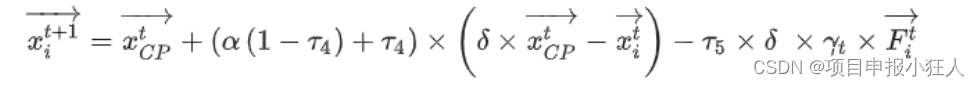基于协同过滤算法的图书管理系统

一、简介(v信:1257309054)
根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐,种被称为基于协同过滤的推荐。
本系统使用了三种推荐算法:基于用户的协同过滤算法、基于物品的协同过滤算法、基于机器学习k–means聚类的过滤算法,以及三种算法的混合推荐算法。

二、使用到的技术
1、Django的MTV架构
三、开发流程
四、主要功能
1、前台用户
1.1、注册界面

1.2、登录界面

1.3、全部书籍界面

1.4、具体书籍

1.5、新书速递
1.6、热门书籍
1.7、图书分类

1.8、猜你喜欢
1.9、借阅书籍

1.20、购买书籍、购物车

1.21、个人中心

2、后台管理

五、算法说明
1、基于用户协同过滤推荐算法



2、基于物品协同过滤推荐算法
2.1、基于⽤户的协同过滤算法(UserCF)
2.2、基于物品的协同过滤算法(ItemCF)
2.3、算法核心
2.4、流程
2.5、构建用户与物品的对应关系表
2.6、构建物品与物品的关系矩阵(共现矩阵)
2.7、计算相似矩阵

2.8、给用户推荐物品
3、基于机器学习K-means聚类推荐算法
六、程序文件说明

七、数据库表说明

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。