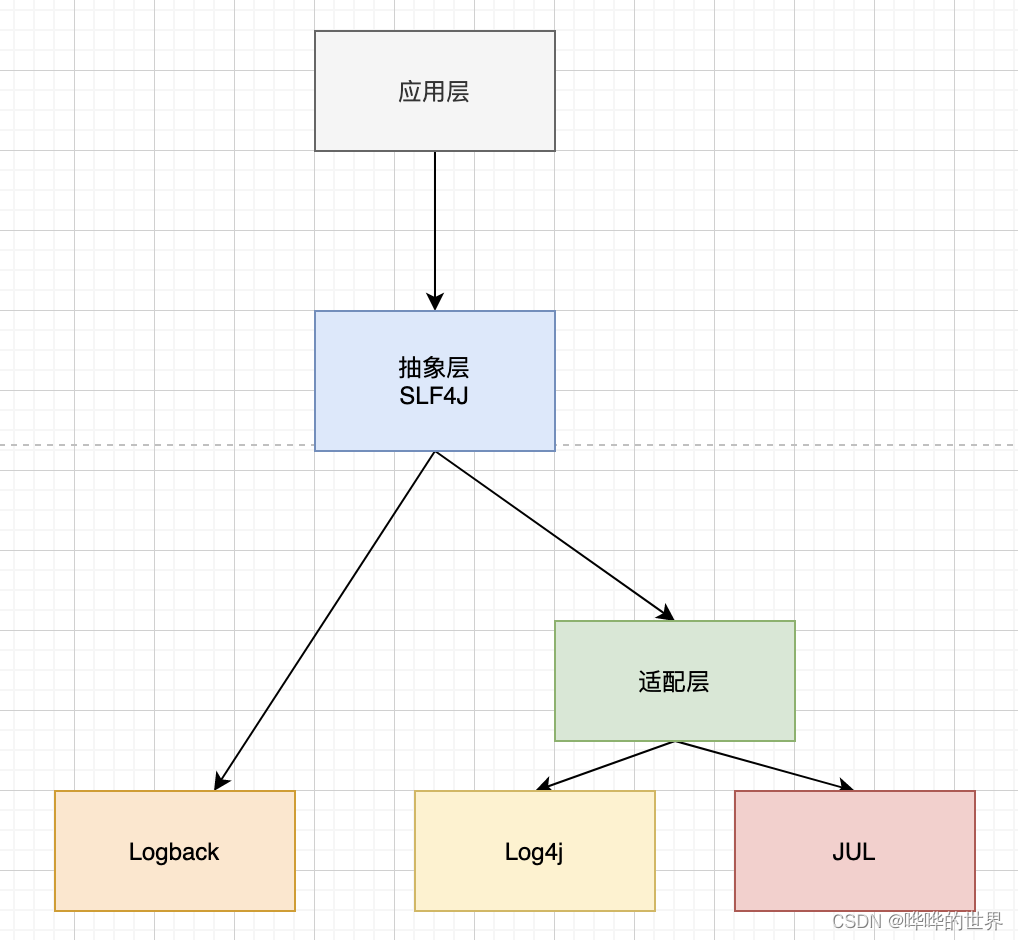
文/朱季谦
我最近使用四台Centos虚拟机搭建了一套分布式hadoop环境,简单模拟了线上上的hadoop真实分布式集群,主要用于业余学习大数据相关体系。
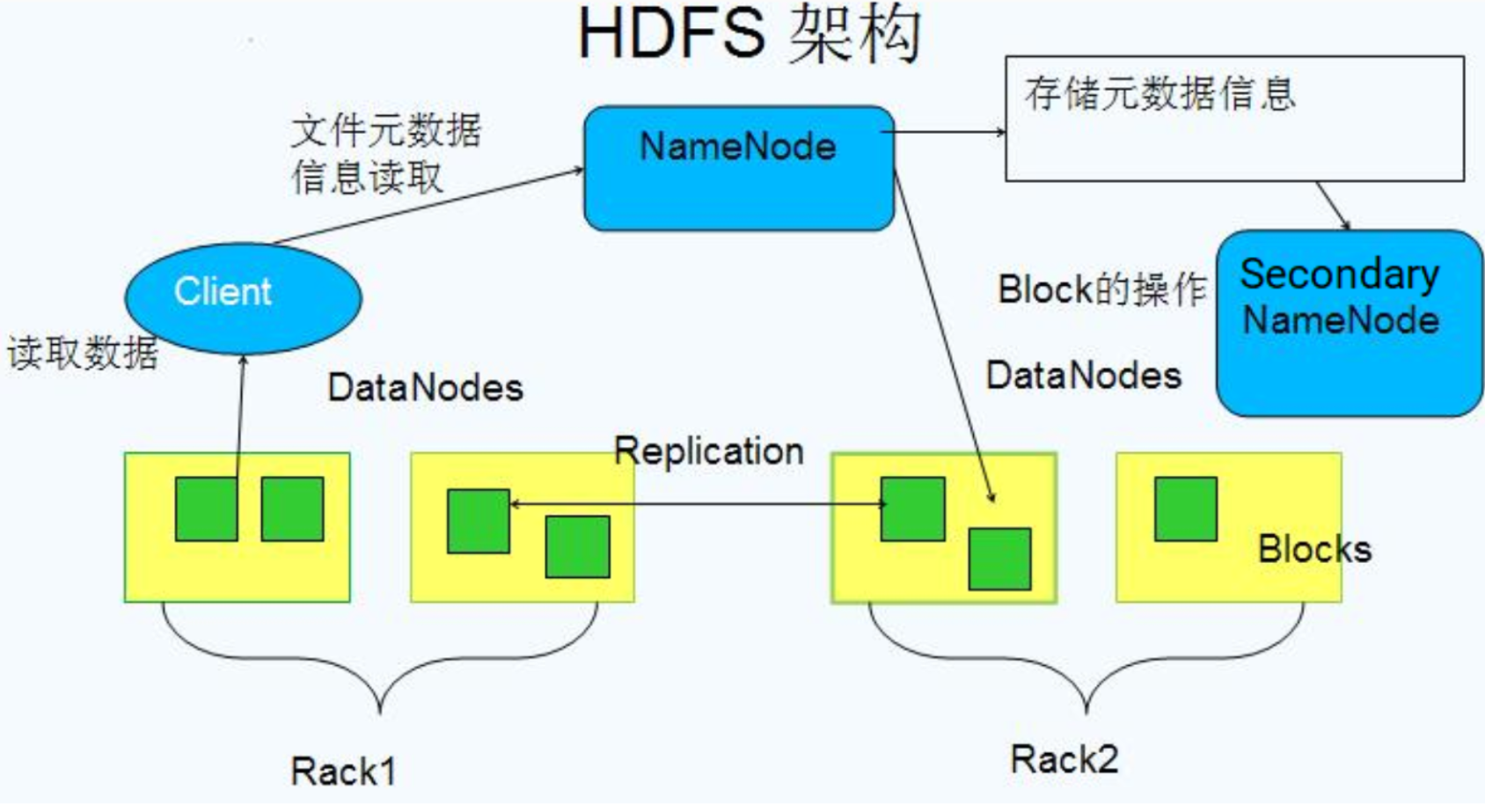
其中,一台服务器作为NameNode,一台作为Secondary NameNode,剩下两台当做DataNodes节点服务器,类似下面这样一个架构——
| NameNode | Secondary NameNode | DataNodes | |
|---|---|---|---|
| master1(192.168.200.111) | √ | ||
| master2(192.168.200.112) | √ | ||
| slave1(192.168.200.117) | √ | ||
| slave2(192.168.200.115) | √ |
接下来,就是开始通过hadoop自带的wordcount来统计一下文件当中的字符数量。
启动hadoop集群后,在集群可用情况下,按照以下步骤:
一、进入到hadoop安装目录,创建一个测试文件example.txt
我的安装目录是:/opt/hadoop/app/hadoop/hadoop-2.7.5
[root@192 hadoop-2.7.5]# pwd
/opt/hadoop/app/hadoop/hadoop-2.7.5
aaa
bbb
cccc
dedef
dedf
dedf
ytrytrgtrcdscdscdsc
dedaxa
cdsvfbgf
uyiuyi
ss
xaxaxaxa
接着,在hdfs文件系统上新建一个input文件夹,用来存放example.txt文件——
[root@192 hadoop-2.7.5]# hdfs dfs -mkdir /input
然后,将example.txt复制到hdfs系统上的input目录下——
[root@192 hadoop-2.7.5]# hdfs dfs -put example.txt /input
检查一下,可以看到,example.txt文件已经在input目录底下了——
[root@192 hadoop-2.7.5]# hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 3 root supergroup 84 2021-10-20 12:43 /input/example.txt
这些准备工作做好后,就可以开始使用hadoop自带的jar包来统计文件example.txt当中各字符的数量了。
[root@192 hadoop-2.7.5]# hadoop jar /opt/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /input /output
这行指令的大概意思是,分布式计算统计input目录底下的文件中的字符数量,将统计结果reduce到output当中,故而,最后若执行没问题,可以在output目录下获取到统计结果记录。
我第一次执行时,发生了一个异常,即执行完后,日志运行到INFO mapreduce.Job: Running job: job_1631618032849_0002这一行时,就直接卡在了这里,没有任何动静了——
[hadoop@192 bin]$ hadoop jar /opt/hadoop/app/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /input /output
21/10/20 10:43:29 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.200.111:8032
21/10/20 10:43:30 INFO input.FileInputFormat: Total input paths to process : 1
21/10/20 10:43:30 INFO mapreduce.JobSubmitter: number of splits:1
21/10/20 10:43:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1631618032849_0002
21/10/20 10:43:31 INFO impl.YarnClientImpl: Submitted application application_1631618032849_0002
21/10/20 10:43:31 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1631618032849_0002/
21/10/20 10:43:31 INFO mapreduce.Job: Running job: job_1631618032849_0002
百度了一番后,根据一些思路,最后将mapred-site.xml最开始的配置由
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
改成这里——
<configuration>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://master1:8001</value>
<final>true</final>
</property>
</configuration>
接着,重启了hadoop集群,就正常了,日志信息就没有卡顿,而是一步执行完成,打印以下的日志记录——
以上步骤执行完后,直接输入指令查看output目录下的信息,可以看到,里面生成了两个文件——
[root@192 hadoop-2.7.5]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-10-20 12:47 /output/_SUCCESS
-rw-r--r-- 3 root supergroup 101 2021-10-20 12:47 /output/part-r-00000
part-r-00000文件是存放统计结果的,我们查看一下——
[root@192 hadoop-2.7.5]# hdfs dfs -cat /output/part-r-00000
aaa 1
bbb 1
cccc 1
cdsvfbgf 1
dedaxa 1
dedef 1
dedf 2
ss 1
uyiuyi 1
xaxaxaxa 1
ytrytrgtrcdscdscdsc 1
对比前面的example.txt文件,可以看到,当中dedf字符串是有两个,其他都是1个,hadoop统计结果也确实如此。
以上,便是初步认识hadoop的一个小案例,接下来,我会在学习过程当中把值得分享的经验都总结下来。
原文地址:https://blog.csdn.net/weixin_40706420/article/details/134544806
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_3224.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!