概述
前段时间,做了一个世界杯竞猜积分排行榜。对世界杯64场球赛胜负平进行猜测,猜对+1分,错误+0分,一人一场只能猜一次。 1.展示前一百名列表。 2.展示个人排名(如:张三,您当前的排名106579)。 一.redis sorts sets简介 Sorted Sets数据类型就像是set和hash的混合。与sets一样,Sorted Sets是唯一的,不重复的字符串组成。可以说Sorted Sets也是Sets的一种。 Sorted Sets是通过Skip List(跳跃表)和hash Table(哈希表)的双端口数据结构实现的,因此每次添加元素时,Redis都会执行O(log(N))操作。所以当我们要求排序的时候,Redis根本不需要做任何工作了,早已经全部排好序了。元素的分数可以随时更新。 二.springboot 中使用RedisTemplate 本文主要通过redisTemplate来操作redis,当然也可以使用redis–client,看个人喜好.
详细
详细
一、运行效果

分析
一开始打算直接使用mysql数据库来做,遇到一个问题,每个人的分数都会变化,如何能够获取到个人的排名呢?数据库可以通过分数进行row_num排序,但是这个方法需要进行全表扫描,当参与的人数达到10000的时候查询就非常慢了。
redis的排行榜功能就完美锲合了这个需求。来看看我是怎么实现的吧。
二、实现过程
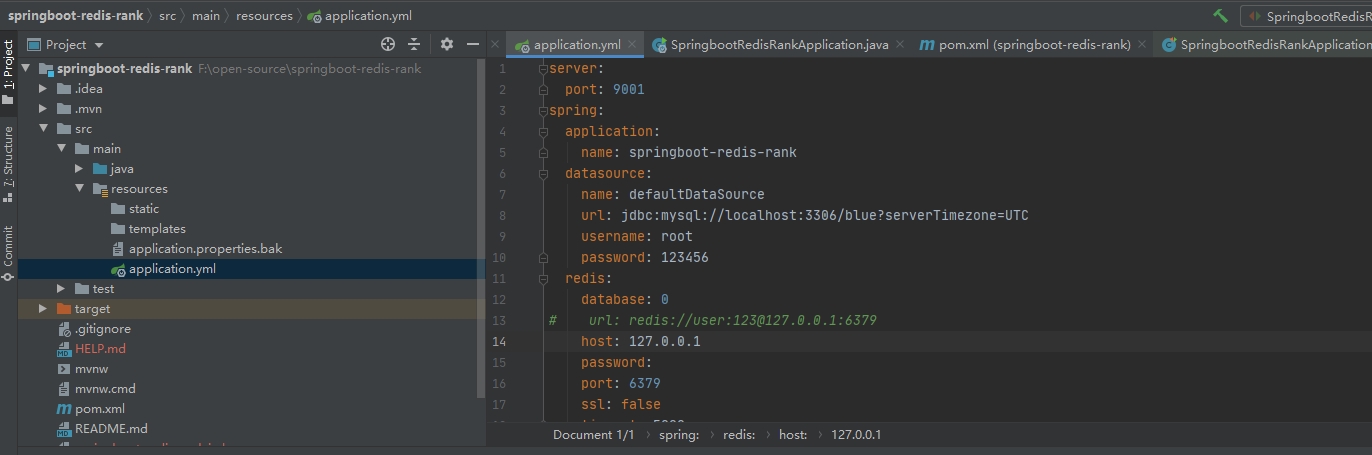
①、在本机开启了一个单点的redis,配置文件如下
: springboot–redis–rank : : defaultDataSource : jdbc:mysql://localhost:3306/blue?serverTimezone=UTC : root : 123456 : : : 127.0.0.1 : : : : 5000
②、Maven依赖引入如下
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>③、代码实现
@Autowired
private StringRedisTemplate redisTemplate;
public static final String SCORE_RANK = "score_rank";/**
* 批量新增
*/
@Test
public void batchAdd() {
Set<ZSetOperations.TypedTuple<String>> tuples = new HashSet<>();
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
DefaultTypedTuple<String> tuple = new DefaultTypedTuple<>("张三" + i, 1D + i);
tuples.add(tuple);
}
System.out.println("循环时间:" +( System.currentTimeMillis() - start));
Long num = redisTemplate.opsForZSet().add(SCORE_RANK, tuples);
System.out.println("批量新增时间:" +(System.currentTimeMillis() - start));
System.out.println("受影响行数:" + num);
}
//输出
循环时间:56
批量新增时间:1015
受影响行数:100000/**
* 获取排行列表
*/
@Test
public void list() {
Set<String> range = redisTemplate.opsForZSet().reverseRange(SCORE_RANK, 0, 10);
System.out.println("获取到的排行列表:" + JSON.toJSONString(range));
Set<ZSetOperations.TypedTuple<String>> rangeWithScores = redisTemplate.opsForZSet().reverseRangeWithScores(SCORE_RANK, 0, 10);
System.out.println("获取到的排行和分数列表:" + JSON.toJSONString(rangeWithScores));
}
//输出
获取到的排行列表:["张三99999","张三99998","张三99997","张三99996","张三99995","张三99994","张三99993","张三99992","张三99991","张三99990","张三99989"]
获取到的排行和分数列表:[{"score":100000.0,"value":"张三99999"},{"score":99999.0,"value":"张三99998"},{"score":99998.0,"value":"张三99997"},{"score":99997.0,"value":"张三99996"},{"score":99996.0,"value":"张三99995"},{"score":99995.0,"value":"张三99994"},{"score":99994.0,"value":"张三99993"},{"score":99993.0,"value":"张三99992"},{"score":99992.0,"value":"张三99991"},{"score":99991.0,"value":"张三99990"},{"score":99990.0,"value":"张三99989"}]4.新增李四的分数
/**
* 单个新增
*/
@Test
public void add() {
redisTemplate.opsForZSet().add(SCORE_RANK, "李四", 8899);
}5.获取李四单人的排行
/**
* 获取单个的排行
*/
@Test
public void find(){
Long rankNum = redisTemplate.opsForZSet().reverseRank(SCORE_RANK, "李四");
System.out.println("李四的个人排名:" + rankNum);
Double score = redisTemplate.opsForZSet().score(SCORE_RANK, "李四");
System.out.println("李四的分数:" + score);
}
//输出
李四的个人排名:91101
李四的分数:8899.0/**
* 统计两个分数之间的人数
*/
@Test
public void count(){
Long count = redisTemplate.opsForZSet().count(SCORE_RANK, 8001, 9000);
System.out.println("统计8001-9000之间的人数:" + count);
}
//输出
统计8001-9000之间的人数:1001/**
* 获取整个集合的基数(数量大小)
*/
@Test
public void zCard(){
Long aLong = redisTemplate.opsForZSet().zCard(SCORE_RANK);
System.out.println("集合的基数为:" + aLong);
}
//输出
集合的基数为:100001 /**
* 使用加法操作分数
*/
@Test
public void incrementScore(){
Double score = redisTemplate.opsForZSet().incrementScore(SCORE_RANK, "李四", 1000);
System.out.println("李四分数+1000后:" + score);
}
//输出
李四分数+1000后:9899.0四.归纳
在以上测试类中我们使用了redis的那些功能呢?在以上的例子中我们使用了单个新增,批量新增,获取前十,获取单人排名这些操作,但是redisTemplate还提供了更多的方法。
新增or更新
有三种方式,一种是单个,一种是批量,对分数使用加法(如果不存在,则从0开始加)。
//单个新增or更新
Boolean add(K key, V value, double score);
//批量新增or更新
Long add(K key, Set<TypedTuple<V>> tuples);
//使用加法操作分数
Double incrementScore(K key, V value, double delta);删除
删除提供了三种方式:通过key/values删除,通过排名区间删除,通过分数区间删除。
//通过key/value删除
Long remove(K key, Object... values);
//通过排名区间删除
Long removeRange(K key, long start, long end);
//通过分数区间删除
Long removeRangeByScore(K key, double min, double max);查
1.列表查询:分为两大类,正序和逆序。以下只列表正序的,逆序的只需在方法前加上reverse即可:
//通过排名区间获取列表值集合
Set<V> range(K key, long start, long end);
//通过排名区间获取列表值和分数集合
Set<TypedTuple<V>> rangeWithScores(K key, long start, long end);
//通过分数区间获取列表值集合
Set<V> rangeByScore(K key, double min, double max);
//通过分数区间获取列表值和分数集合
Set<TypedTuple<V>> rangeByScoreWithScores(K key, double min, double max);
//通过Range对象删选再获取集合排行
Set<V> rangeByLex(K key, Range range);
//通过Range对象删选再获取limit数量的集合排行
Set<V> rangeByLex(K key, Range range, Limit limit);2.单人查询
可获取单人排行,和通过key/value获取分数。以下只列表正序的,逆序的只需在方法前加上reverse即可:
//获取个人排行
Long rank(K key, Object o);
//获取个人分数
Double score(K key, Object o);统计
统计分数区间的人数,统计集合基数。
//统计分数区间的人数Long count(K key, double min, double max);//统计集合基数Long zCard(K key);三、项目结构图
四、补充
以上就是redis中使用排行榜功能的一些例子,和对redis的操作方法了。redis不仅仅只是作为缓存,它更是数据库,提供了许多的功能,我们都可以好好的利用。
在这里我使用redis来实现了世界杯积分排行的展示,无论是在批量更新或是获取个人排行等方便,都有着很高效率,也降低了对数据库操作的压力,达到了很好的效果。
原文地址:https://blog.csdn.net/hanjiepo/article/details/132534755
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_33264.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!