1. 安装与介绍
1.1 Django框架的介绍
- 2005年发布,采用Python语言编写的开源web框架
- 早期的时候Django主做新闻和内容管理的
- 一个重量级的 Python Web框架,Django 配备了常用的大部分组件
- Django的用途
- Django的版本
- Django的官网
1.2 Django的安装
-
>>> import django >>> print(django.VERSION) (1, 11, 8, 'final', 0) -
安装
- 在线安装
2. Django文件目录和文件介绍
2.1 创建项目的指令
- $ django-admin startproject 项目名称
- 如:
- $ django-admin startproject mysite1
- 运行
```shell
$ cd mysite1
$ python3 manage.py runserver
# 或
$ python3 manage.py runserver 5000 # 指定只能本机使用127.0.0.1的5000端口访问本机
```
2.2 Django项目的目录结构
$ django-admin startproject mysite1
$ tree mysite1/
mysite1/
├── manage.py
└── mysite1
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.py
1 directory, 5 files
2.2.1 manage.py
2.2.2 mysite1 项目包文件夹
2.2.3 __init__.py
2.2.4 settings.py
-
BASE_DIR-
用于绑定当前项目的绝对路径(动态计算出来的), 所有文件都可以依懒此路径
DEBUG
-
python3 manage.py runserver 0.0.0.0:5000# 指定网络设备所有主机都可以通过5000端口访问(需加ALLOWED_HOSTS = ['*'])INSTALLED_APPS
-
MIDDLEWARE
-
TEMPLATES
-
DATABASES
-
LANGUAGE_CODE
-
取值:
-
取值:
-
2.2.5 urls.py
2.2.6 views.py
3. URL介绍
-
作用:
-
说明:
-
https://www.djangoproject.com/download/
protocol :// hostname[:port] / path [?query][#fragment] -
如:
http://tts.tmooc.cn/video/showVideo?meuId=657421&version=AID201908#s -
说明:
4. 视图函数详解
4.1 FBV(Fuction base view)
用函数创建的视图
-
视图函数是用于接收一个浏览器请求并通过HttpResponse对象返回数据的函数。此函数可以接收浏览器请求并根据业务逻辑返回相应的内容给浏览器
-
def xxx_view(request[, 其它参数...]): return HttpResponse对象 -
参数:
-
示例:
4.2 CBV(Class base view)
如果平常的用FBV的话就需要匹配用if—elif的方式来匹配访问方式,这种方式往往显得很笨拙
- FBV模式
# FBV模式
def home(request):
if request.method == 'GET':
xxxx
elif request.method == 'POST':
XXX
from django.urls import path,include
from index import views
urlpatterns = [
# FBV模式
path('',views.index_home)
]
- CBV模式
views.py
# CBV模式
class Index_home(View):
def get(self,request):
return HttpResponse('这是get主页')
def post(self,request):
return HttpResponse('这是post主页')
urls.py
from django.urls import path,include
from index import views
urlpatterns = [
# FBV模式
# path('',views.index_home)
# CBV模式
path('',views.Index_home.as_view())
]
5. 路由配置详解
from django.urls import path
from . import views
# path函数的第一个参数为路由地址名,第二个参数为views的函数名
urlpatterns = [
path('',views.main_view), # 匹配127.0.0.1
path('page/1',views.page1_view), # 127.0.0.1/page/1
path('page/2',views.page1_view), # 127.0.0.1/page/2
]
5.1 path函数详解
-
函数
path()具有四个参数,两个必须参数:route和view,两个可选参数:kwargs和name。现在,是时候来研究这些参数的`含义了。 -
route是一个匹配 URL 的准则(类似正则表达式)。当 Django 响应一个请求时,它会从urlpatterns的第一项开始,按顺序依次匹配列表中的项,直到找到匹配的项。这些准则不会匹配 GET 和 POST 参数或域名。例如,URLconf 在处理请求
https://www.example.com/myapp/时,它会尝试匹配myapp/。处理请求https://www.example.com/myapp/?page=3时,也只会尝试匹配myapp/ -
view当 Django 找到了一个匹配的准则,就会调用这个特定的视图函数,并传入一个HttpRequest对象作为第一个参数,被“捕获”的参数以关键字参数的形式传入 -
name为你的 URL 取名能使你在 Django 的任意地方唯一地引用它,尤其是在模板中。这个有用的特性允许你只改一个文件就能全局地修改某个 URL 模式。
5.1.1 path转换器
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img–pxiZ6lVJ-1683969713205)(…/assets/image-20220308134517864_1646837814760_0.png)]
# 例子 匹配127.0.0.1/int/str/int 第一个参数为任意整型,第二个参数为任意字符型,第三个参数为任意整型 path('<int:a>/<str:sml>/<int:b>',views.cal_view), -
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YYmyKwne-1683969713206)(…/assets/image-20220308134802884_1646837839971_0.png)]
6. 响应和请求
6.1 HTTP请求
6.1.1 基础知识和概念
-
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
-
HTTP1.1 请求详述
序号 方法 描述 1 GET 请求指定的页面信息,并返回实体主体。 2 HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 5 DELETE 请求服务器删除指定的页面。 6 CONNECT HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 7 OPTIONS 允许客户端查看服务器的性能。 8 TRACE 回显服务器收到的请求,主要用于测试或诊断。
6.1.2 Django的 HttpRequest对象
- 是什么?
-
django的view.py的每个视图函数的形参里面都有一个request,这就是httpRequest对象,httpRequest有很多属性和方法供我们服务端使用,我们可以从中简单的得到客户端发来的请求信息
-
HttpRequest属性
- path:字符串,表示请求的路由信息
- path_info: URL字符串
- method:字符串,表示HTTP请求方法,常用值:‘GET’、‘POST’
- encoding:字符串,表示提交的数据的编码方式
- GET:QueryDict查询字典的对象,包含get请求方式的所有数据
- POST:QueryDict查询字典的对象,包含post请求方式的所有数据
- FILES:类似于字典的对象,包含所有的上传文件信息
- COOKIES:Python字典,包含所有的cookie,键和值都为字符串
- session:似于字典的对象,表示当前的会话,
- body: 字符串,请求体的内容(POST或PUT)
- environ: 字符串,客户端运行的环境变量信息
- scheme : 请求协议(‘http’/‘https’)
- request.get_full_path() : 请求的完整路径
- request.get_host() : 请求的主机
- request.META : 请求中的元数据(消息头)
6.2 HTTP 响应
6.2.1 基础知识和概念
6.2.2 Django的响应对象HttpResponse
- 是什么?
视图函数的返回的一个函数
HttpResponse详解
-
构造函数格式:
-
类型 作用 状态码 HttpResponseRedirect 重定响 301 HttpResponseNotModified 未修改 304 HttpResponseBadRequest 错误请求 400 HttpResponseNotFound 没有对应的资源 404 HttpResponseForbidden 请求被禁止 403 HttpResponseServerError 服务器错误 500
6.3 GET方式传参
-
服务器端接收参数
-
判断 request.method 的值判断请求方式是否是get请求
if request.method == 'GET': 处理GET请求时的业务逻辑 else: 处理其它请求的业务逻辑
-
-
练习:
-
练习:
6.4 POST方式
-
<form method='post' action="/login"> 姓名:<input type="text" name="username"> <input type='submit' value='登陆'> </form> -
服务器端接收参数
-
- 方法
request.POST['参数名'] # request.POST 绑定QueryDict request.POST.get('参数名','') request.POST.getlist('参数名')
7. Django的设计模式
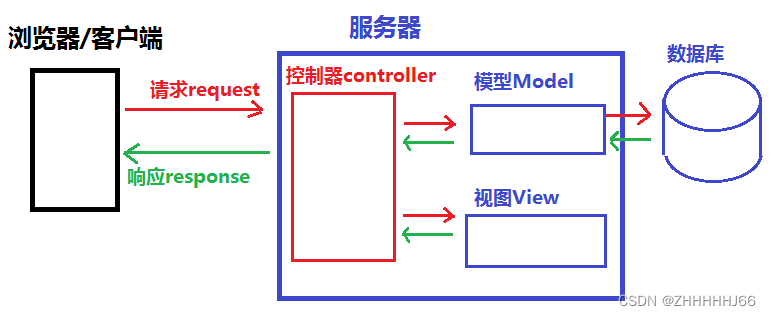
7.1 MVC 设计模式
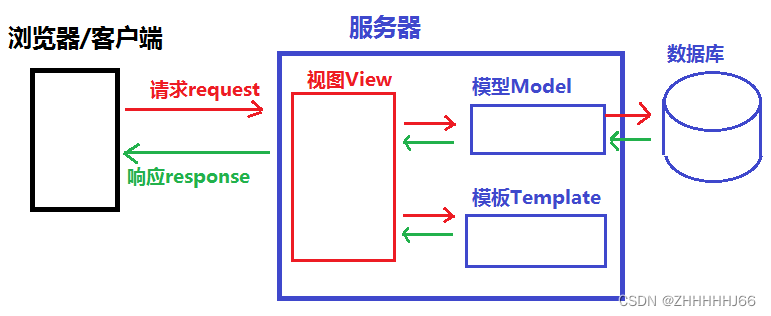
7.2 MTV 模式
MTV 代表 Model-Template-View(模型–模板-视图) 模式。这种模式用于应用程序的分层开发
8.Django的模板(前后端分离的话可以不看)
8.1模板的传参
-
t = loader.get_template('xxx.html') html = t.render(字典数据) return HttpResponse(html)return render(request,'xxx.html',字典数据)
8.2 模板的变量
-
-
ex: action=‘/mycal’ -> 提交地址为当前浏览器地址栏的ip+端口+ action, 即 http://127.0.0.1:8000/mycal
- +加 -减 *乘 /除 = 3
-
<form action='/mycal' method='POST'> <input type='text' name="x" value="1"> <select name='op'> <option value="add" > +加 </option> <option value="sub" > -减 </option> <option value="mul"> *乘 </option> <option value="div"> /除 </option> </select> <input type='text' name="y" value="2"> = <span>3</span> <div> <input type="submit" value='开始计算'> <div> </form>
8.3 模板的标签
-
作用
-
if 条件表达式里可以用的运算符 ==, !=, <, >, <=, >=, in, not in, is, is not, not、and、or
-
{% for 变量 in 可迭代对象 %} ... 循环语句 {% empty %} ... 可迭代对象无数据时填充的语句 {% endfor %}2. 内置变量 - forloop变量 描述 forloop.counter 循环的当前迭代(从1开始索引) forloop.counter0 循环的当前迭代(从0开始索引) forloop.revcounter 循环结束的迭代次数(从1开始索引) forloop.revcounter0 循环结束的迭代次数(从0开始索引) forloop.first 如果这是第一次通过循环,则为真 forloop.last 如果这是最后一次循环,则为真 forloop.parentloop 当嵌套循环,parentloop 表示外层循环
8.4 过滤器
-
作用
-
在变量输出时对变量的值进行处理
-
- 语法
-
https://docs.djangoproject.com/en/1.11/ref/templates/builtins/
-
8.5 模板的继承
-
模板的继承示例:
8.6 url 反向解析
-
url 函数的语法
-
url() 的
name关键字参数 -
练习:
写一个有四个自定义页面的网站,对应路由: / 主页 /page1 页面1 /page2 页面2 /page3 页面3 功能: 主页加 三个页面的连接分别跳转到一个页面,三个页面每个页面加入一个链接用于返回主页 -
实际用法

9.django中的静态文件
静态文件
-
静态文件配置
-
访问静态文件
10. django中的应用
创建应用app
应用的分布式路由
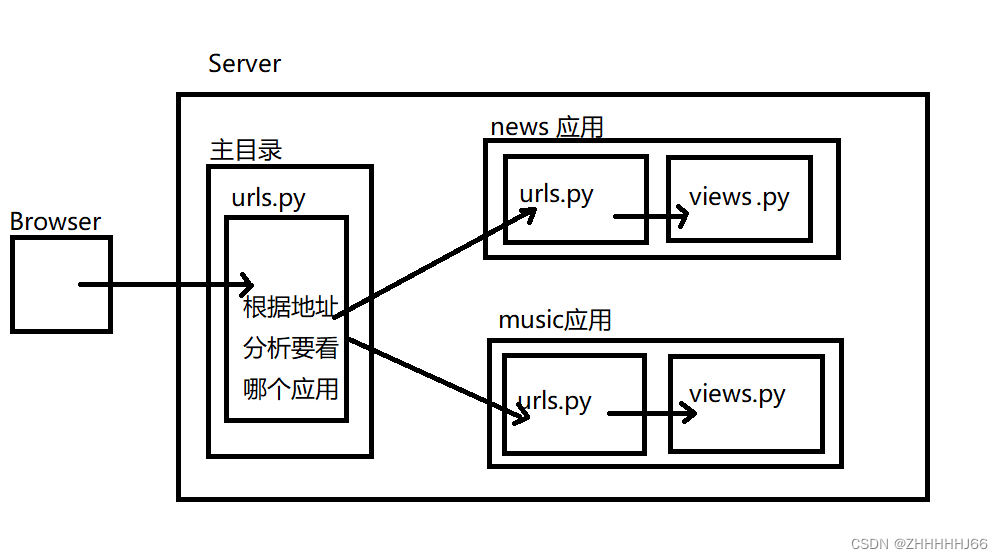
include 函数
-
作用:
-
函数格式
模块
app命字/url模块名.py文件件里必须有urlpatterns 列表
使用前需要使用from django.conf.urls import include导入此函数 -
练习:
1.创建四个应用 1.创建 index 应用,并注册 2.创建 sport 应用,并注册 3.创建 news 应用,并注册 4.创建 music 应用,并注册 2.创建分布式路由系统 主路由配置只做分发 每个应用中处理具体访问路径和视图 1. 127.0.0.1:8000/music/index 交给 music 应用中的 index_view() 函数处理 2. 127.0.0.1:8000/sport/index 交给 sport 应用中的 index_view() 函数处理 3. 127.0.0.1:8000/news/index 交给 news 应用中的 index_view() 处理处理
11.django的数据库操作
11.1 Django下配置使用 mysql 数据库
-
安装 pymysql包
-
创建 和 配置数据库
-
创建数据库
create database mywebdb default charset utf8 collate utf8_general_ci; -
数据库的配置
-
sqlite 数据库配置
# file: settings.py DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } -
mysql 数据库配置
DATABASES = { 'default' : { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'mywebdb', # 数据库名称,需要自己定义 'USER': 'root', 'PASSWORD': '123456', # 管理员密码 'HOST': '127.0.0.1', 'PORT': 3306, } }
-
-
关于数据为的SETTING设置
-
11.2 Django 的 ORM框架
基本介绍
- ORM(Object Relational Mapping)即对象关系映射,它是一种程序技术,它允许你使用类和对象对数据库进行操作,从而避免通过SQL语句操作数据库
- ORM框架的作用
- ORM 好处:
- ORM 缺点
- ORM 示意
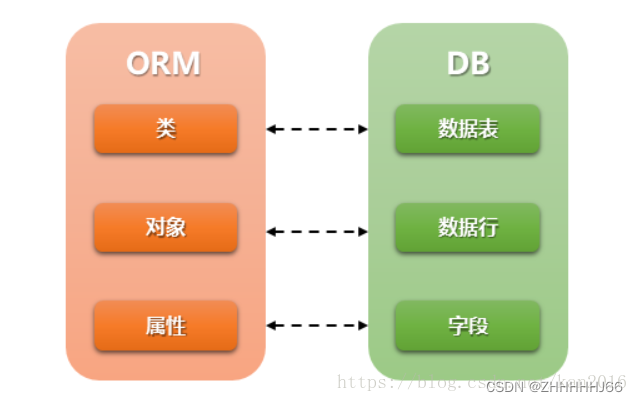
模型概念
- 模型是一个Python类,它是由django.db.models.Model派生出的子类。
- 一个模型类代表数据库中的一张数据表
- 模型类中每一个类属性都代表数据库中的一个字段。
- 模型是数据交互的接口,是表示和操作数据库的方法和方式
模型示例:
-
$ python3 manage.py startapp bookstore -
添加模型类并注册app
# file : bookstore/models.py from django.db import models class Book(models.Model): title = models.CharField("书名", max_length=50, default='') price = models.DecimalField('定价', max_digits=7, decimal_places=2, default=0.0) -
注册app
# file : setting.py INSTALLED_APPS = [ ... 'bookstore', ]
-
每次修改完模型类再对服务程序运行之前都需要做以上两步迁移操作。
-
编写模型类Models
Meta类
app_label如果模型是在 INSTALLED_APPS 中的应用程序之外定义的,它必须声明它属于哪个应用程序base_manager_name用于模型的 _base_manager 的管理器的属性名称,例如“对象”db_table用于模型的数据库表的名称- … 具体见(https://docs.djangoproject.com/zh-hans/2.2/ref/models/options/)
例如:
from django.db import models
class 模型类名(models.Model):
字段名 = models.字段类型(字段选项)
class Meta:
db_table = 'xxxx'
字段类型
-
DateField()
-
DateTimeField()
-
DecimalField()
-
FloatField()
-
EmailField()
-
IntegerField()
-
URLField()
-
ImageField()
-
TextField()
-
参考文档 https://docs.djangoproject.com/en/1.11/ref/models/fields/#field-types
-
字段选项FIELD_OPTIONS
-
文档参见:
11.3 数据库迁移的错误处理方法
-
当执行
$ python3 manage.py makemigrations出现如下迁移错误时的处理方法-
$ python3 manage.py makemigrations You are trying to change the nullable field 'title' on book to non-nullable without a default; we can't do that (the database needs something to populate existing rows). Please select a fix: 1) Provide a one-off default now (will be set on all existing rows with a null value for this column) 2) Ignore for now, and let me handle existing rows with NULL myself (e.g. because you added a RunPython or RunSQL operation to handle NULL values in a previous data migration) 3) Quit, and let me add a default in models.py Select an option: -
$ python3 manage.py makemigrations 您试图将图书上的可空字段“title”更改为非空字段(没有默认值);我们不能这样做(数据库需要填充现有行)。 请选择修复: 1)现在提供一次性默认值(将对所有现有行设置此列的空值) 2)暂时忽略,让我自己处理空值的现有行(例如,因为您在以前的数据迁移中添加了RunPython或RunSQL操作来处理空值) 3)退出,让我在models.py中添加一个默认值 选择一个选项: -
class Book(models.Model): title = models.CharField("书名", max_length=50, null=True)class Book(models.Model): title = models.CharField("书名", max_length=50) -
处理方法:
-
-
数据库的迁移文件混乱的解决办法
11.4 数据库的基本操作
管理器对象
-
每个继承自 models.Model 的模型类,都会有一个 objects 对象被同样继承下来。这个对象叫管理器对象
-
class MyModel(models.Model): ... MyModel.objects.create(...) # objects 是管理器对象
创建数据对象
-
Django 使用一种直观的方式把数据库表中的数据表示成Python 对象
Django shell 的使用
-
在Django Shell 下只能进行简单的操作,不能运行远程调式
-
启动方式:
$ python3 manage.py shell -
练习:
在 bookstore/models.py 应用中添加两个model类 1. Book - 图书 1. title - CharField 书名,非空,唯一 2. pub - CharField 出版社,字符串,非空 3. price - 图书定价,, 4. market_price - 图书零售价 2. Author - 作者 1. name - CharField 姓名,非空 2. age - IntegerField, 年龄,非空,缺省值为1 3. email - EmailField, 邮箱,允许为空
拓展:
settings.py里 APPEND_SLASH
案例:
url(r’^page1/$’, xx) ,访问浏览器时 地址栏输入 127.0.0.1:8000/page1 ,此时 django接到请求后
返回301【永久重定向】,并在响应头中指定重定向地址为 /page1/ ,从而出现自动补全 / 效果
若要关闭此功能,可将 APPEND_SLASH = False
执行 查!
tarena@tedu:~/aid1906/django/day03/mysite3$ ps aux|grep 'runserver'
tarena 13984 0.0 0.4 125980 39604 pts/0 S+ 15:39 0:00 python3 manage.py runserver
tarena 14914 1.2 0.5 202864 41312 pts/0 Sl+ 16:10 0:05 /usr/bin/python3 manage.py runserver
tarena 15056 0.0 0.0 21532 1156 pts/4 S+ 16:17 0:00 grep --color=auto runserv
#执行 干!
kill -9 13984 14914
11.5 CRUD增删改查
插入数据
MyModel.objects.create(obj1)
批量创建数据
MyModel.objects.bulk_create([obj1, obj2, obj3])
查询数据
-
数据库的查询需要使用管理器对象进行
-
通过 MyModel.objects 管理器方法调用查询接口
方法 说明 all() 查询全部记录,返回QuerySet查询对象 get() 查询符合条件的单一记录 filter() 查询符合条件的多条记录 exclude() 查询符合条件之外的全部记录 …
all()方法
-
方法: all()
-
作用: 查询MyModel实体中所有的数据
-
示例:
from bookstore import models books = models.Book.objects.all() for book in books: print("书名", book.title, '出版社:', book.pub)
-
在模型类中定义
def __str__(self):方法可以将自定义默认的字符串class Book(models.Model): title = ... def __str__(self): return "书名: %s, 出版社: %s, 定价: %s" % (self.title, self.pub, self.price)
查询返回指定列(字典表示)
-
方法: values(‘列1’, ‘列2’)
-
作用: 查询部分列的数据并返回
- select 列1,列2 from xxx
-
返回值: QuerySet
-
示例:
from bookstore import models books = models.Book.objects.values("title", "pub") for book in books: print("书名", book["title"], '出版社:', book['pub']) print("book=", book)
查询返回指定列(元组表示)
-
方法:values_list(‘列1’,‘列2’)
-
作用:
- 返回元组形式的查询结果
-
示例:
from bookstore import models books = models.Book.objects.values_list("title", "pub") for book in books: print("book=", book) # ('Python', '清华大学出版社')...
排序查询
-
方法:order_by
-
作用:
-
说明:
-
示例:
from bookstore import models books = models.Book.objects.order_by("-price") for book in books: print("书名:", book.title, '定价:', book.price)
字段查找
-
字段查询需要通过QuerySet的filter(), exclude() and get()的关键字参数指定。
-
非等值条件的构建,需要使用字段查询
-
示例:
# 查询作者中年龄大于30 Author.objects.filter(age__gt=30) # 对应 # SELECT .... WHERE AGE > 30;
查询谓词
-
__exact: 等值匹配Author.objects.filter(id__exact=1) # 等同于select * from author where id = 1 -
__contains: 包含指定值Author.objects.filter(name__contains='w') # 等同于 select * from author where name like '%w%' -
__startswith: 以 XXX 开始 -
__gt: 大于指定值Author.objects.filer(age__gt=50) # 等同于 select * from author where age > 50 -
__gte: 大于等于 -
__lt: 小于 -
__lte: 小于等于 -
- 示例
Author.objects.filter(country__in=['中国','日本','韩国']) # 等同于 select * from author where country in ('中国','日本','韩国') -
# 查找年龄在某一区间内的所有作者 Author.objects.filter(age__range=(35,50)) # 等同于 SELECT ... WHERE Author BETWEEN 35 and 50; -
详细内容参见: https://docs.djangoproject.com/en/1.11/ref/models/querysets/#field-lookups
-
不等的条件筛选
查询指定的一条数据
-
语法:
MyModel.objects.get(条件) -
作用:
- 返回满足条件的唯一一条数据
-
返回值:
- MyModel 对象
-
说明:
-
示例:
from bookstore import models book = models.Book.objects.get(id=1) print(book.title)
修改数据记录
修改单个实体的某些字段值的步骤:
- 查
- 通过 get() 得到要修改的实体对象
- 改
- 通过 对象.属性 的方式修改数据
- 保存
- 通过 对象.save() 保存数据
-
如:
from bookstore import models abook = models.Book.objects.get(id=10) abook.market_price = "10.5" abook.save()
通过 QuerySet 批量修改 对应的全部字段
-
如:
# 将 id大于3的所有图书价格定为0元 books = Book.objects.filter(id__gt=3) books.update(price=0) # 将所有书的零售价定为100元 books = Book.objects.all() books.update(market_price=100)
练习:修改图书得零售价
路由: /bookstore/mod/5
删除记录
-
删除单个对象
-
删除查询结果集
聚合查询
-
不带分组聚合
-
聚合函数:
- 定义模块:
django.db.models - 用法:
from django.db.models import * - 聚合函数:
- Sum, Avg, Count, Max, Min
- 定义模块:
-
语法:
-
返回结果:
- 由 结果变量名和值组成的字典
- 格式为:
- `{“结果变量名”: 值}
-
示例:
# 得到所有书的平均价格 from bookstore import models from django.db.models import Count result = models.Book.objects.aggregate(myAvg=Avg('price')) print("平均价格是:", result['myAvg']) print("result=", result) # {"myAvg": 58.2} # 得到数据表里有多少本书 from django.db.models import Count result = models.Book.objects.aggregate(mycnt=Count('title')) print("数据记录总个数是:", result['mycnt']) print("result=", result) # {"mycnt": 10}
-
分组聚合
-
分组聚合是指通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
-
语法:
- QuerySet.annotate(结果变量名=聚合函数(‘列’))
-
用法步骤:
-
示例:
def test_annotate(request): - from django.db.models import Count from . import models # 得到所有出版社的查询集合QuerySet pub_set = models.Book.objects.values('pub') # 根据出版社查询分组,出版社和Count的分组聚合查询集合 pub_count_set = pub_set.annotate(myCount=Count('pub')) # 返回查询集合 for item in pub_count_set: print("出版社:", item['pub'], "图书有:", item['myCount']) return HttpResponse('请查看服务器端控制台获取结果')
-
F对象
- 一个F对象代表数据库中某条记录的字段的信息
-
作用:
-
用法
- F对象在数据包 django.db.models 中,使用时需要先导入
from django.db.models import F
- F对象在数据包 django.db.models 中,使用时需要先导入
-
语法:
from django.db.models import F F('列名') -
说明:
-
示例1
models.Book.objects.all().update(market_price=F('market_price')+10) # 以s做法好于如下代码 books = models.Book.objects.all() for book in books: book.update(market_price=book.marget_price+10) book.save() -
示例2
from django.db.models import F from bookstore import models books = models.Book.objects.filter(market_price__gt=F('price')) for book in books: print(book.title, '定价:', book.price, '现价:', book.market_price)
Q对象 – Q()
-
如: 想找出定价低于20元 或 清华大学出版社的全部书,可以写成
models.Book.objects.filter(Q(price__lt=20)|Q(pub="清华大学出版社")) -
Q对象在 数据包 django.db.models 中。需要先导入再使用
from django.db.models import Q
-
作用
- 在条件中用来实现除 and(&) 以外的 or(|) 或 not(~) 操作
-
运算符:
- & 与操作
- | 或操作
- 〜 非操作
-
语法
from django.db.models import Q Q(条件1)|Q(条件2) # 条件1成立或条件2成立 Q(条件1)&Q(条件2) # 条件1和条件2同时成立 Q(条件1)&~Q(条件2) # 条件1成立且条件2不成立 ... -
示例
from django.db.models import Q # 查找清华大学出版社的书或价格低于50的书 models.Book.objects.filter(Q(market_price__lt=50) | Q(pub_house='清华大学出版社')) # 查找不是机械工业出版社的书且价格低于50的书 models.Book.objects.filter(Q(market_price__lt=50) & ~Q(pub_house='机械工业出版社'))
原生的数据库操作方法
-
使用MyModel.objects.raw()进行 数据库查询操作查询
-
示例
books = models.Book.objects.raw('select * from bookstore_book')
for book in books:
print(book)
“`
-
使用django中的游标cursor对数据库进行 增删改操作
-
在Django中可以使用 如UPDATE,DELETE等SQL语句对数据库进行操作。
-
在Django中使用上述非查询语句必须使用游标进行操作
-
使用步骤:
-
导入cursor所在的包
- Django中的游标cursor定义在 django.db.connection包中,使用前需要先导入
- 如:
from django.db import connection
-
用创建cursor类的构造函数创建cursor对象,再使用cursor对象,为保证在出现异常时能释放cursor资源,通常使用with语句进行创建操作
-
如:
from django.db import connection with connection.cursor() as cur: cur.execute('执行SQL语句')
-
-
-
12. admin 后台数据库管理
-
使用步骤:
自定义后台管理数据表
修改后台Models的展现形式
-
在用户自定义的模型类中可以重写
def __str__(self):方法解决显示问题,如:class Book(models.Model): ... def __str__(self): return "书名" + self.title
模型管理器类
-
作用:
-
说明:
-
模型管理器的使用方法:
数据库表管理
-
修改模型类字段的显示名字
- 练习:
13. 数据表关联关系映射
一对一映射
-
语法
class A(model.Model): ... class B(model.Model): 属性 = models.OneToOneField(A) -
用法示例
-
创建作家和作家妻子类
# file : xxxxxxxx/models.py from django.db import models class Author(models.Model): '''作家模型类''' name = models.CharField('作家', max_length=50) #wife 隐式定义 class Wife(models.Model): '''作家妻子模型类''' name = models.CharField("妻子", max_length=50) author = models.OneToOneField(Author) # 增加一对一属性 -
查询
-
创始一对一的数据记录
from . import models author1 = models.Author.objects.create(name='王老师') wife1 = models.Wife.objects.create(name='王夫人', author=author1) # 关联王老师 #wife1=models.wife.objects.create(name='王夫人', author_id=author1.id) author2 = models.Author.objects.create(name='小泽老师') # 一对一可以没有数据对应的数据 -
一对一数据的相互获取
-
正向查询
- 直接通过关联属性查询即可
# 通过 wife 找 author from . import models wife = models.Wife.objects.get(name='王夫人') print(wife.name, '的老公是', wife.author.name) -
反向查询
# 通过 author.wife 关联属性 找 wife,如果没有对应的wife则触发异常 author1 = models.Author.objects.get(name='王老师') print(author1.name, '的妻子是', author1.wife.name) author2 = models.Author.objects.get(name='小泽老师') try: print(author2.name, '的妻子是', author2.wife.name) except: print(author2.name, '还没有妻子')
-
-
-
作用:
-
练习:
- 创建一个Wife模型类,属性如下
- name
- age
- 在Wife类中增加一对一关联关系,引用 Author
- 同步回数据库并观察结果
- 创建一个Wife模型类,属性如下
一对多映射
-
用法语法
- 当一个A类对象可以关联多个B类对象时
class A(model.Model): ... class B(model.Model): 属性 = models.ForeignKey(多对一中"一"的模型类, ...) -
外键类ForeignKey
-
构造函数:
ForeignKey(to, on_delete, **options) -
常用参数:
- on_delete
- models.CASCADE 级联删除。 Django模拟SQL约束ON DELETE CASCADE的行为,并删除包含ForeignKey的对象。
- models.PROTECT 抛出ProtectedError 以阻止被引用对象的删除;
- SET_NULL 设置ForeignKey null;需要指定null=True
- SET_DEFAULT 将ForeignKey设置为其默认值;必须设置ForeignKey的默认值。用于房产继承
- … 其它参请参考文档 https://docs.djangoproject.com/en/1.11/ref/models/fields/#foreignkey ForeignKey部分
**options可以是常用的字段选项如:- null
- unique等
- …
- on_delete
-
-
示例
-
定义一对多类
# file: one2many/models.py from django.db import models class Publisher(models.Model): '''出版社''' name = models.CharField('名称', max_length=50, unique=True) class Book(models.Model): title = models.CharField('书名', max_length=50) publisher = models.ForeignKey(Publisher, null=True)
-
创建一对多的对象
# file: xxxxx/views.py from . import models pub1 = models.Publisher.objects.create(name='清华大学出版社') models.Book.objects.create(title='C++', publisher=pub1) models.Book.objects.create(title='Java', publisher=pub1) models.Book.objects.create(title='Python', publisher=pub1) pub2 = models.Publisher.objects.create(name='北京大学出版社') models.Book.objects.create(title='西游记', publisher=pub2) models.Book.objects.create(title='水浒', publisher=pub2) -
查询:
- 通过多查一
# 通过一本书找到对应的出版社 abook = models.Book.objects.get(id=1) print(abook.title, '的出版社是:', abook.publisher.name)- 通过一查多
# 通过出版社查询对应的书 pub1 = models.Publisher.objects.get(name='清华大学出版社') books = pub1.book_set.all() # 通过book_set 获取pub1对应的多个Book数据对象 # books = models.Book.objects.filter(publisher=pub1) # 也可以采用此方式获取 print("清华大学出版社的书有:") for book in books: print(book.title)
-
-
数据查询
多对多映射
-
语法
- 在关联的两个类中的任意一个类中,增加:
属性 = models.ManyToManyField(MyModel) -
示例
- 一个作者可以出版多本图书
- 一本图书可以被多名作者同时编写
class Author(models.Model): ... class Book(models.Model): ... authors = models.ManyToManyField(Author) -
数据查询
-
通过 Book 查询对应的所有的 Authors
book.authors.all() -> 获取 book 对应的所有的author的信息 book.authors.filter(age__gt=80) -> 获取book对应的作者中年龄大于80岁的作者的信息 -
通过 Author 查询对应的所有的Books
- Django会生成一个关联属性 book_set 用于表示对对应的book的查询对象相关操作
author.book_set.all() author.book_set.filter() author.book_set.create(...) # 创建新书并联作用author author.book_set.add(book) # 添加已有的书为当前作者author author.book_set.clear() # 删除author所有并联的书
-
-
示例:
- 多对多模型
class Author(models.Model): '''作家模型类''' name = models.CharField('作家', max_length=50) def __str__(self): return self.name class Book(models.Model): title = models.CharField('书名', max_length=50) author = models.ManyToManyField(Author) def __str__(self): return self.title- 多对多视图操作
from django.http import HttpResponse from . import models def many2many_init(request): # 创建两人个作者 author1 = models.Author.objects.create(name='吕泽') author2 = models.Author.objects.create(name='王老师') # 吕择和王老师同时写了一本Python book11 = author1.book_set.create(title="Python") author2.book_set.add(book11) # # 王老师还写了两本书 book21 = author2.book_set.create(title="C") # 创建一本新书"C" book22 = author2.book_set.create(title="C++") # 创建一本新书"C++" return HttpResponse("初始化成功") def show_many2many(request): authors = models.Author.objects.all() for auth in authors: print("作者:", auth.name, '发出版了', auth.book_set.count(), '本书: ') for book in books: print(' ', book.title) print("----显示书和作者的关系----") books = models.Book.objects.all() for book in books: auths = book.author.all() print(book.title, '的作者是:', '、'.join([str(x.name) for x in auths])) return HttpResponse("显示成功,请查看服务器端控制台终端")- 多对多最终的SQL结果
mysql> select * from many2many_author; +----+-----------+ | id | name | +----+-----------+ | 11 | 吕泽 | | 12 | 王老师 | +----+-----------+ 2 rows in set (0.00 sec) mysql> select * from many2many_book; +----+--------+ | id | title | +----+--------+ | 13 | Python | | 14 | C | | 15 | C++ | +----+--------+ 3 rows in set (0.00 sec) mysql> select * from many2many_book_author; +----+---------+-----------+ | id | book_id | author_id | +----+---------+-----------+ | 17 | 13 | 11 | | 20 | 13 | 12 | | 18 | 14 | 12 | | 19 | 15 | 12 | +----+---------+-----------+ 4 rows in set (0.00 sec)
14. cookies 和 session
cookies
-
在Django 服务器端来设置 设置浏览器的COOKIE 必须通过 HttpResponse 对象来完成
-
HttpResponse 关于COOKIE的方法
-
Django中的cookies
-
使用 响应对象HttpResponse 等 将cookie保存进客户端
-
方法1
from django.http import HttpResponse resp = HttpResponse() resp.set_cookie('cookies名', cookies值, 超期时间)- 如:
resp = HttpResponse() resp.set_cookie('myvar', "weimz", 超期时间) -
方法二, 使用render对象
from django.shortcuts import render resp = render(request,'xxx.html',locals()) resp.set_cookie('cookies名', cookies值, 超期时间)
-
-
-
cookies 示例
-
以下示例均在视图函数中调用
-
添加cookie
# 为浏览器添加键为 my_var1,值为123,过期时间为1个小时的cookie responds = HttpResponse("已添加 my_var1,值为123") responds.set_cookie('my_var1', 123, 3600) return responds -
修改cookie
# 为浏览器添加键为 my_var1,修改值为456,过期时间为2个小时的cookie responds = HttpResponse("已修改 my_var1,值为456") responds.set_cookie('my_var1', 456, 3600*2) return responds -
删除cookie
# 删除浏览器键为 my_var1的cookie responds = HttpResponse("已删除 my_var1") responds.delete_cookie('my_var1') return responds -
获取cookie
# 获取浏览器中 my_var变量对应的值 value = request.COOKIES.get('my_var1', '没有值!') print("cookie my_var1 = ", value) return HttpResponse("my_var1:" + value)
-
-
综合练习:

session 会话控制
-
session的起源
-
实现方式
-
Django启用Session
-
session的基本操作:
- session对于象是一个在似于字典的SessionStore类型的对象, 可以用类拟于字典的方式进行操作
- session 只能够存储能够序列化的数据,如字典,列表等。
- 保存 session 的值到服务器
request.session['KEY'] = VALUE
- 获取session的值
VALUE = request.session['KEY']VALUE = request.session.get('KEY', 缺省值)
-
注: 当使用session时需要迁移数据库,否则会出现错误
15. 网络云笔记项目
数据库设计
-
模型类
-
用户模型类
class User(models.Model): username = models.CharField("用户名", max_length=30, unique=True) password = models.CharField("密码", max_length=30) create_time = models.DateTimeField('创建时间', auto_now_add=True) def __str__(self): return "用户" + self.username -
笔记模型类
from django.db import models from user.models import User class Note(models.Model): title = models.CharField('标题', max_length=100) content = models.TextField('内容') create_time = models.DateTimeField('创建时间', auto_now_add=True) mod_time = models.DateTimeField('修改时间', auto_now=True) user = models.ForeignKey(User) ``` -
设计规范
-
路由正则 视图函数 模板位置 说明 /user/login def login_view(request): templates/user/login.html 用户登陆 /user/reg def reg_view(request): templates/user/register.html 用户注册 /user/logout def logout_view(request): 无 退出用户登陆 - 参考界面:
-
登陆界面

-
注册界面

-
- 参考界面:
-
路由正则 视图函数 模板位置 说明 / def index_view(request): templates/index/index.html 主页 - 参考界面
-
登陆前

-
登陆后
-
- 参考界面
-
云笔记设计规范
路由正则 视图函数 模板位置 说明 /note/ def list_view(request): templates/note/list_note.html 显示笔记列表功能 /note/add def add_view(request): templates/note/add_note.html 添加云笔记 /note/mod/(d+) def mod_view(request, id): templates/note/mod_note.html 修改之前云笔记 /note/del/(d+) def del_view(request, id): 无(返回列表页) 删除云笔记 /note/(d+) def show_view(request, id): templates/note/note.html 查看单个云笔记 - 参考界面
-
登陆界面

-
注册界面

-
添加新笔记界面

-
显示笔记列表
-
修改云笔记

-
主页
-
登陆前

-
登陆后

-
-
- 参考界面
16. 缓存
什么是缓存?
缓存是一类可以更快的读取数据的介质统称,也指其它可以加快数据读取的存储方式。一般用来存储临时数据,常用介质的是读取速度很快的内存
为什么使用缓存?
视图渲染有一定成本,对于低频变动的页面可以考虑使用缓存技术,减少实际渲染次数
from django.shortcuts import render
def index(request):
# 时间复杂度极高的渲染
book_list = Book.objects.filter() #-> 此处假设耗时2s
return render(request, 'index.html', locals())
优化思想
given a URL, try finding that page in the cache
if the page is in the cache:
return the cached page
else:
generate the page
save the generated page in the cache (for next time)
return the generated page
使用缓存场景:
1,博客列表页
Django中设置缓存
https://docs.djangoproject.com/en/1.11/topics/cache/
Django中提供多种缓存方式,如需使用需要在settings.py中进行配置
1,数据库缓存
Django可以将其缓存的数据存储在您的数据库中
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
'OPTIONS':{
'MAX_ENTRIES': 300, #当前最大缓存数
'CULL_FREQUENCY': 3 #删除频率 1/cull_frequency
}
}
}
创建缓存表
python3 manage.py createcachetable
2,文件系统缓存
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': '/var/tmp/django_cache',#这个是文件夹的路径
#'LOCATION': 'c:testcache',#windows下示例
}
}
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'unique-snowflake'
}
}
Django中使用缓存
- 在视图View中使用
- 在路由URL中使用
- 在模板中使用
在视图View中使用cache
from django.views.decorators.cache import cache_page
@cache_page(30) -> 单位s
def my_view(request):
...
在路由中使用
from django.views.decorators.cache import cache_page
urlpatterns = [
path('foo/', cache_page(60)(my_view)),
]
在模板中使用
{% load cache %}
{% cache 50 sidebar request.user.username %}
.. sidebar for logged in user ..
{% endcache %}
cache_key = sidebar + username
guoxiaonao访问 时 cache_key = sidebar + guoxiaonao
浏览器中的缓存
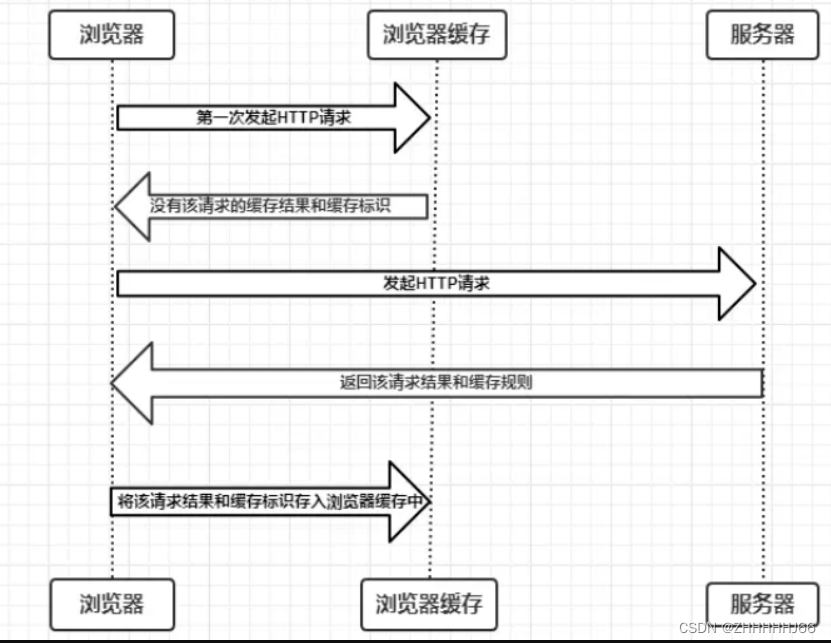
浏览器缓存分类:
强缓存
不会向服务器发送请求,直接从缓存中读取资源
1,Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点
Expires=max-age + 请求时间 UTC绝对时间
2019 10 27 xxx
Expires 是 HTTP/1 的产物,受限于本地时间,如果修改了本地时间,可能会造成缓存失效
2, Cache-Control
在HTTP/1.1中,Cache-Control主要用于控制网页缓存。比如当Cache-Control:max-age=120 代表请求创建时间后的120秒,缓存失效
横向对比 Expires VS Cache-Control
协商缓存
**协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程
1,Last-Modified和If-Modified-Since
第一次访问时,服务器会返回
Last-Modified: Fri, 22 Jul 2016 01:47:00 GMT
浏览器下次请求时 携带If-Modified-Since这个header , 该值为 Last-Modified
服务器接收请求后,对比结果,若资源未发生改变,则返回304, 否则返回200并将新资源返回给浏览器
2,ETag和If-None-Match
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成),只要资源有变化,Etag就会重新生成
流程同上
横向对比 Last-Modified VS ETag
17. 中间件 Middleware
-
中间件是 Django 请求/响应处理的钩子框架。它是一个轻量级的、低级的“插件”系统,用于全局改变 Django 的输入或输出。
-
每个中间件组件负责做一些特定的功能。例如,Django 包含一个中间件组件 AuthenticationMiddleware,它使用会话将用户与请求关联起来。
-
他的文档解释了中间件是如何工作的,如何激活中间件,以及如何编写自己的中间件。Django 具有一些内置的中间件,你可以直接使用。它们被记录在 built-in middleware reference 中。
-
中间件类:
- 中间件类须继承自
django.utils.deprecation.MiddlewareMixin类 - 中间件类须实现下列五个方法中的一个或多个:
def process_request(self, request):执行路由之前被调用,在每个请求上调用,返回None或HttpResponse对象def process_view(self, request, callback, callback_args, callback_kwargs):调用视图之前被调用,在每个请求上调用,返回None或HttpResponse对象def process_response(self, request, response):所有响应返回浏览器之前被调用,在每个请求上调用,返回HttpResponse对象def process_exception(self, request, exception):当处理过程中抛出异常时调用,返回一个HttpResponse对象def process_template_response(self, request, response):在视图刚好执行完毕之后被调用,在每个请求上调用,返回实现了render方法的响应对象
- 注: 中间件中的大多数方法在返回None时表示忽略当前操作进入下一项事件,当返回HttpResponese对象时表示此请求结束,直接返回给客户端
- 中间件类须继承自
-
编写中间件类:
# file : middleware/mymiddleware.py
from django.http import HttpResponse, Http404
from django.utils.deprecation import MiddlewareMixin
class MyMiddleWare(MiddlewareMixin):
def process_request(self, request):
print("中间件方法 process_request 被调用")
def process_view(self, request, callback, callback_args, callback_kwargs):
print("中间件方法 process_view 被调用")
def process_response(self, request, response):
print("中间件方法 process_response 被调用")
return response
def process_exception(self, request, exception):
print("中间件方法 process_exception 被调用")
def process_template_response(self, request, response):
print("中间件方法 process_template_response 被调用")
return response
- 注册中间件:
# file : settings.py
MIDDLEWARE = [
...
'middleware.mymiddleware.MyMiddleWare',
]

#单个中间件输出
MyMW process_request do---
MyMW process_views do ---
----this is test cache views ----
MyMW process_response do ---
#多个中间件时 输出
MyMW process_request do---
MyMW2 process_request do---
MyMW process_views do ---
MyMW2 process_views do ---
----this is test cache views ----
MyMW2 process_response do ---
MyMW process_response do ---
-
中间件的执行过程
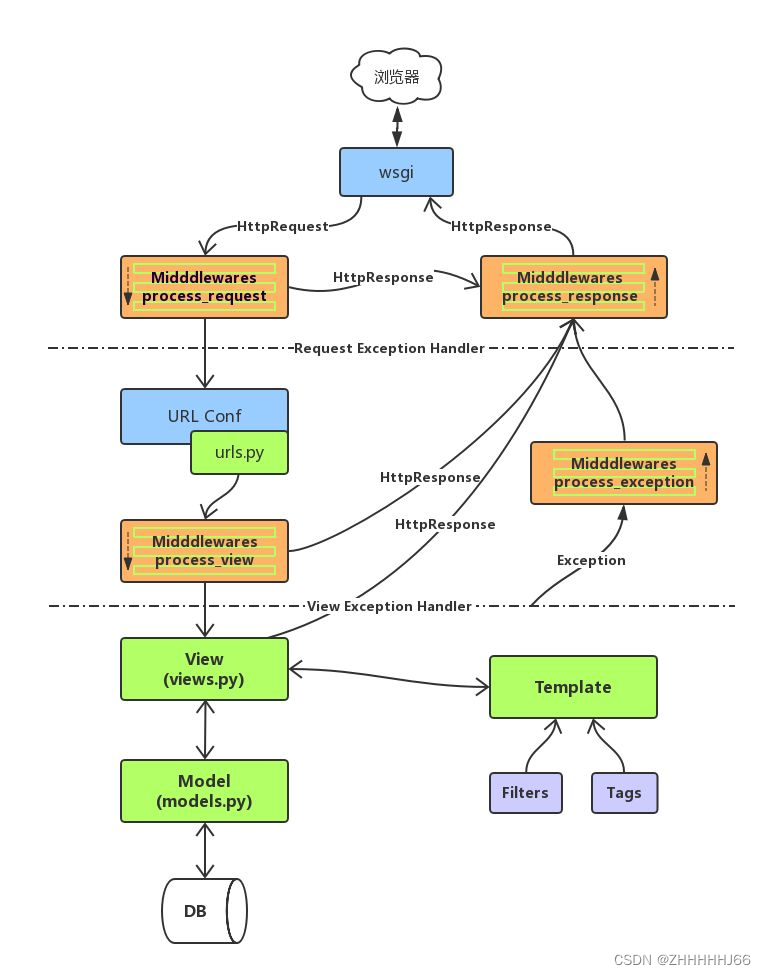
-
练习
-
提示:
-
答案:
from django.http import HttpResponse, Http404 from django.utils.deprecation import MiddlewareMixin import re class VisitLimit(MiddlewareMixin): '''此中间件限制一个IP地址对应的访问/user/login 的次数不能改过10次,超过后禁止使用''' visit_times = {} # 此字典用于记录客户端IP地址有访问次数 def process_request(self, request): ip_address = request.META['REMOTE_ADDR'] # 得到IP地址 if not re.match('^/test', request.path_info): return times = self.visit_times.get(ip_address, 0) print("IP:", ip_address, '已经访问过', times, '次!:', request.path_info) self.visit_times[ip_address] = times + 1 if times < 5: return return HttpResponse('你已经访问过' + str(times) + '次,您被禁止了')
跨站请求伪造保护 CSRF
18. 分页
- 分页是指在web页面有大量数据需要显示,为了阅读方便在每个页页中只显示部分数据。
- 好处:
- 方便阅读
- 减少数据提取量,减轻服务器压力。
- Django提供了Paginator类可以方便的实现分页功能
- Paginator类位于
django.core.paginator模块中。
Paginator对象
Page对象
-
Page对象属性
- object_list:当前页上所有数据对象的列表
- number:当前页的序号,从1开始
- paginator:当前page对象相关的Paginator对象
-
Page对象方法
-
说明:
- Page 对象是可迭代对象,可以用 for 语句来 访问当前页面中的每个对象
-
参考文档https://docs.djangoproject.com/en/1.11/topics/pagination/
-
分页示例:
- 视图函数
from django.core.paginator import Paginator def book(request): bks = models.Book.objects.all() paginator = Paginator(bks, 10) print('当前对象的总个数是:', paginator.count) print('当前对象的面码范围是:', paginator.page_range) print('总页数是:', paginator.num_pages) print('每页最大个数:', paginator.per_page) # /index?page=1 cur_page = request.GET.get('page', 1) # 得到默认的当前页 page = paginator.page(cur_page) return render(request, 'bookstore/book.html', locals())- 模板设计
<html> <head> <title>分页显示</title> </head> <body> {% for b in page %} <div>{{ b.title }}</div> {% endfor %} {# 分页功能 #} {# 上一页功能 #} {% if page.has_previous %} <a href="{% url 'book' %}?page={{ page.previous_page_number }}">上一页</a> {% else %} 上一页 {% endif %} {% for p in paginator.page_range %} {% if p == page.number %} {{ p }} {% else %} <a href="{% url 'book' %}?page={{ p }}">{{ p }}</a> {% endif %} {% endfor %} {#下一页功能#} {% if page.has_next %} <a href="{% url 'book' %}?page={{ page.next_page_number }}">下一页</a> {% else %} 下一页 {% endif %} 总页数: {{ page.len }} </body> </html>
19. 文件上传
-
文件上传必须为POST提交方式
-
表单
<form>中文件上传时必须有带有enctype="multipart/form-data"时才会包含文件内容数据。 -
表单中用
<input type="file" name="xxx">标签上传文件 -
上传文件的表单书写方式
<!-- file: index/templates/index/upload.html --> <html> <head> <meta charset="utf-8"> <title>文件上传</title> </head> <body> <h3>上传文件</h3> <form method="post" action="/upload" enctype="multipart/form-data"> <input type="file" name="myfile"/><br> <input type="submit" value="上传"> </form> </body> </html> -
在setting.py 中设置一个变量MEDIA_ROOT 用来记录上传文件的位置
# file : settings.py ... MEDIA_ROOT = os.path.join(BASE_DIR, 'static/files') -
在当前项目文件夹下创建
static/files文件夹$ mkdir -p static/files -
添加路由及对应的处理函数
# file urls.py urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^upload', views.upload_view) ] -
上传文件的视图处理函数
# file views.py from django.http import HttpResponse, Http404 from django.conf import settings import os def upload_view(request): if request.method == 'GET': return render(request, 'index/upload.html') elif request.method == "POST": a_file = request.FILES['myfile'] print("上传文件名是:", a_file.name) filename =os.path.join(settings.MEDIA_ROOT, a_file.name) with open(filename, 'wb') as f: data = a_file.file.read() f.write(data) return HttpResponse("接收文件:" + a_file.name + "成功") raise Http404
后端缓存:
1, 将视图函数最终结果 转存到其他介质里
【mysql表里,文件里, 内存里】
2,解决了 views重复计算问题 【有效降低视图层时间复杂度】
3,http 1.1 cache头 触发了 浏览器强缓存
浏览器缓存:
1,带有强缓存的响应头 的响应数据,存储自己的硬盘中或内存里
2,当强缓存有数据时,可以完全不给服务器发送请求,直接读取缓存内容 【减少 浏览器与服务器之间的请求次数】
20. Django中的用户认证 (使用Django认证系统)
-
作用:
- 添加普通用户和超级用户
- 修改密码
-
文档参见
-
User模型类
-
位置:
from django.contrib.auth.models import User -
默认user的基本属性有:
属性名 类型 是否必选 username 用户名 是 password 密码 是 email 邮箱 可选 first_name 名 last_name 姓 is_superuser 是否是管理员帐号(/admin) is_staff 是否可以访问admin管理界面 is_active 是否是活跃用户,默认True。一般不删除用户,而是将用户的is_active设为False。 last_login 上一次的登录时间 date_joined 用户创建的时间 -
数据库表现形式
mysql> use myauth;
mysql> desc auth_user;
+--------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| password | varchar(128) | NO | | NULL | |
| last_login | datetime(6) | YES | | NULL | |
| is_superuser | tinyint(1) | NO | | NULL | |
| username | varchar(150) | NO | UNI | NULL | |
| first_name | varchar(30) | NO | | NULL | |
| last_name | varchar(30) | NO | | NULL | |
| email | varchar(254) | NO | | NULL | |
| is_staff | tinyint(1) | NO | | NULL | |
| is_active | tinyint(1) | NO | | NULL | |
| date_joined | datetime(6) | NO | | NULL | |
+--------------+--------------+------+-----+---------+----------------+
11 rows in set (0.00 sec)
auth基本模型操作:
-
创建用户
-
创建普通用户create_user
from django.contrib.auth import models user = models.User.objects.create_user(username='用户名', password='密码', email='邮箱',...) ... user.save() -
创建超级用户create_superuser
from django.contrib.auth import models user = models.User.objects.create_superuser(username='用户名', password='密码', email='邮箱',...) ... user.save()
-
-
删除用户
from django.contrib.auth import models try: user = models.User.objects.get(username='用户名') user.is_active = False # 记当前用户无效 user.save() print("删除普通用户成功!") except: print("删除普通用户失败") return HttpResponseRedirect('/user/info') -
修改密码set_password
from django.contrib.auth import models try: user = models.User.objects.get(username='xiaonao') user.set_password('654321') user.save() return HttpResponse("修改密码成功!") except: return HttpResponse("修改密码失败!") -
from django.contrib.auth import models try: user = models.User.objects.get(username='xiaonao') if user.check_password('654321'): # 成功返回True,失败返回False return HttpResponse("密码正确") else: return HttpResponse("密码错误") except: return HttpResponse("没有此用户!")
21. 生成CSV文件
Django可直接在视图函数中生成csv文件 并响应给浏览器
import csv
from django.http import HttpResponse
from .models import Book
def make_csv_view(request):
response = HttpResponse(content_type='text/csv')
response['Content-Disposition'] = 'attachment; filename="mybook.csv"'
all_book = Book.objects.all()
writer = csv.writer(response)
writer.writerow(['id', 'title'])
for b in all_book:
writer.writerow([b.id, b.title])
return response
- 响应获得一个特殊的MIME类型text / csv。这告诉浏览器该文档是CSV文件,而不是HTML文件
- 响应会获得一个额外的
Content-Disposition标头,其中包含CSV文件的名称。它将被浏览器用于“另存为…”对话框 - 对于CSV文件中的每一行,调用
writer.writerow,传递一个可迭代对象,如列表或元组。
22. 电子邮件发送
# 发送邮件设置
EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' # 固定写法
EMAIL_HOST = 'smtp.qq.com' # 腾讯QQ邮箱 SMTP 服务器地址
EMAIL_PORT = 25 # SMTP服务的端口号
EMAIL_HOST_USER = 'xxxx@qq.com' # 发送邮件的QQ邮箱
EMAIL_HOST_PASSWORD = '******' # 邮箱的授权码(即QQ密码)
EMAIL_USE_TLS = True # 与SMTP服务器通信时,是否启动TLS链接(安全链接)默认false
mail.send_mail(subject='test1111', message='123',from_email='ding_t_f@163.com',recipient_list=['572708691@qq.com'], auth_password='gjy19881227')
视图函数中
from django.core import mail
mail.send_mail(
subject, #题目
message, # 消息内容
from_email, # 发送者[当前配置邮箱]
recipient_list=['xxx@qq.com',], # 接收者邮件列表
auth_password='xxxxxxx' # 在QQ邮箱->设置->帐户->“POP3/IMAP......服务” 里得到的在第三方登录QQ邮箱授权码
)
23. 项目部署
-
安装同版本的数据库
- 安装步骤略
-
django 项目迁移
WSGI Django工作环境部署
- WSGI (Web Server Gateway Interface)Web服务器网关接口,是Python应用程序或框架和Web服务器之间的一种接口,被广泛使用
- 它实现了WSGI协议、http等协议。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。WSGI是一种Web服务器网关接口。
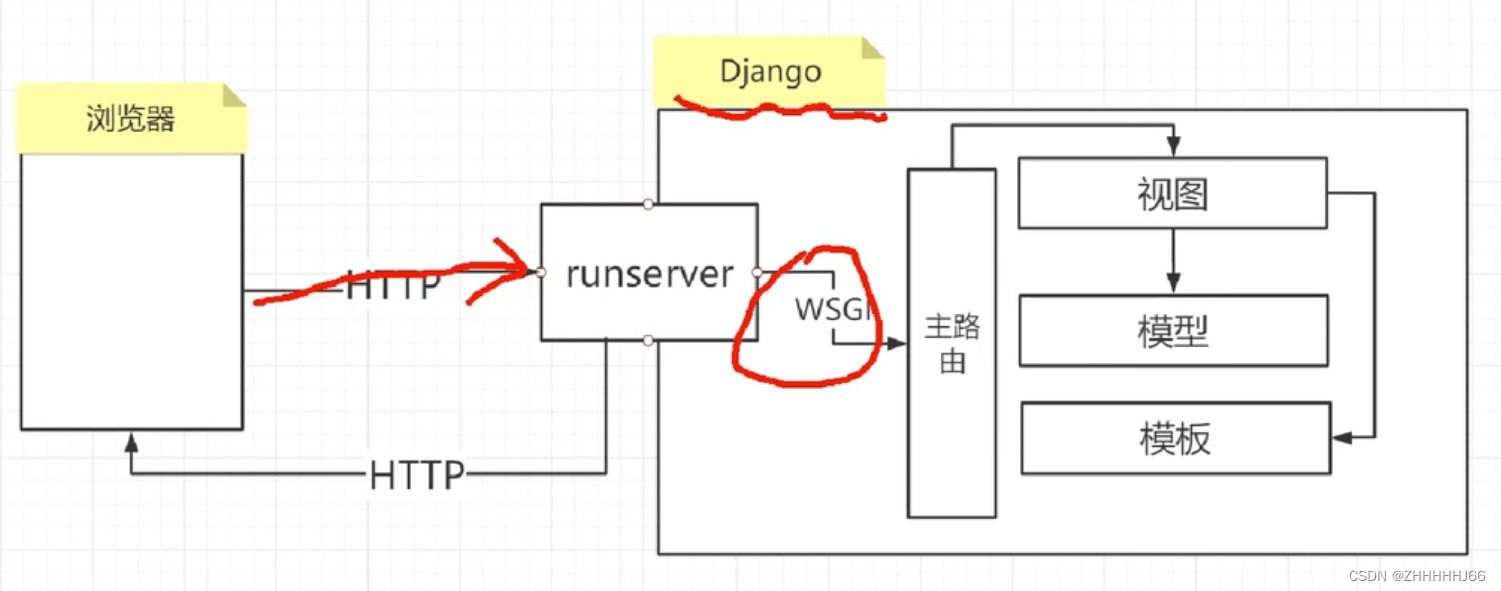
uWSGI 网关接口配置 (ubuntu 18.04 配置)
-
安装uWSGI
-
配置uWSGI
-
[uwsgi] # 套接字方式的 IP地址:端口号 # socket=127.0.0.1:8000 # Http通信方式的 IP地址:端口号 http=127.0.0.1:8000 # 项目当前工作目录 chdir=/home/tarena/.../my_project 这里需要换为项目文件夹的绝对路径 # 项目中wsgi.py文件的目录,相对于当前工作目录 wsgi-file=my_project/wsgi.py # 进程个数 process=4 # 每个进程的线程个数 threads=2 # 服务的pid记录文件 pidfile=uwsgi.pid # 服务的目志文件位置 daemonize=uwsgi.log -
修改settings.py将 DEBUG=True 改为DEBUG=False
-
修改settings.py 将 ALLOWED_HOSTS = [] 改为 ALLOWED_HOSTS = [‘*’]
-
-
uWSGI的运行管理
-
测试:
- 在浏览器端输入http://127.0.0.1:8000 进行测试
- 注意,此时端口号为8000
nginx 反向代理配置
-
Nginx是轻量级的高性能Web服务器,提供了诸如HTTP代理和反向代理、负载均衡、缓存等一系列重要特性,在实践之中使用广泛。
-
nginx 作用
-
原理:
-
nginx 配置
# 在server节点下添加新的location项,指向uwsgi的ip与端口。 server { ... location / { uwsgi_pass 127.0.0.1:8000; # 重定向到127.0.0.1的8000端口 include /etc/nginx/uwsgi_params; # 将所有的参数转到uwsgi下 } ... } -
nginx服务控制
$ sudo /etc/init.d/nginx start|stop|restart|status # 或 $ sudo service nginx start|stop|restart|status -
修改uWSGI配置
[uwsgi] # 去掉如下 # http=127.0.0.1:8000 # 改为 socket=127.0.0.1:8000- 重启uWSGI服务
$ sudo uwsgi --stop uwsgi.pid $ sudo uwsgi --ini 项目文件夹/uwsgi.ini -
测试:
- 在浏览器端输入http://127.0.0.1 进行测试
- 注意,此时端口号为80(nginx默认值)
nginx 配置静态文件路径
-
解决静态路径问题
# file : /etc/nginx/sites-available/default # 新添加location /static 路由配置,重定向到指定的绝对路径 server { ... location /static { # root static文件夹所在的绝对路径,如: root /home/tarena/my_django_project; # 重定向/static请求的路径,这里改为你项目的文件夹 } ... } -
修改配置文件后需要重新启动 nginx 服务
404 界面
-
在模板文件夹内添加 404.html 模版,当视图触发Http404 异常时将会被显示
-
404.html 仅在发布版中(即setting.py 中的 DEBUG=False时) 才起作用
-
当向应处理函数触发Http404异常时就会跳转到404界面
from django.http import Http404 def xxx_view(request): raise Http404 # 直接返回404
原文地址:https://blog.csdn.net/weixin_46187354/article/details/130659907
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_32056.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!