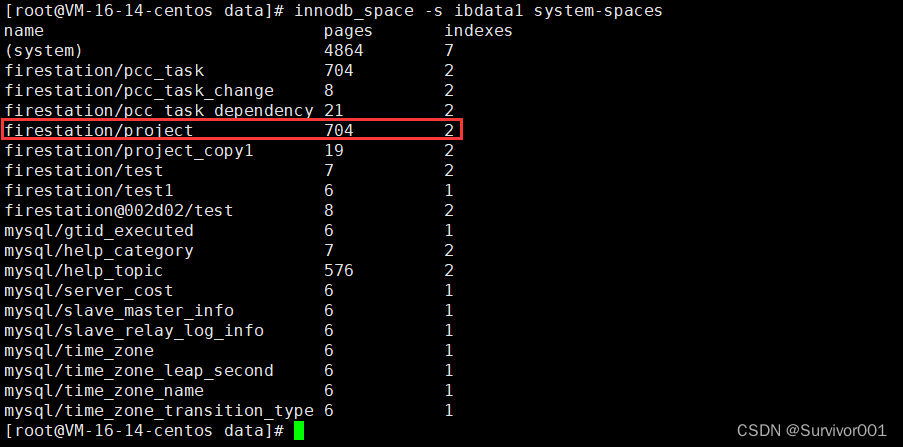
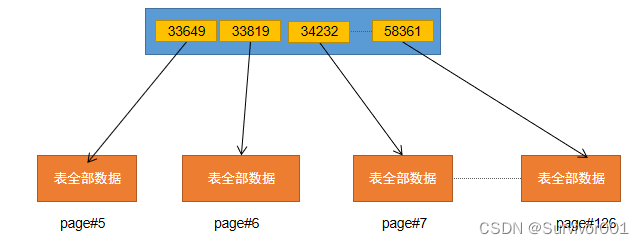
本文介绍: 这也正对了前面说到的最左原则特性。之前理论知识也说过了,目录页会记录最小索引列编号,来作为目录检索,比如查询34000,那就是在33819~34232区间,指向page 6 号数据页里面,这个时候就会去6号page页检索。这里可以看到在查看了page为3(PRIMARY索引的root页)的页信息后,一共出来95个page信息,对应了上述表述的95个leaf page,同时默认按照主键ID从小到大排序。可以看出来在二级索引的leaf节点中,是没有完整的数据信息的,处理索引列数据,还存储了主键id信息。
达在之前已经分享过Innodb数据存储结构知识,但是都是基于理论原理知识理解,今天利用Innodb文件解析工具ruby进行探索Innodb真实的存储结构。
索引原理过程:【Mysql】 InnoDB引擎深入 – 数据页 | 聚集索引_innodb的聚集索引的数据插入_Survivor001的博客-CSDN博客
Innodb_ruby工具的安装过程也分享过,这里就不阐述了,具体的使用方法,可以查看官网git上面的介绍:Home · jeremycole/innodb_ruby Wiki · GitHub
这里我创建了简单的一些表:project用来验证不同的理论原理知识:











声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。