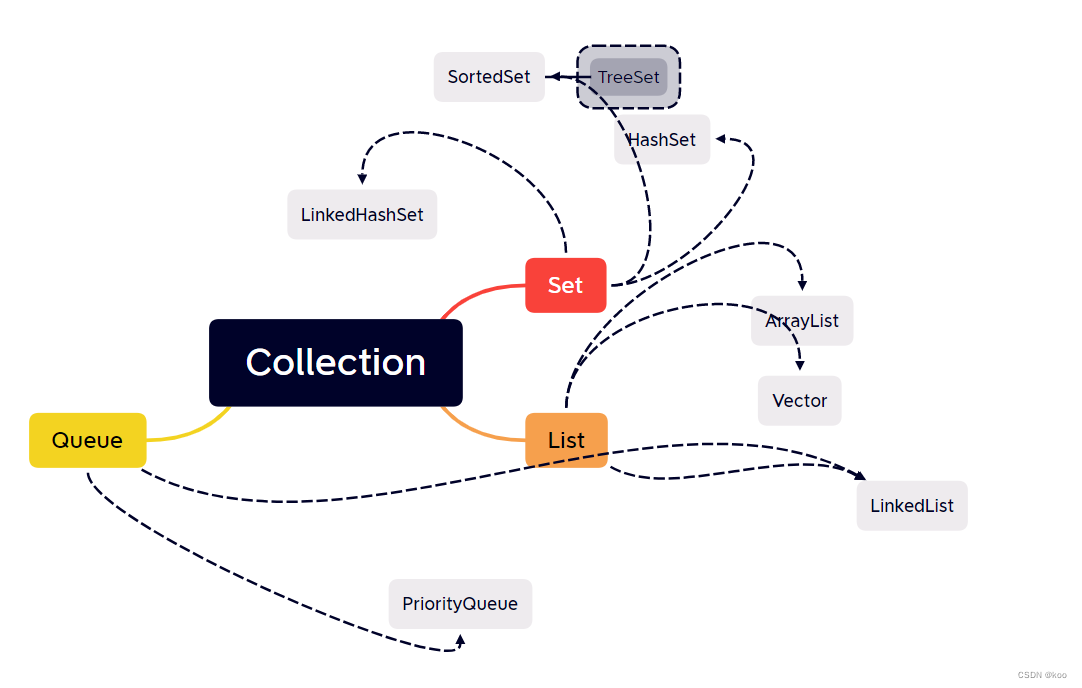
本文介绍: Collection容器其实是用来存储独立元素的各种数据结构,如图所示。主要是Set、List、Queue等数据结构,又分为不同的分支具有部分不同的属性和特性。Collection是整个集合框架的基础,提供了维护一组对象的基本接口。
一、容器(Collection)
1、ArrayList
2、LinkedList
3、Vector
二、Map类
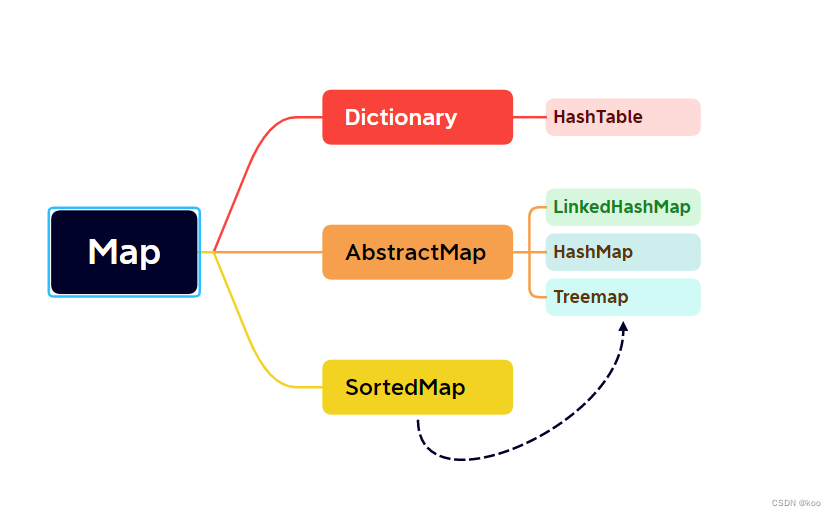
1、HashMap
2、LinkedHashMap
3、HashTable
4、TreeMap
三、Set(集合)
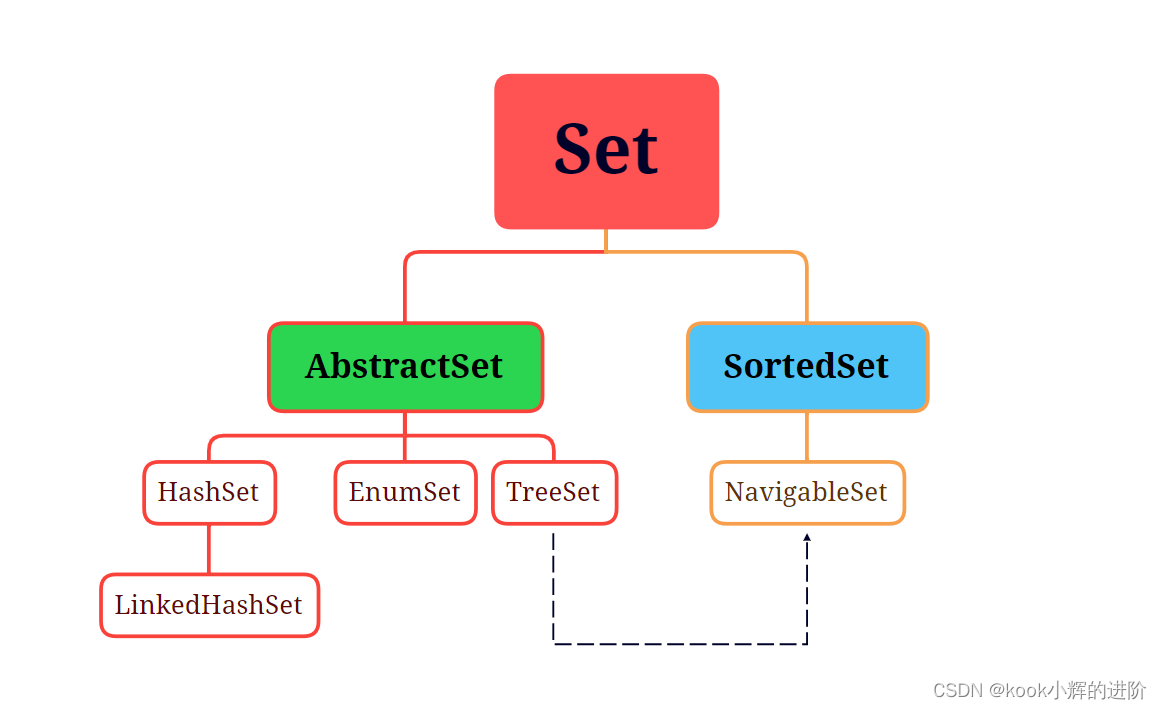
1、HashSet
2、LinkedHashSet
3、TreeSet
四、Queue
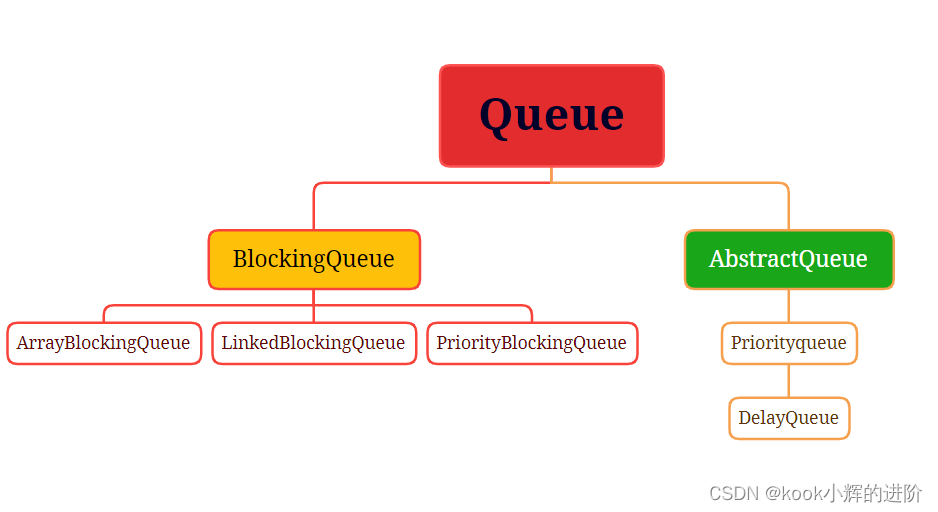
1、BlockingQueue
2、ArrayBlockingQueue
3、LinkedBlockingQueue
4、PriorityBlockingQueue
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。