本文介绍: NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。NLP技术,全称为Natural language Processing,即自然语言处理技术,也就是用计算机来处理人类语言的学科。这一时期最有代表性的方法是词袋模型(Bag of Words, or BOW),即统计文章中每个词出现的频率,然后对这个频率的向量进行各种各样的统计分析。
参考:NLP发展之路I – 从词袋模型到Transformer – 知乎 (zhihu.com)
NLP大致的发展历史。从最开始的词袋模型,到RNN,到Transformers和BERT,再到ChatGPT,NLP经历了一段不断精进的发展道路。数据驱动和不断完善的端到端的模型架构是两大发展趋势。
NLP技术,全称为Natural language Processing,即自然语言处理技术,也就是用计算机来处理人类语言的学科。
这一时期最有代表性的方法是词袋模型(Bag of Words, or BOW),即统计文章中每个词出现的频率,然后对这个频率的向量进行各种各样的统计分析。比如可以根据正向词汇和负向词汇在文中出现的频率对比,来判断文章的情感倾向。或者用词频向量去训练一个分类器,做文本分类任务。

词袋模型是一个简单有效的办法。即使在普遍使用深度学习的今天,这个方法仍有时候被作为快速验证或比较基准来使用。
WordEmbedding: 深度学习解决语义问题
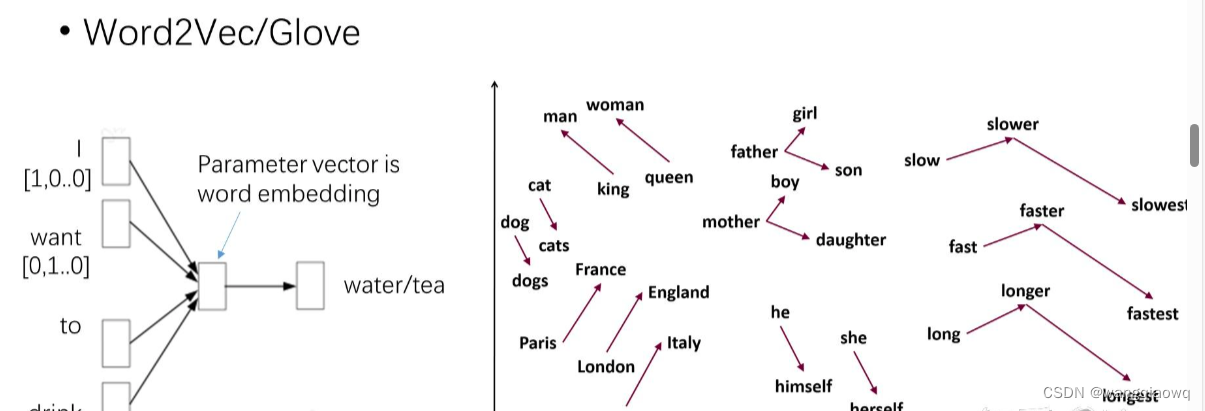
RNN: 循环神经网络解决语序问题
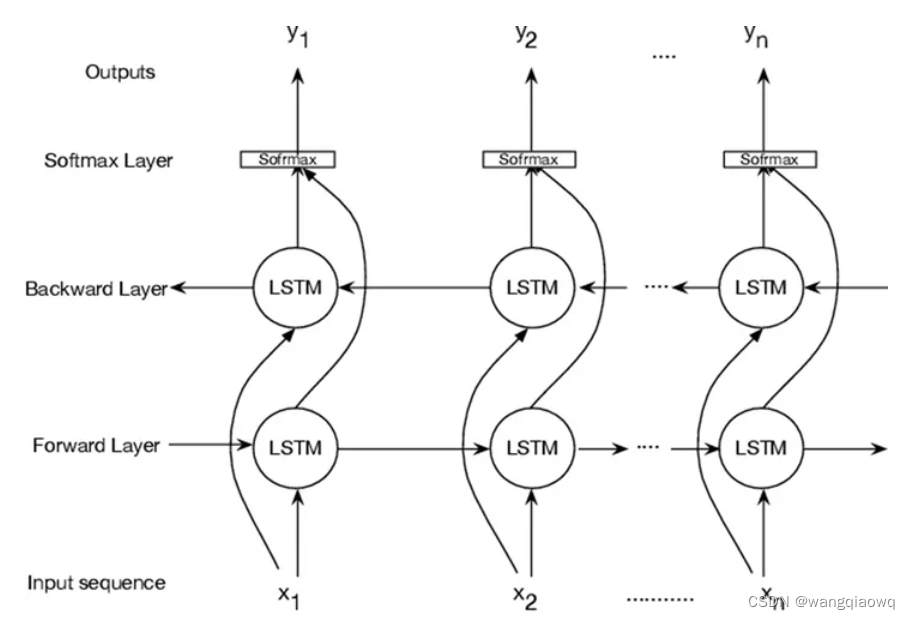
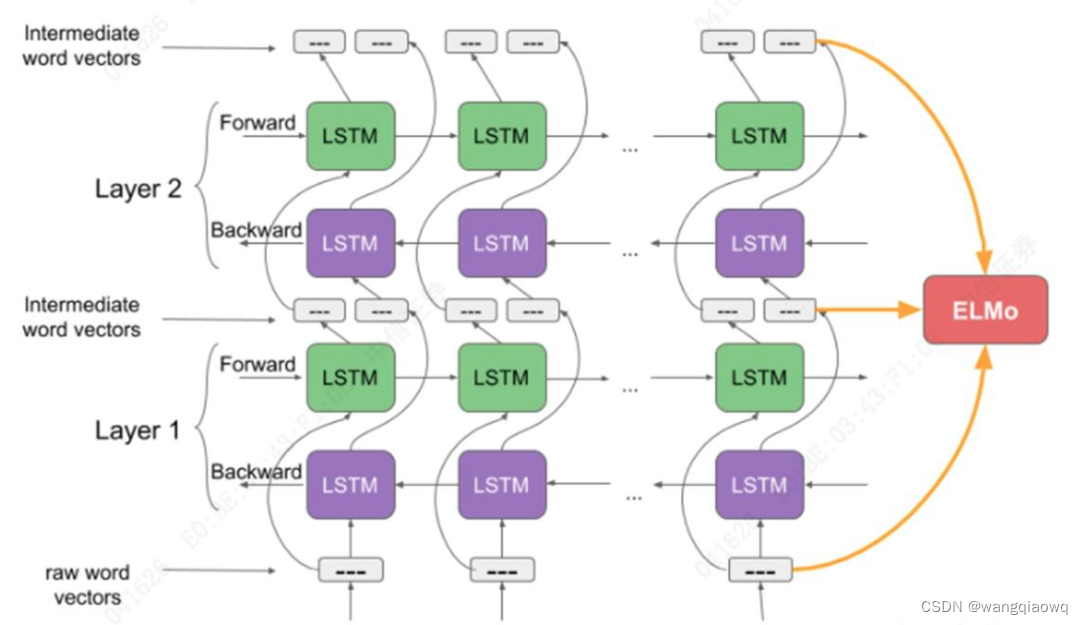
语言模型解决上下文问题
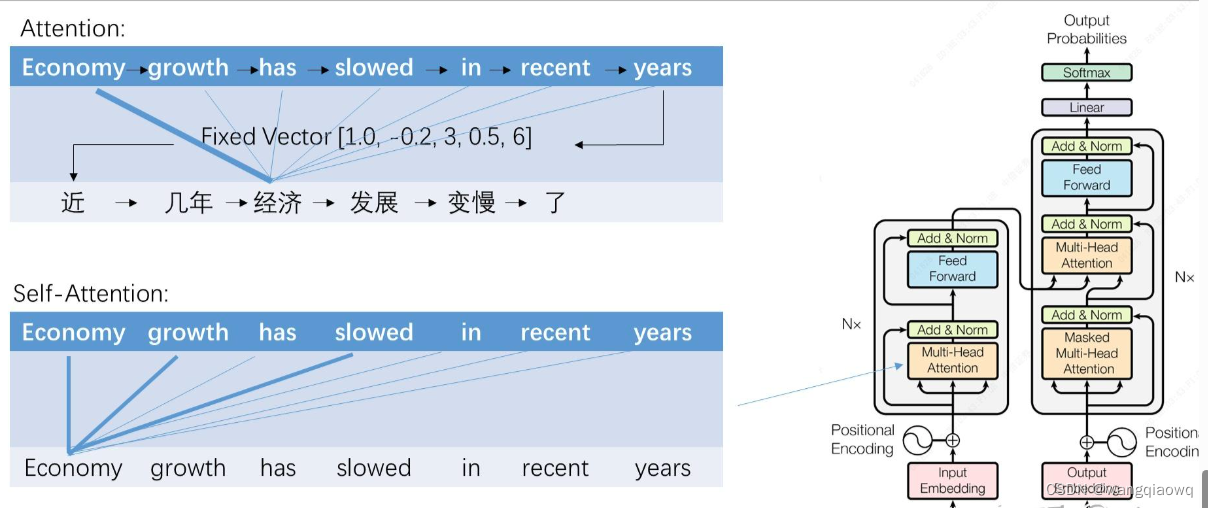
Transformer大幅提升效果
预训练-微调时代
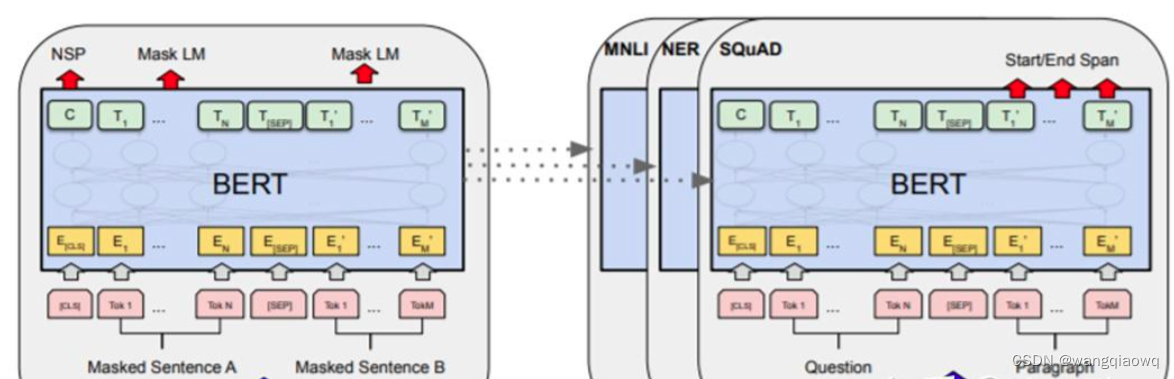
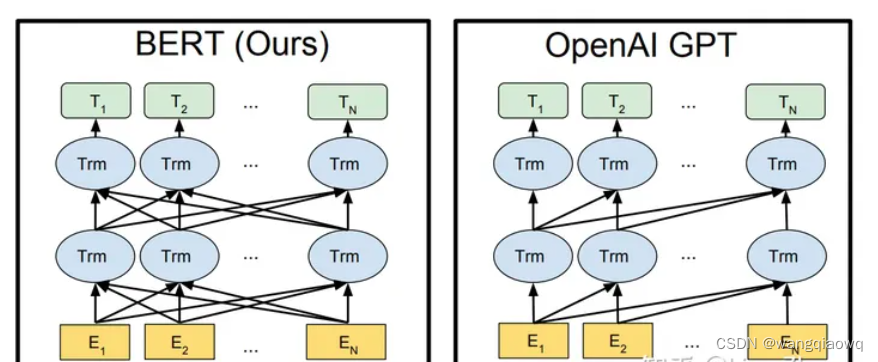
大语言模型时代:Prompt代替微调

大模型的涌现能力:大力出奇迹
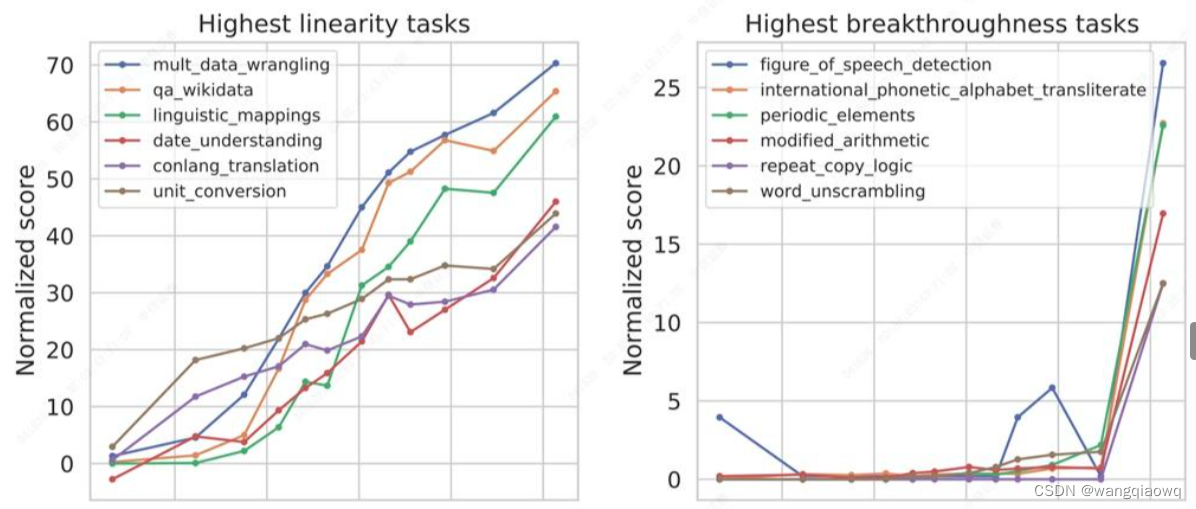
引爆全球:逻辑思维和对话能力的增强
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






