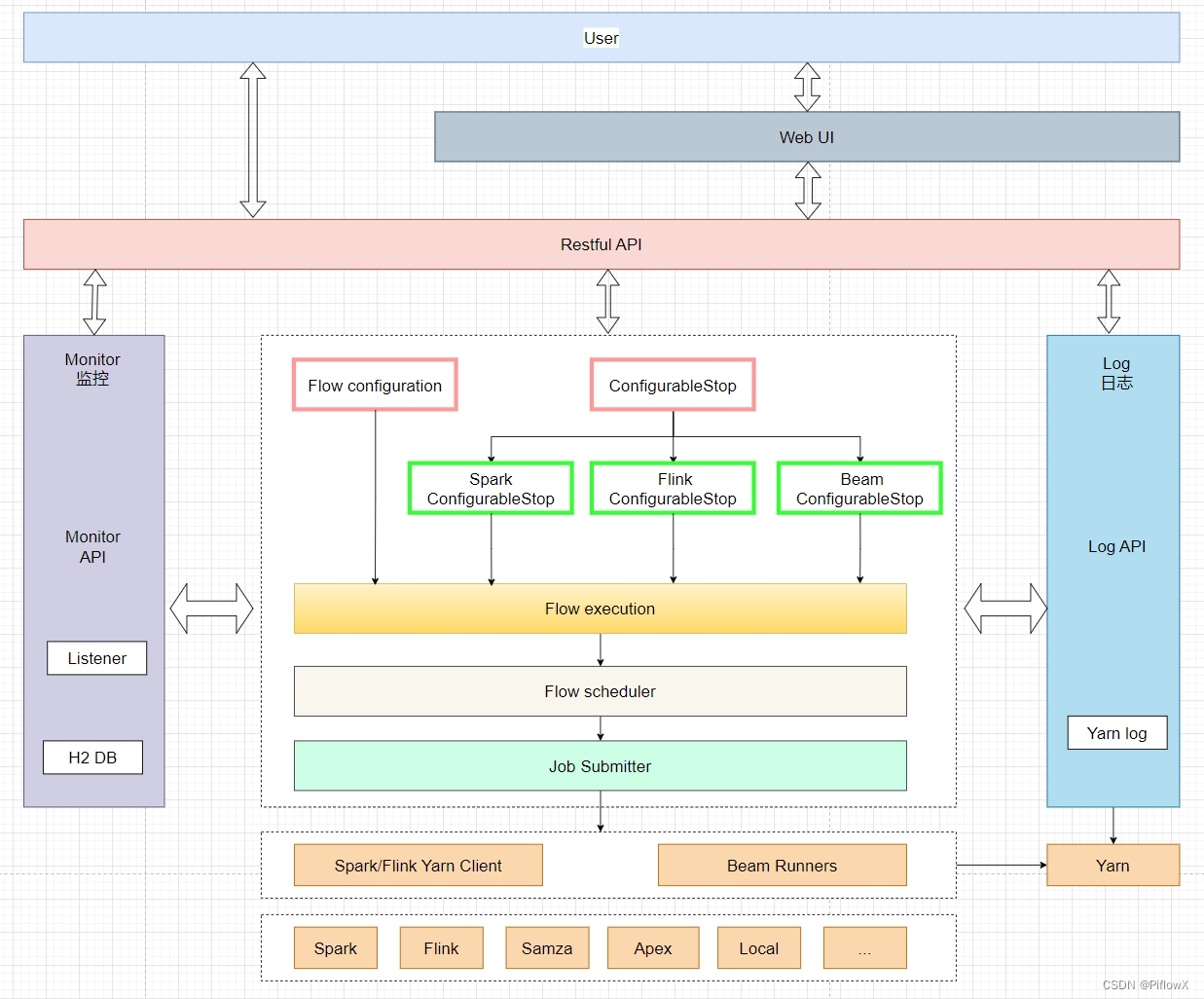
本文介绍: Apache Spark™ 是由加州大学伯克利分校 AMPLab 提出并开源的快速通用计算引擎。它最初用于解决大规模数据集上的海量数据分析,但随着它的不断发展,已经成为用于云计算、机器学习和流处理等领域的核心组件。Spark 支持多种编程语言,包括 Scala、Java、Python 和 R,支持 SQL 和 DataFrame API,提供统一的批处理和流处理功能。Spark 的高性能主要源自其可扩展性、容错机制和动态调度。
1.简介
Apache Spark™ 是由加州大学伯克利分校 AMPLab 提出并开源的快速通用计算引擎。它最初用于解决大规模数据集上的海量数据分析,但随着它的不断发展,已经成为用于云计算、机器学习和流处理等领域的核心组件。Spark 支持多种编程语言,包括 Scala、Java、Python 和 R,支持 SQL 和 DataFrame API,提供统一的批处理和流处理功能。Spark 的高性能主要源自其可扩展性、容错机制和动态调度。它的 API 可以通过 Java、Scala、Python、R、SQL 或 DataFrame API 来访问。
2.特性
2.1.易于使用
Spark 是一个高度抽象的框架。它的 API 通过用户友好的 DataFrames 和 LINQ 查询语法而非编程模型来实现高级操作。对许多应用程序来说,这些特性都使得开发人员能够使用更少的代码编写出更强大的作品。此外,Spark 提供了丰富的工具集,如 MLlib、GraphX、Streaming、ML 管道、Structured Streaming 等,可以帮助用户实现复杂的数据分析工作流。
2.2.分布式计算
Spark 使用了集群资源管理器来启动分布式任务,以便在集群中跨多个节点进行并行计算。Spark 在内部采用 DAG(有向无环图)来执行计算,以确保整个应用的执行效率。这使得 Spark 非常适合用来处理快速数据分析任务,尤其是在处理结构化或半结构化数据时。
2.3.高吞吐量
Spark 可同时处理数十亿条记录,并且具有比 Hadoop 更高的处理能力和速度。Spark 的 MapReduce 模型
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。