1.pandas介绍与环境安装
Pandas包是基于Python平台的数据管理利器,已经成为了Python进行数据分析和挖掘时的数据基础平台和事实上的工业标准。
使用Pandas包完成数据读入、数据清理、 数据准备、图表呈现等工作,为继续学习数据建模和数据挖掘打下坚实基础。
安装pandas
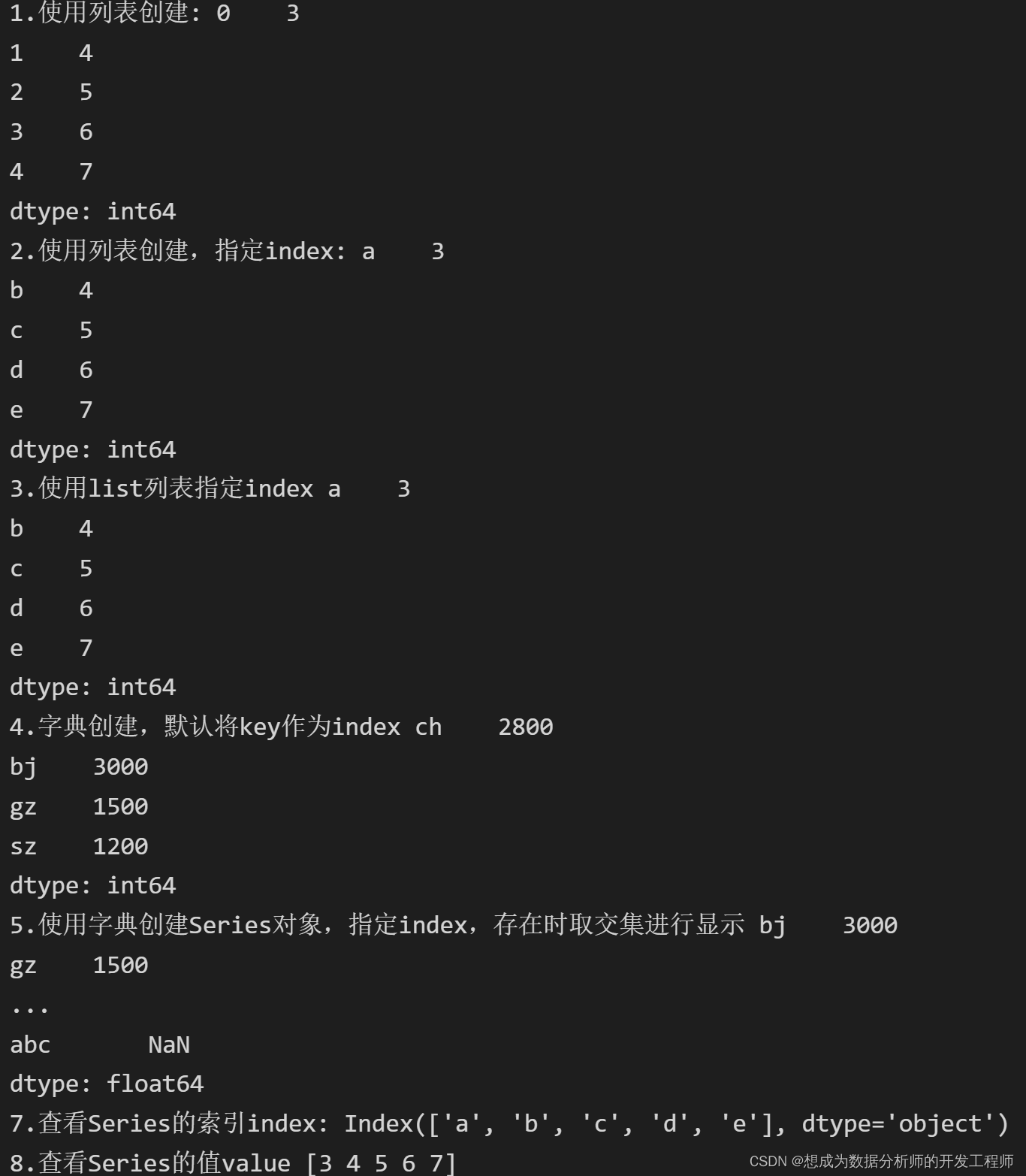
2.Series对象创建
Series:一维数组,与Numpy中的一维array类似。它是一种类似于一维数组的对象,是由一组数据(各种 NumPy 数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series 对象。用值列表生成 Series 时,Pandas 默认自动生成整数索引 。
简单来说,就是对numpy的一维数组array进行升级,多加了一个索引index
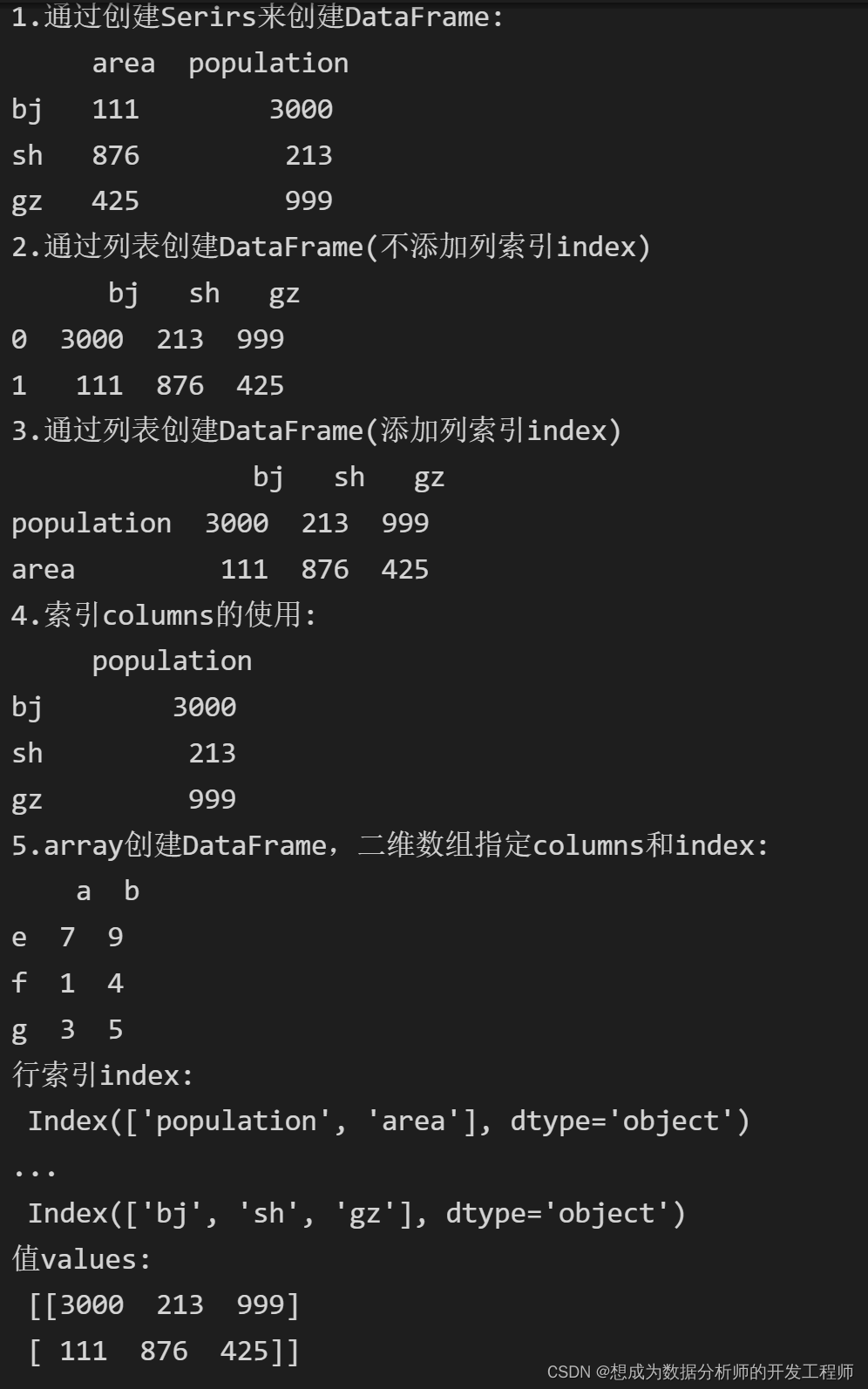
3.DataFrame对象创建
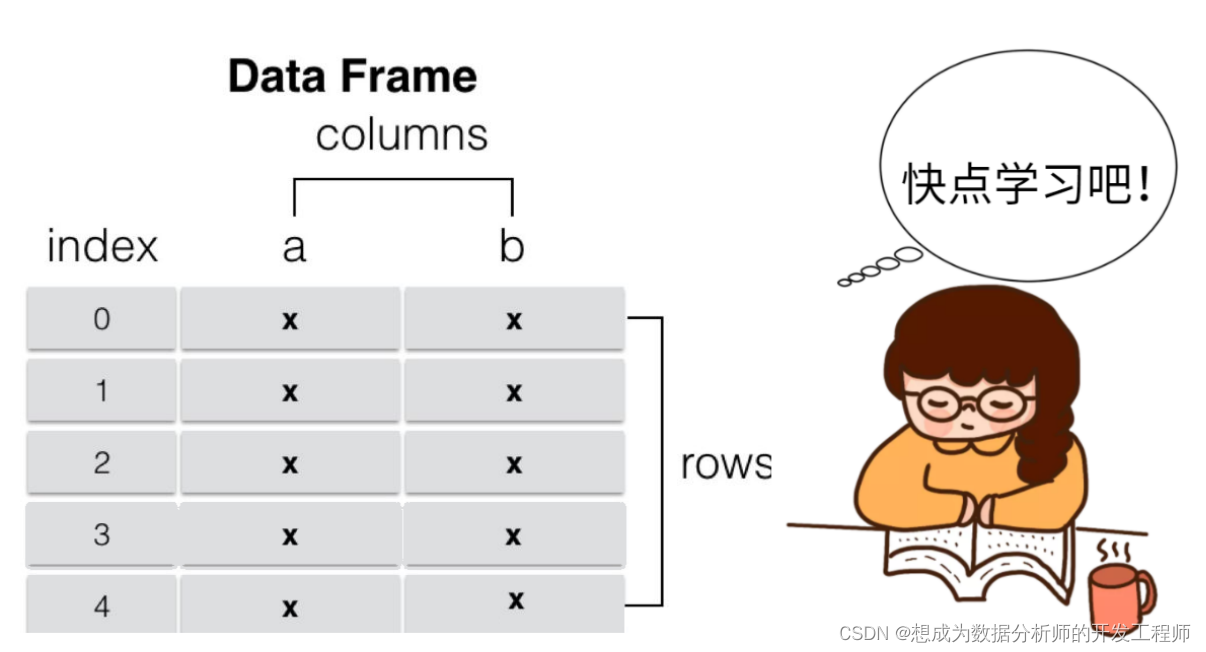
DataFrame 是 Pandas 中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由 Series 组成的字典。
将两个series对象作为dict的value传入,就可以创建一个DataFrame对象。
简单来说,就是对Series(或者说numpy二维的数组)进行升级,添加了行列索引。
4.Pandas中Index对象
pandas中的index(行索引),是一个不可变的一维数组

5.Pandas(Python)导入Excel文件

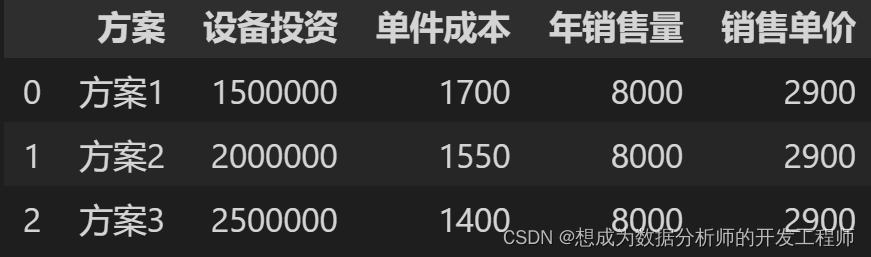
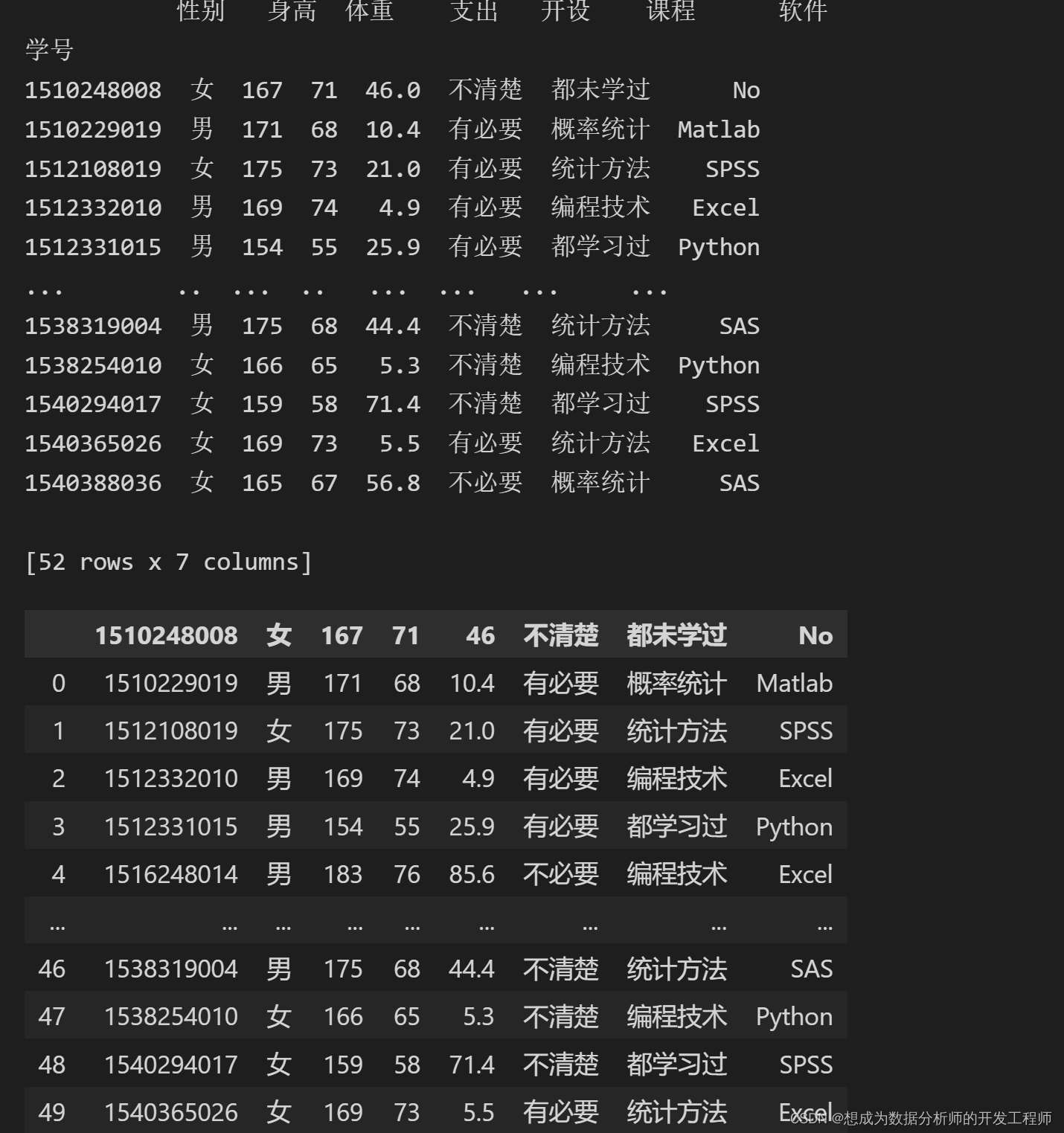
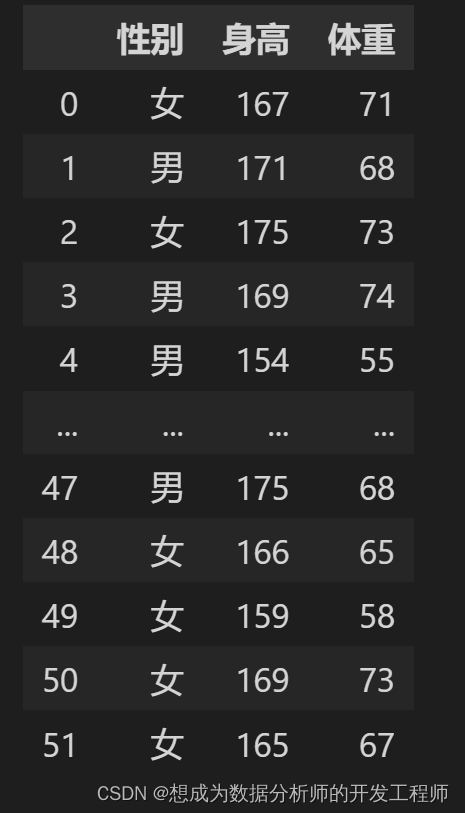
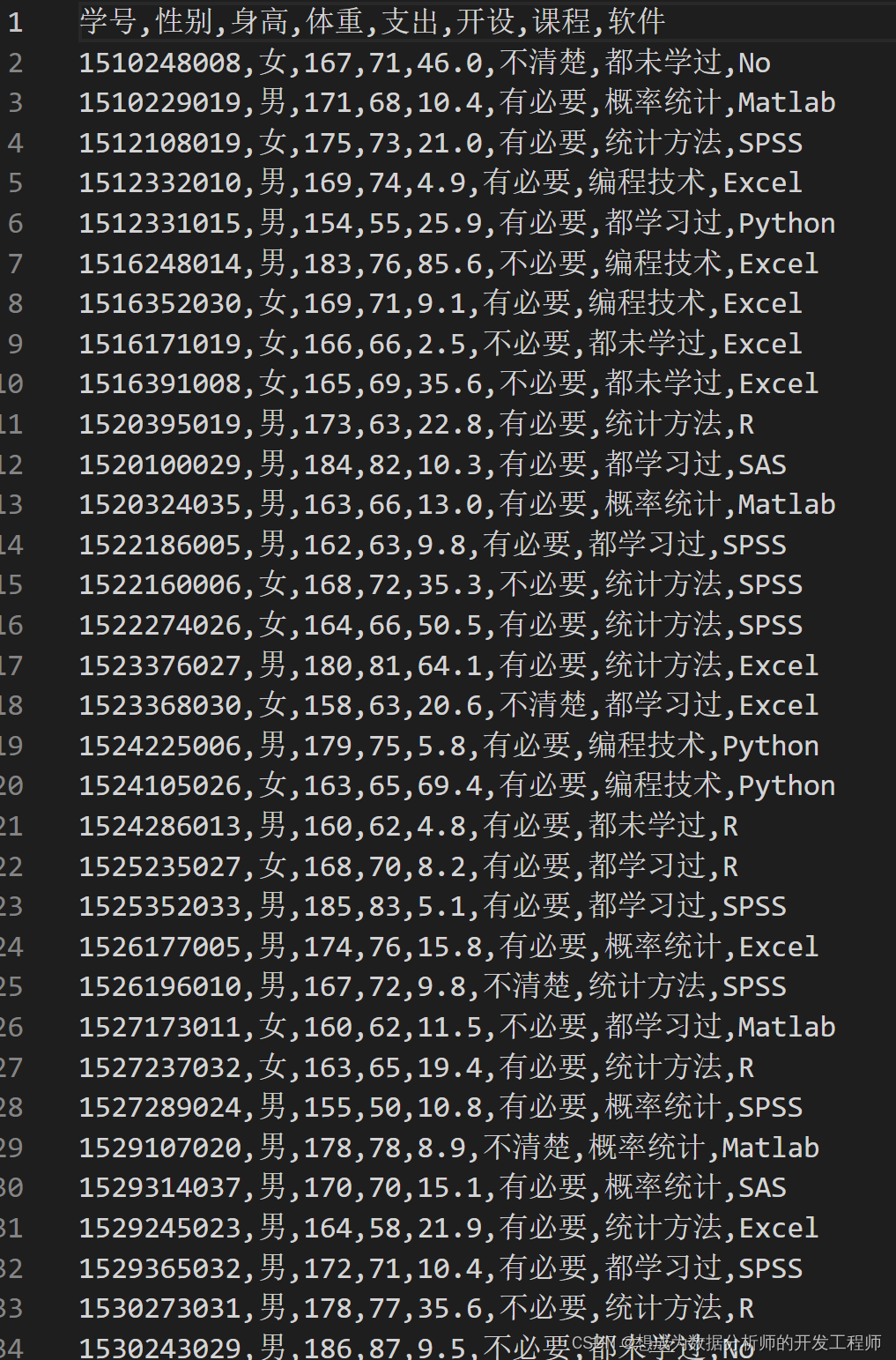
6.Pandas(Python)导入csv文件
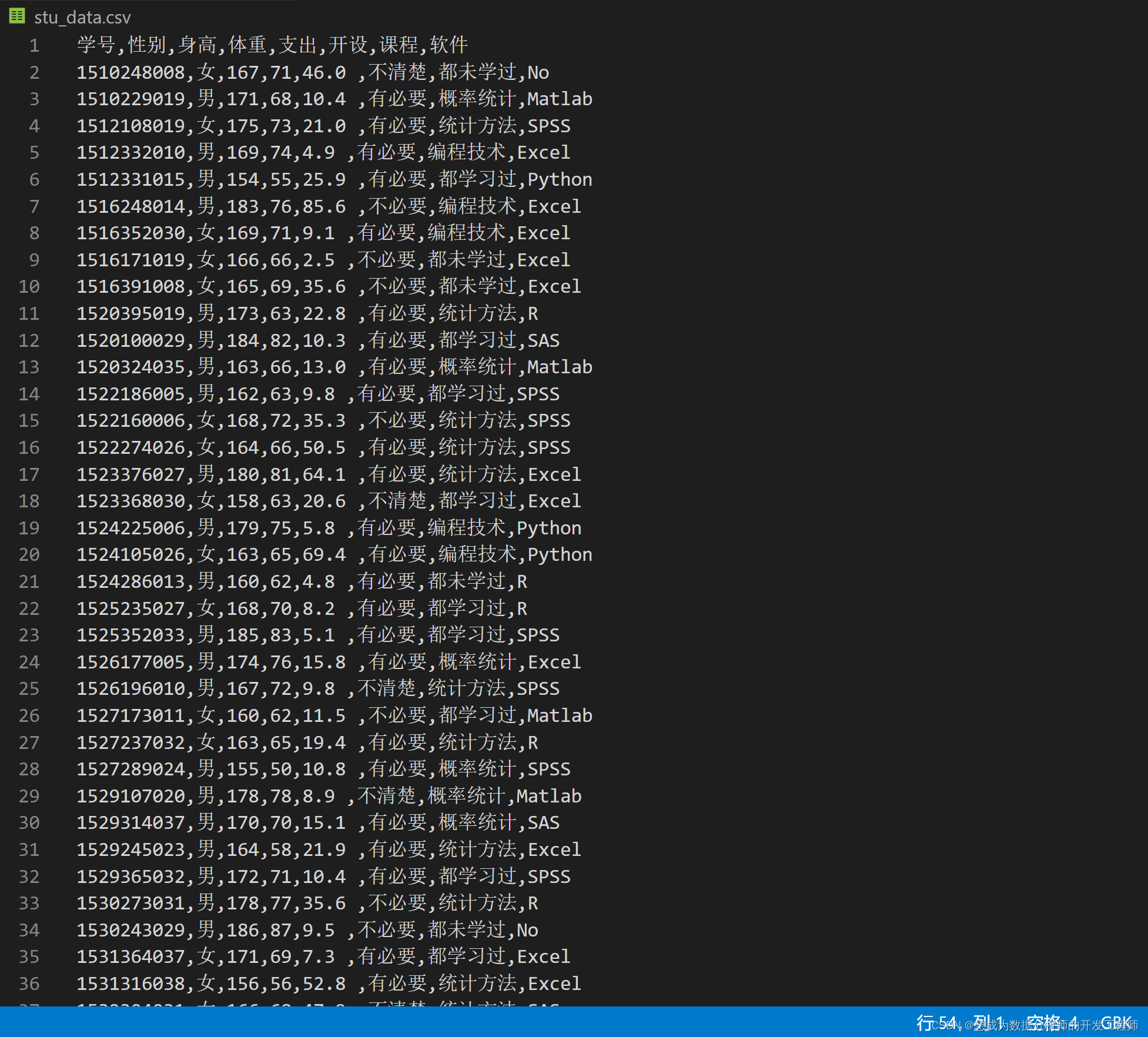
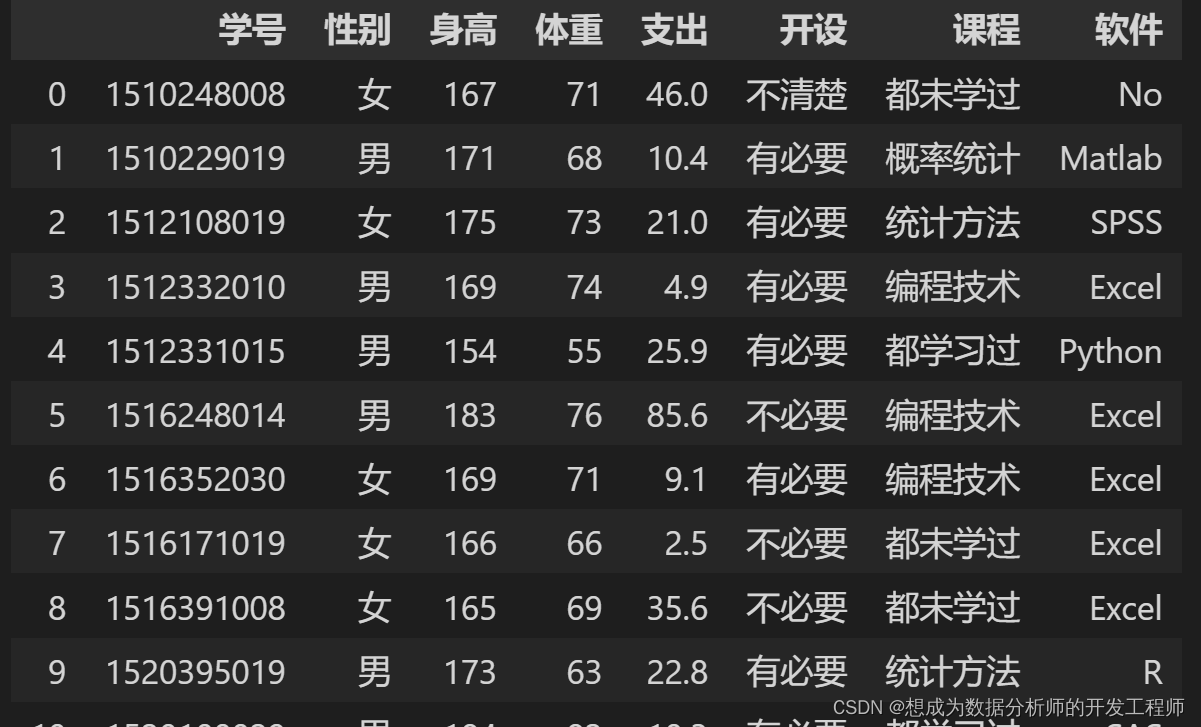
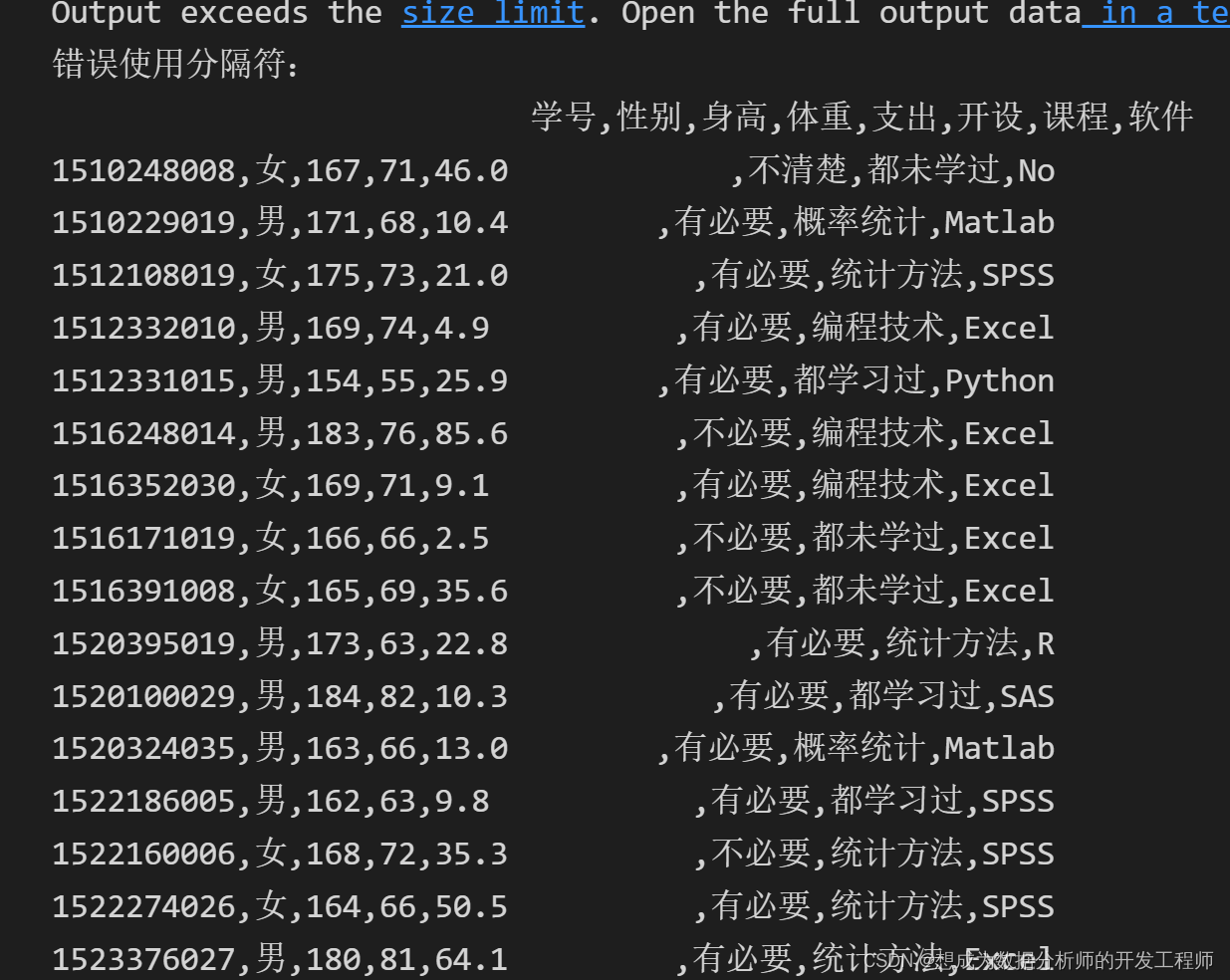
7.Pandas(Python)导入txt文件
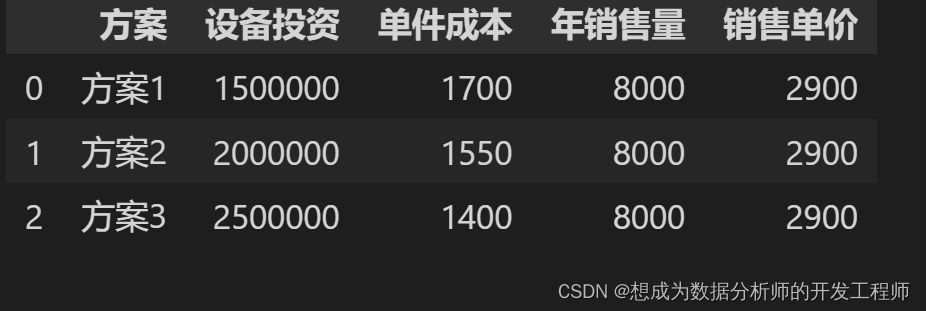
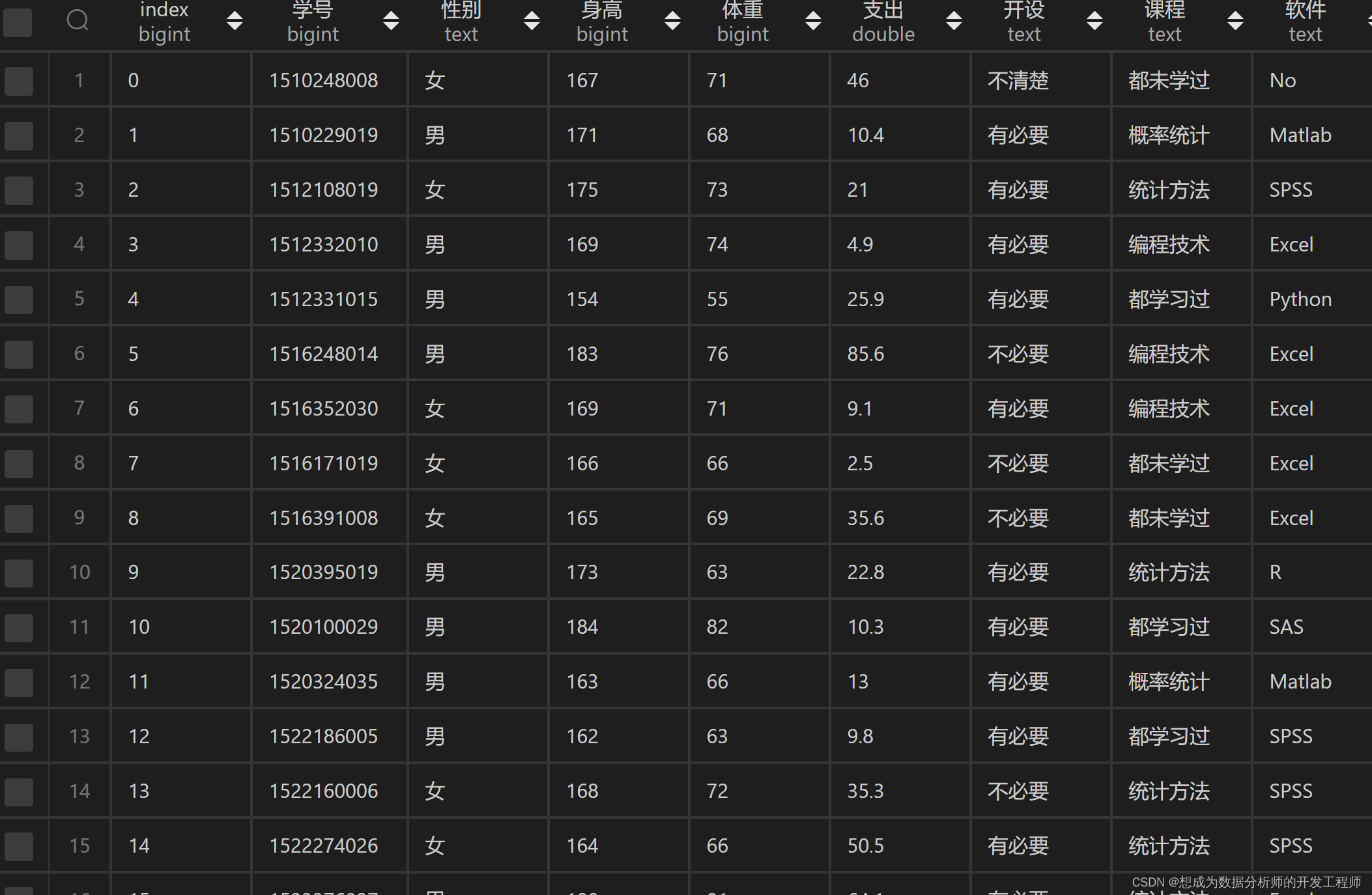
8.Pandas读取数据库中数据
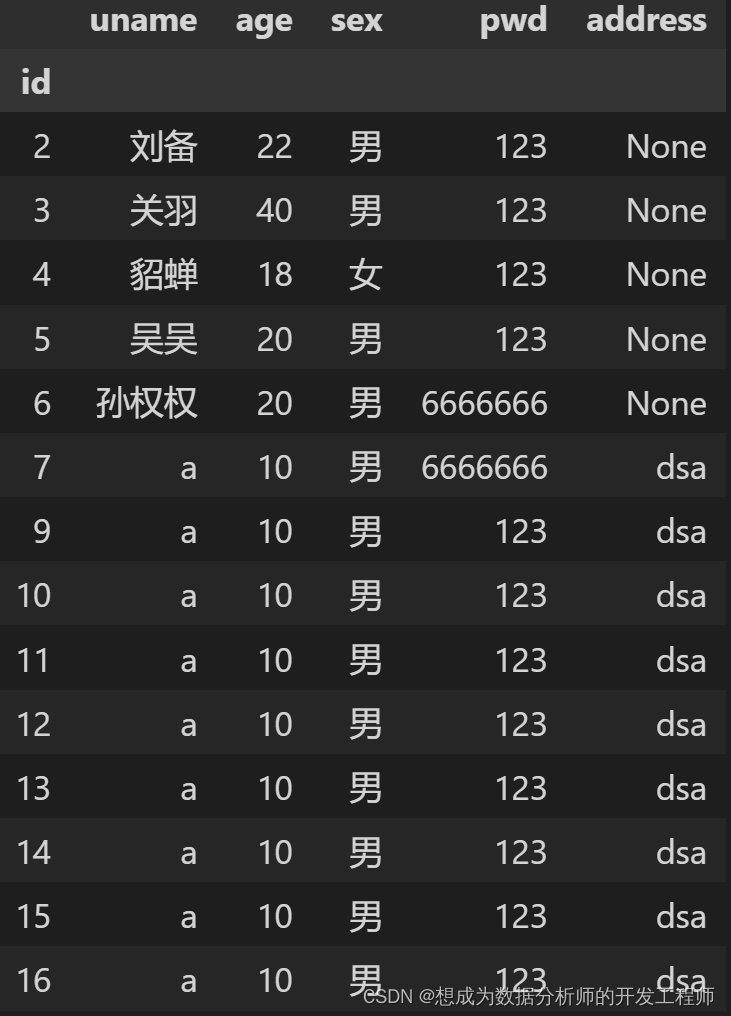
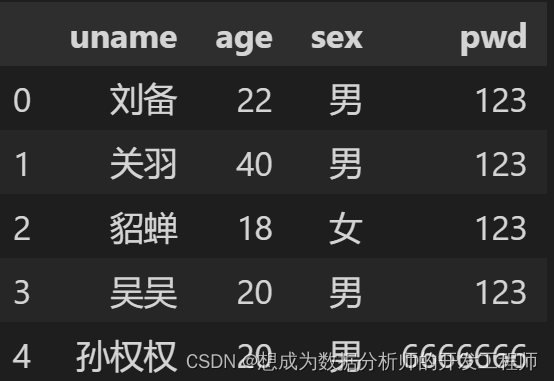
9.Pandas保存数据到CSV或Excel
10.Pandas保存数据到数据库
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







