本文介绍: 我们先更改下models.py,由于上次笔误,把外键关联写错了。传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回404错误响应。传入主键值作为参数,返回指定主键值的记录,如果未找到,则返回None。使用指定规则过滤记录(以关键字表达式的形式),返回新产生的查询对象。我们来继续上次的内容,实现将数据插入数据库。返回查询的第一条记录,如果未找到,则返回404错误响应。返回查询的第一条记录,如果未找到,则返回None。使用指定的规则过滤记录,返回新产生的查询对象。,测试数据来源于我们上节课的内容。
我们先更改下models.py,由于上次笔误,把外键关联写错了。在这里给大家说声抱歉。不过竟然没有小伙伴发现。
接着我们在根目录下创建一个scripts文件夹,用来存放我们一些脚本文件。在scripts文件夹下新建一个insert_sql.py,用来插入测试数据。
然后我们运行 python insert_sql.py ,测试数据来源于我们上节课的内容。
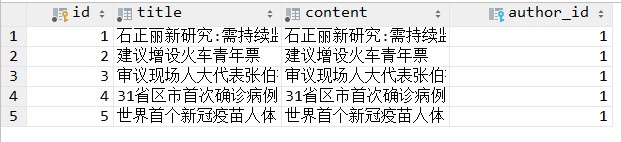
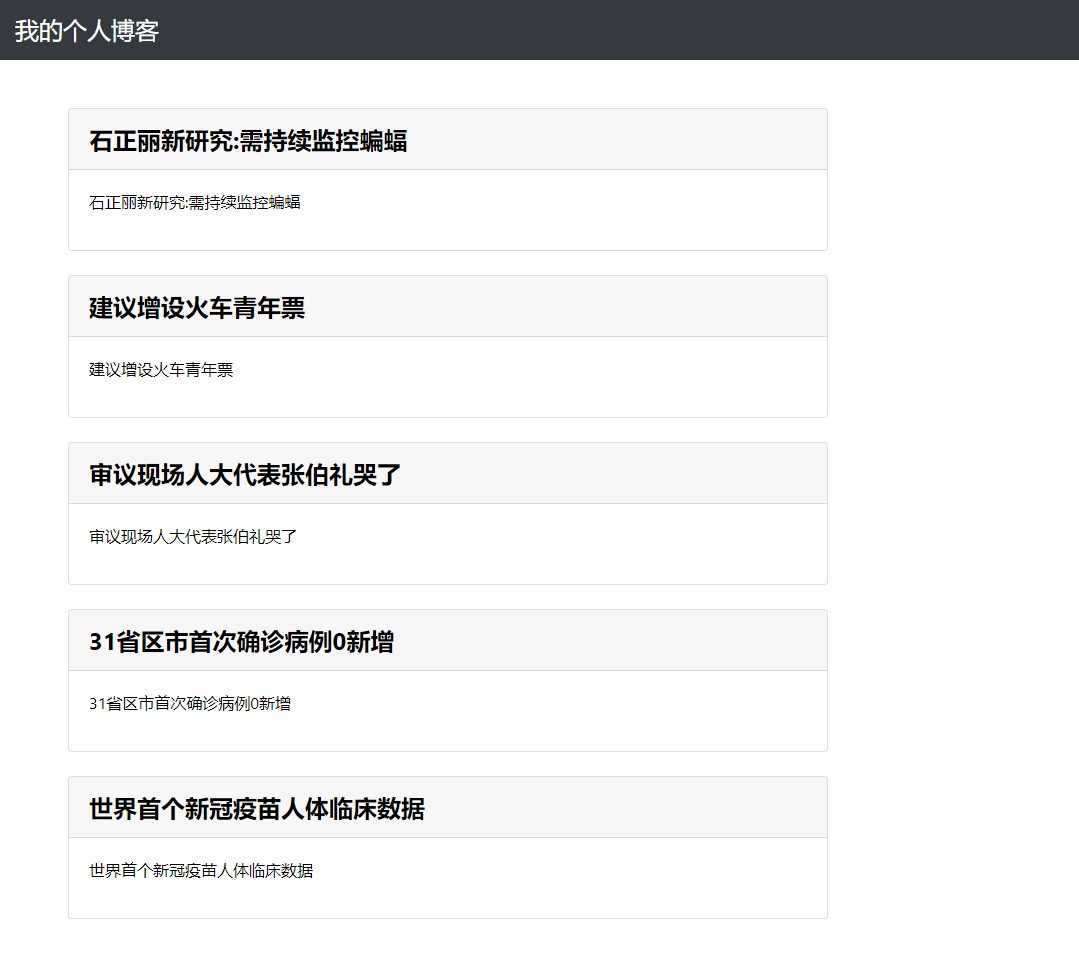
读取
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。