PostgreSQL 查询处理期间发生了什么?
查询处理是PostgreSQL中最为复杂的子系统。如PostgreSQL官方文档所述,PostgreSQL支持SQL2011标准中的大多数特性,查询处理子系统能够高效地处理这些SQL。
一、PostgresSQL 执行流程是怎样的?
先来一个上帝视角图,下面就是 PostgreSQL 查询处理的流程,也从图中可以看到 PostgreSQL 内部架构里的各个功能模块。
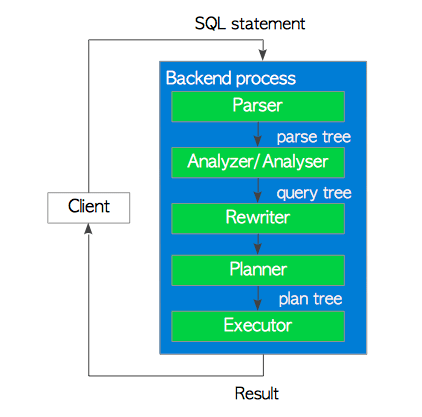
PostgreSQL 的查询流程主要可以分以下几个模块,也有很多文章将解析器与分析器放在一起,这里参考PostgreSQL指南:内幕探索:
-
重写器(Rewriter)
二、解析器(Parser)
解析器基于SQL语句的文本,进行词法分析和语法分析,生成一颗后续子系统可以理解的语法解析树。下面是一个具体的例子。
考虑以下查询:
# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;

SELECT查询中的元素和语法解析树中的元素有着对应关系。比如,(1)是目标列表中的一个元素,与目标表的'id'列相对应,(4)是一个WHERE子句,诸如此类。
当解析器生成语法分析树时只会检查语法,只有当查询中出现语法错误时才会返回错误。解析器并不会检查输入查询的语义,举个例子,如果查询中包含一个不存在的表名,解析器并不会报错,语义检查由分析器负责。
二、分析器(Analyzer)
分析器对解析器产出的语法解析树(parse tree)进行语义分析,并产出一颗查询树(query tree)。
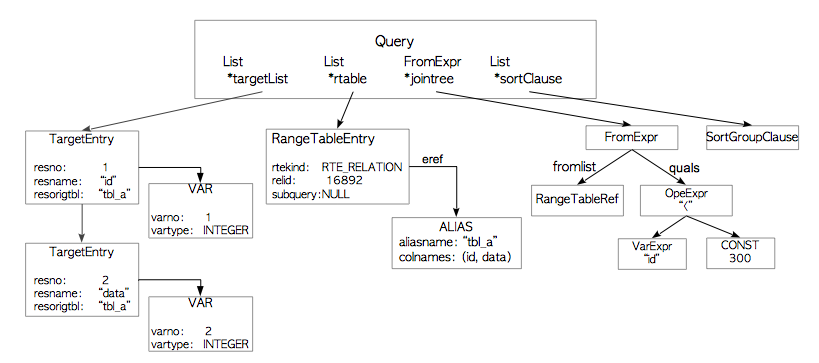
简要介绍一下上图中的查询树:
targetlist是查询结果中**列(Column)**的列表。在本例中该列表包含两列:id和data。如果在输入的查询树中使用了*(星号),那么分析器会将其显式替换为所有具体的列。- 范围表
rtable是该查询所用到关系的列表。本例中该变量包含了表tbl_a的信息,如该表的表名与oid。 - 连接树
jointree存储着FROM和WHERE子句的相关信息。 - 排序子句
sortClause是SortGroupClause结构体的列表。
三、重写器(Rewriter)
PostgreSQL的规则系统正是基于重写器实现的;当需要时,重写器会根据存储在pg_rules中的规则对查询树进行转换。
视图
在PostgreSQL中,视图是基于规则系统实现的。当使用CREATE VIEW命令定义一个视图时,PostgreSQL就会创建相应的规则,并存储到系统目录中。
假设下面的视图已经被定义,而pg_rule中也存储了相应的规则。
# CREATE VIEW employees_list
# AS SELECT e.id, e.name, d.name AS department
# FROM employees AS e, departments AS d WHERE e.department_id = d.id;
当执行一个包含该视图的查询,解析器会创建一颗如下图所示的语法解析树。
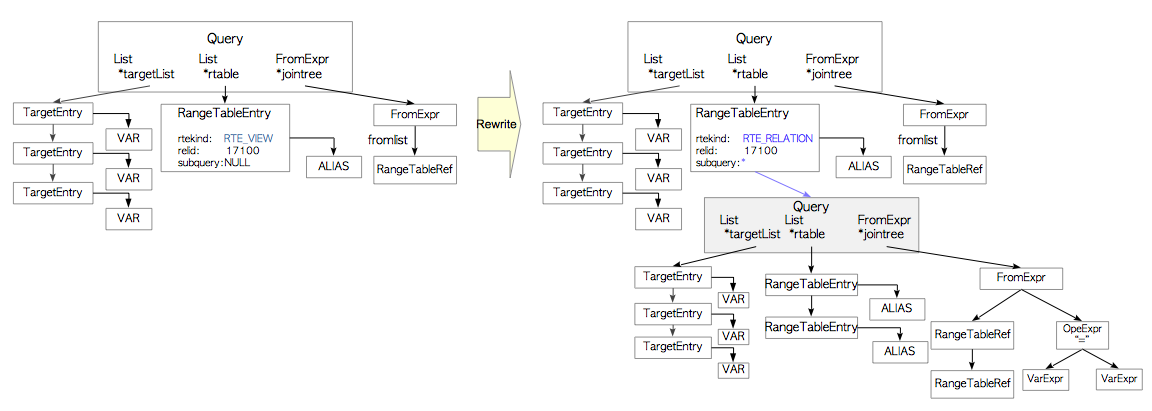
# SELECT * FROM employees_list;
在该阶段,重写器会基于pg_rules中存储的视图规则将rangetable节点重写为一颗查询子树,与子查询相对应。
四、计划(优化)器(Planner)
计划器从重写器获取一颗查询树(query tree),会根据表连接顺序和索引等信息去计算不同路径的可能代价值,最后选出最优者。基于查询树生成一颗能被执行器高效执行的(查询)计划树(plan tree)。
在PostgreSQL中,计划器是完全基于代价估计(cost–based)的;它不支持基于规则的优化与提示(hint)。
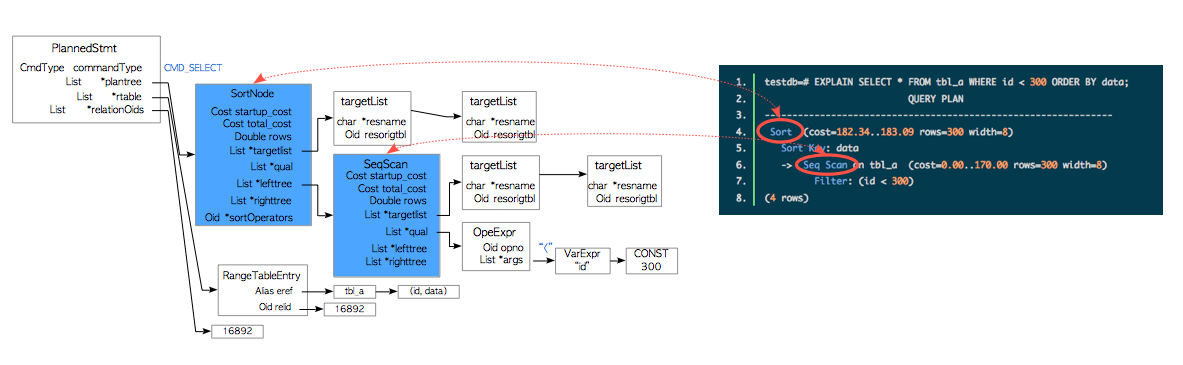
计划树由许多称为**计划节点(plan node)**的元素组成,每个计划节点都包含着执行器进行处理所必需的信息,在单表查询的场景中,执行器会按照从终端节点往根节点的顺序依次处理这些节点。
比如图中的计划树就是一个列表,包含一个排序节点和一个顺序扫描节点;因而执行器会首先对表tbl_a执行顺序扫描,并对获取的结果进行排序。
五、执行器(Executor)
执行器最后执行plan,遍历每个节点,以致完成。最后将查询结果返回给客户端。
执行器会通过缓冲区管理器来访问数据库集簇的表和索引。当处理一个查询时,执行器会使用预先分配的内存空间,比如temp_buffers和work_mem,必要时还会创建临时文件。
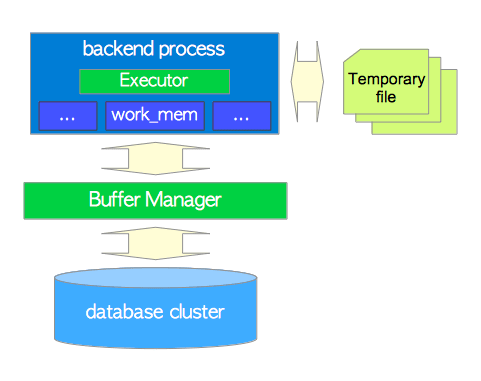
除此之外,当访问元组的时候,PostgreSQL还会使用并发控制机制来维护运行中事务的一致性和隔离性。
总结
可以看到, PostgreSQL 的查询流程主要分五个子系统:
问题
需要注意的是,上述区别是一般性的概述,实际的差异可能更加复杂,并且取决于具体的使用情境和配置设置。选择适合自己需求的数据库取决于企业的目标和资源限制。一般来说,PostgreSQL是一个更为强大和高级的数据库管理系统,适用于需要在大型环境中快速执行复杂查询的组织。而MySQL则是一个更适合预算和空间有限的企业的理想解决方案
参考文献
1.https://www.ibm.com/cloud/blog/postgresql–vs–mysql–whats-the-difference
原文地址:https://blog.csdn.net/qq_42009262/article/details/134754652
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_32262.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!