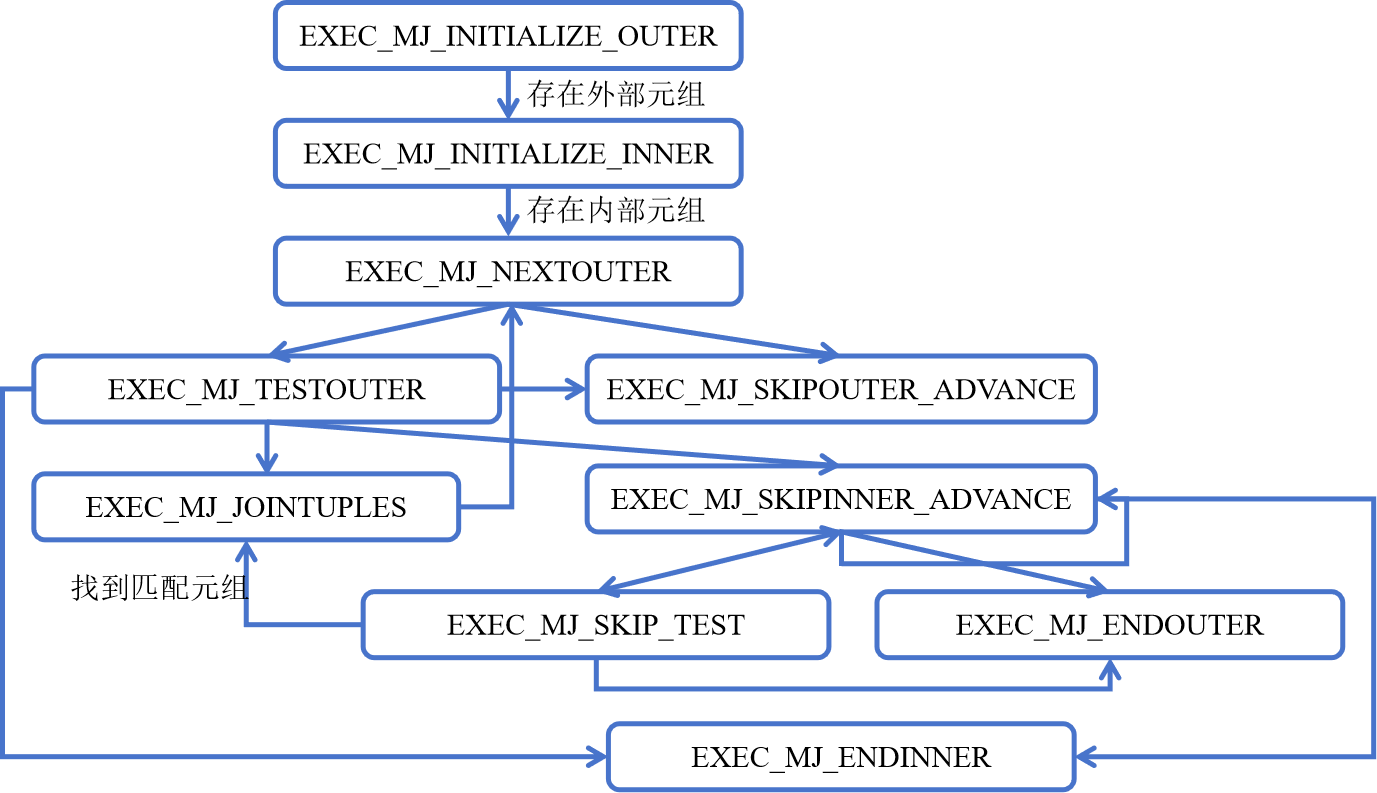
本文所用案例中的状态转移情况如下所示:
1. EXEC_MJ_INITIALIZE_OUTER
MJEVAL_MATCHABLE
2. EXEC_MJ_INITIALIZE_INNER
MJEVAL_MATCHABLE
3. EXEC_MJ_SKIP_TEST
4. EXEC_MJ_JOINTUPLES
5. EXEC_MJ_NEXTINNER
MergeJoinState 结构体
MergeJoinState 结构体表示关系数据库查询执行计划中合并连接操作的状态。结构体包含了合并连接操作所需的各种信息,例如连接条件、当前状态、标记的元组等。这个结构体是 MergeJoin 操作实现的一部分,它存储了该操作执行时的状态和上下文信息。结构体源码如下所示:(路径:src/include/nodes/execnodes.h)
typedef struct MergeJoinState {
JoinState js; /* 合并连接状态结构的基类,包含与不同类型连接节点共有的信息 */
int mj_NumClauses; /* 合并连接条件的数量 */
MergeJoinClause mj_Clauses; /* 由MergeJoinClause结构组成的数组,表示合并连接的条件 */
int mj_JoinState; /* 表示合并连接操作的当前状态的整数值 */
bool mj_ExtraMarks; /* 一个布尔标志,指示是否需要额外的标记 */
bool mj_ConstFalseJoin; /* 一个布尔标志,指示合并连接是否表示常量假连接 */
bool mj_FillOuter; /* 一个布尔标志,指示是否为外连接填充外部元组 */
bool mj_FillInner; /* 一个布尔标志,指示是否为外连接填充内部元组 */
bool mj_MatchedOuter; /* 一个布尔标志,指示当前外部元组是否已匹配 */
bool mj_MatchedInner; /* 一个布尔标志,指示当前内部元组是否已匹配 */
TupleTableSlot* mj_OuterTupleSlot; /* 指向表示当前外部元组的TupleTableSlot的指针 */
TupleTableSlot* mj_InnerTupleSlot; /* 指向表示当前内部元组的TupleTableSlot的指针 */
TupleTableSlot* mj_MarkedTupleSlot; /* 指向表示标记元组的TupleTableSlot的指针,可能用于重新扫描操作 */
TupleTableSlot* mj_NullOuterTupleSlot; /* 指向表示空值外部元组的TupleTableSlot的指针 */
TupleTableSlot* mj_NullInnerTupleSlot; /* 指向表示空值内部元组的TupleTableSlot的指针 */
ExprContext* mj_OuterEContext; /* 指向外部关系表达式上下文的指针 */
ExprContext* mj_InnerEContext; /* 指向内部关系表达式上下文的指针 */
} MergeJoinState;
ExecEndMergeJoin 函数
ExecEndMergeJoin 函数用于结束合并连接节点的处理。首先,它释放了表达式上下文。接着,清空了元组表中的两个特定槽位,分别是结果元组槽位和标记的元组槽位。最后,关闭了合并连接节点的子计划。该函数负责释放相关的资源,完成了合并连接节点的清理工作。函数源码如下所示:(路径:src/gausskernel/runtime/executor/nodeMergejoin.cpp)
/*
* ExecEndMergeJoin
* 结束合并连接节点的处理,释放通过C例程分配的存储空间。
*/
void ExecEndMergeJoin(MergeJoinState* node)
{
MJ1_printf("ExecEndMergeJoin: %sn", "结束节点处理");
/*
* 释放表达式上下文
*/
ExecFreeExprContext(&node->js.ps);
/*
* 清空元组表
*/
(void)ExecClearTuple(node->js.ps.ps_ResultTupleSlot);
(void)ExecClearTuple(node->mj_MarkedTupleSlot);
/*
* 关闭子计划
*/
ExecEndNode(innerPlanState(node));
ExecEndNode(outerPlanState(node));
MJ1_printf("ExecEndMergeJoin: %sn", "节点处理结束");
}
总结
Merge Join 算子优势和限制:
- 有序关系: Merge Join 的主要优势在于对有序关系的高效处理。由于输入已排序,不需要回溯,整个算法的时间复杂度为 O(N+M),其中 N 和 M 分别是两个输入关系的大小。
- 对内存友好: Merge Join 不需要额外的内存结构,对内存友好。相比于 Hash Join,适用于大规模数据集。
- 有序性要求: 由于需要有序输入,如果关系没有按连接属性排序,则需要进行排序操作,增加了初始开销。
- 只适用于等值连接: Merge Join 只能处理等值连接,无法处理其他类型的连接操作。
总体而言,Merge Join 是一种高效的连接算法,特别适用于连接有序关系的场景。在数据库查询优化中,优化器会根据具体情况选择不同的连接算法,包括 Merge Join、Hash Join 等。
原文地址:https://blog.csdn.net/qq_43899283/article/details/134599172
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_3168.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!