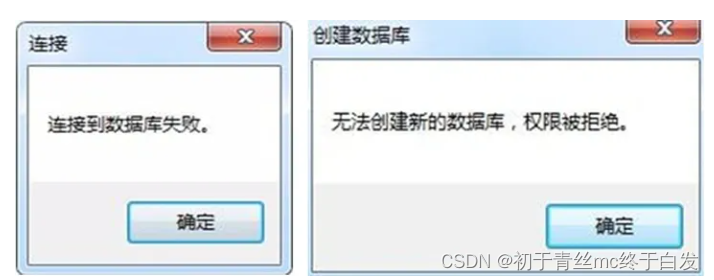
本系统使用python编写,基于Dango框架;算法为协同过滤,有基于用户和基于物品两种,终端运行窗口可显示用户相似度和音乐相似度;有现成数据集,其中有近千首音乐数据,使用sqlite数据库,系统所有信息存放在数据库中,可使用navicat与本数据库连接;有登录,注册功能,还可选择标签,歌曲可实现播放,评分,收藏,评论并实时展示;有歌曲,歌手搜索功能;有个人信息页面,展示收藏,评论,评分信息,并可实现删除操作;有后台管理功能。
代码有具体注释,有具体项目说明书,可部署
摘 要
本次课程设计的主要内容为音乐推荐系统。在日常的生活中,我们要进行购物、看电影或听音乐。在购买物品或者休闲娱乐的过程中,我们更偏向于使用能够为我们推荐心仪的产品,或者能够推荐更符合我们喜好的娱乐项目的网站或app。在进入一个网站后,首页能够展示的商品数量极其有限,给用户推荐他们可能喜欢的商品就成了一件非常重要的事情。因此,我们能够使用许多不同的方式来搜集兴趣偏好。有时候,这些数据可能来自人们购买的商品,以及这些商品关联的评价信息。我们可以利用一组或几组算法从中挖掘,建立推荐系统。
在本次的课程设计中,我们要着重解决为用户推荐音乐的问题。采用Django技术实现页面的编写,利用Sqlite和Navicat对大量的数据进行初始化,并实现与PyCharm的连接,前端用bootstrap做渲染利用协同过滤算法及K-近邻算法实现对于电影的推荐。具体用到的软件有:Pycharm、Sqlite、Navicat等。
使用Django开发框架,以Pycharm作为开发和运行测试环境:
1)准备数据:推荐使用公开数据集(可以自己找或爬取数据集);训练数据集要求用户-物品数量级在10000以上。图片素材可以自己寻找。
2)预处理数据:对数据进行清洗加工、进行分词处理、相似度计算,选择合适的一种或多种算法(基于静态信息的推荐、基于用户特征的推荐、基于物品内容的推荐、基于协同过滤的推荐等);
3)设计架构:根据系统功能的模块,进行设计,给出需求分析、功能模块,画出用例图;
4)实现系统:准备环境、进行数据库、数据模型(对模型进行评估)、后端接口、前端界面的设计等;
7)写出实验周设计说明书(按格式要求,每人根据自己的工作写出说明书)。

图1.2 系统设计流程图
1.2 意义
个性化推荐技术是一种信息过滤的手段﹐可以挖掘用户的兴趣偏好,根据用户的兴趣向用户推荐感兴趣的信息﹐提供针对用户的个性化服务,解决了信息过载的问题。协同过滤算法是一种应用广泛的个性化推荐算法,能根据用户对项目的评价找出用户与用户之间以及音乐与音乐之间的相似性,从相似的用户或音乐中找到目标的最近邻居,根据最近邻居的信息作出推荐。
搭建一个基于协同过滤算法的音乐个性化推荐系统﹐能帮助用户挑选喜欢的音乐,节省用户听自己不喜欢的音乐的时间,提高用户的体验,同时还能提高用户和系统的粘着度。同时﹐用户能快速找到喜欢的音乐﹐也能减轻一个站点的网络负载。
随着互联网与移动终端的普及,网络上的音乐数量海量增加,用户对音乐个性化服务的需求日益旺盛。设计音乐个性化推荐系统,该系统能够挖掘用户信息﹑音乐信息间隐藏的关联性,从而发现用户的潜在兴趣,将用户可能感兴趣的音乐推荐给用户。便利的互联网和日益普及的移动终端极大地提高了人们的生活质量。网络上供用户聆听的音乐数量庞大,类型多样,从海量的音乐资源中找到一部自己喜欢的音乐变的越来越困难,海量音乐信息的利用率很低。
1.3 设计要求
理解Python主流框架的架构思想,了解Python解析器底层原理,熟悉和掌握基于PyCharm的开发环境及开发技术;
熟悉和掌握Python的常用库,如Numpy、Pandas、Jieba、Json等,熟练使用MySQL关系型数据库、MongoDB非关系型数据库,及简单的xml语法规则,明确搭建推荐系统的一般步骤;
符合课题要求,实现相应功能;
注意程序的实用性、可读性。
1.4 工作要求
在题目设计初期,需要完成基本的题目分析,并进行思路规划;在题目完成中期,需要具体设计相关算法,进一步优化,并编写程序实现,学习并且制作可视化界面;在题目完成后期,需要对代码进行进一步的整合和规范化,并完成课程设计说明书文档。
2 需求分析
用户注册/登录/退出,存储音乐数据,存储用户和对应音乐数据,根据基于物品和用户的协同过滤算法等计算用户可能感兴趣的音乐,展示用户可能喜欢的音乐,可以根据用户和某一部电影为您推荐可能最符合您喜好的电影为您输出,还具有按类别显示音乐、显示热门音乐、最新音乐、音乐详情、播放音乐、歌手详情等功能。还可以为音乐进行评分,以便能为用户推荐更适合喜好的音乐。还可以对音乐进行评论、收藏,记录下用户与每首音乐的点点滴滴。最后,还要有后台管理功能,方便管理员对音乐进行增删改查,汇总各种数据,便于管理。
2.1 web前端界面
该系统需要实现用户的登录注册功能来实现的用户的管理和个性化推荐。登录时,用户需输入自己的账号和密码,该信息存储在数据库中,当用户输入完成点击登录按钮时,系统会传回用户所输的数据也数据库中的数据进行比对,比对成功则登录成功。
注册时用户输入自己的数据,系统传回数据库进行保存,供下次用户登录时进行比对。
主页面会展示按热度,发行时间等进行排序以及基于用户推荐的音乐,当用户点击某首音乐查看音乐详情时,会展示该音乐的歌名,歌手,发行时间,专辑名称等,并可实现播放,收藏,评分,评论等功能;标签页面可实现对音乐的分类,当用户点击某一标签时,会展示对应种类的所有音乐。
个人信息页面会展示用户的基本信息包括用户名,邮箱,我的收藏,我的评论,我的评分,并可对用户信息进行编辑,可实现修改密码,账号,邮箱,以及账号重置等功能。
系统数据将存储在sqlite数据库中可实现增删改查功能,满足系统对数据的需求。
2.3 推荐算法
基于物品的推荐算法需计算其他音乐与当前音乐的相似度,并按相似度由高到低进行排列展示。
2.3.2 基于用户推荐
基于用户的推荐算法需计算当前用户与其他用户的皮尔逊相关系数,并按系数由高到低进行排列,并展示当前用户没有听过的音乐。
3 概要设计
3.1数据库设计
在本次课程设计——音乐推荐系统中,数据库非常重要。如何将数据导入数据库及将数据库与前端连接,能够在页面中展示出信息,并能将页面输入的信息导入数据库中,都是很难实现的问题,这其中,数据库的设计显得尤为重要。
在音乐推荐系统中,获取到的数据有:用户信息、用户评分与评论信息、音乐信息、音乐收藏,还有音乐标签分类的这几种表格。其中它们包含的信息有:

图3.1 数据库概念图
3.2 推荐算法设计
内容过滤根据信息资源与用户兴趣的相似性来推荐商品,通过计算用户兴趣模型和商品特征向量之间的向量相似性,主动将相似度高的商品发送给该模型的客户。由于每个客户都独立操作,拥有独立的特征向量,不需要考虑别的用户的兴趣,不存在评价级别多少的问题,能推荐新的项目或者是冷门的项目。这些优点使得基于内容过滤的推荐系统不受冷启动和稀疏问题的影响
算法流程
4.根据用户的历史记录,给用户推荐物品;
3.2.2 基于用户推荐
该算法利用用户之间的相似性来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。但有很难解决的两个问题,一个是稀疏性,即在系统使用初期由于系统资源还未获得足够多的评价,很难利用这些评价来发现相似的用户。另一个是可扩展性,随着系统用户和资源的增多,系统的性能会越来越差。
算法流程
2.算出用户/物品间的相似度;
3.选出最相似的前k个用户;
4.根据相似用户对物品的评分来预测目标用户对物品的评分;
5.去掉目标用户已经使用过的物品;
6.根据得分排名推荐前n个物品。
4.2 推荐算法设计
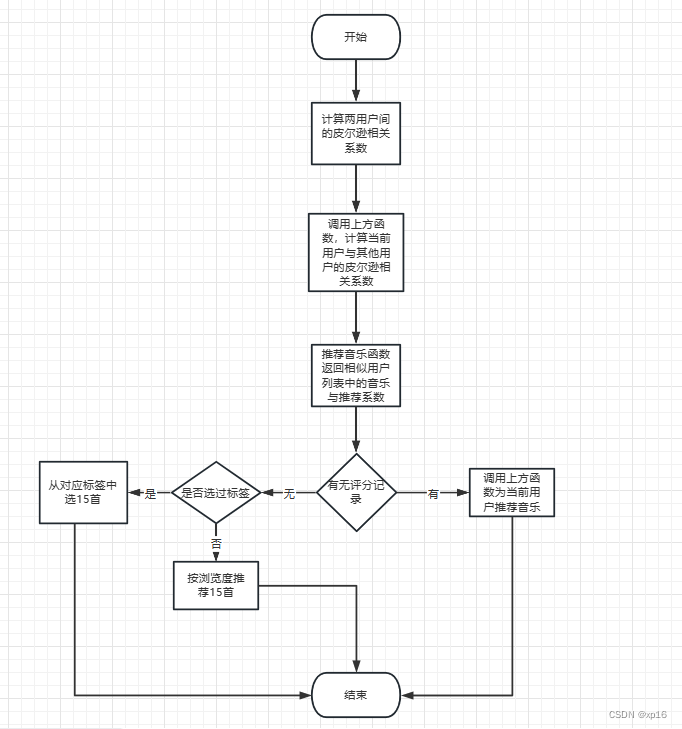
图4.1 基于用户推荐算法流程图
4.2.2 基于物品推荐

图4.3 基于物品推荐算法流程图
数据表:

图5.1 音乐信息表

图5.2 用户收藏表
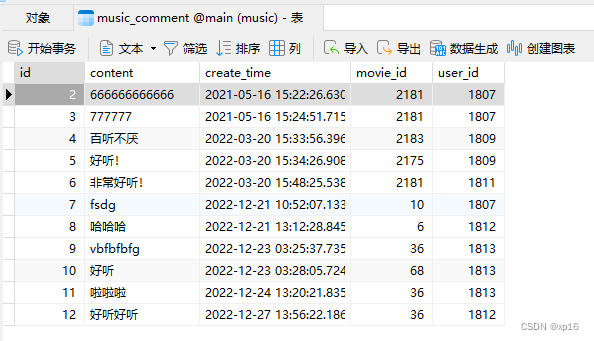
图5.4 评论表

图5.5 标签表


图5.7 音乐评分表
20221231_093715
原文地址:https://blog.csdn.net/weixin_52756379/article/details/128507190
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_32024.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!