前言
2023年5月18日清华&智谱AI发布并开源VisualGLM-6B以来,清华KEG&智谱AI潜心打磨,又开发并开源了更加强大的多模态大模型CogVLM。CogVLM基于对视觉和语言信息之间融合的理解,是一种新的视觉语言基础模型 。CogVLM 可以在不牺牲任何 NLP 任务性能的情况下,实现视觉语言特征的深度融合,替换以往浅融合模式,使用重要的视觉专家模块。为此,我在阅读了论文后做出该论文解读内容,能帮助更多读者学习。
论文链接:点击这里
代码地址:点击这里
网页测试demo:点击这里
个人原文重点翻译:点击这里
一、摘要
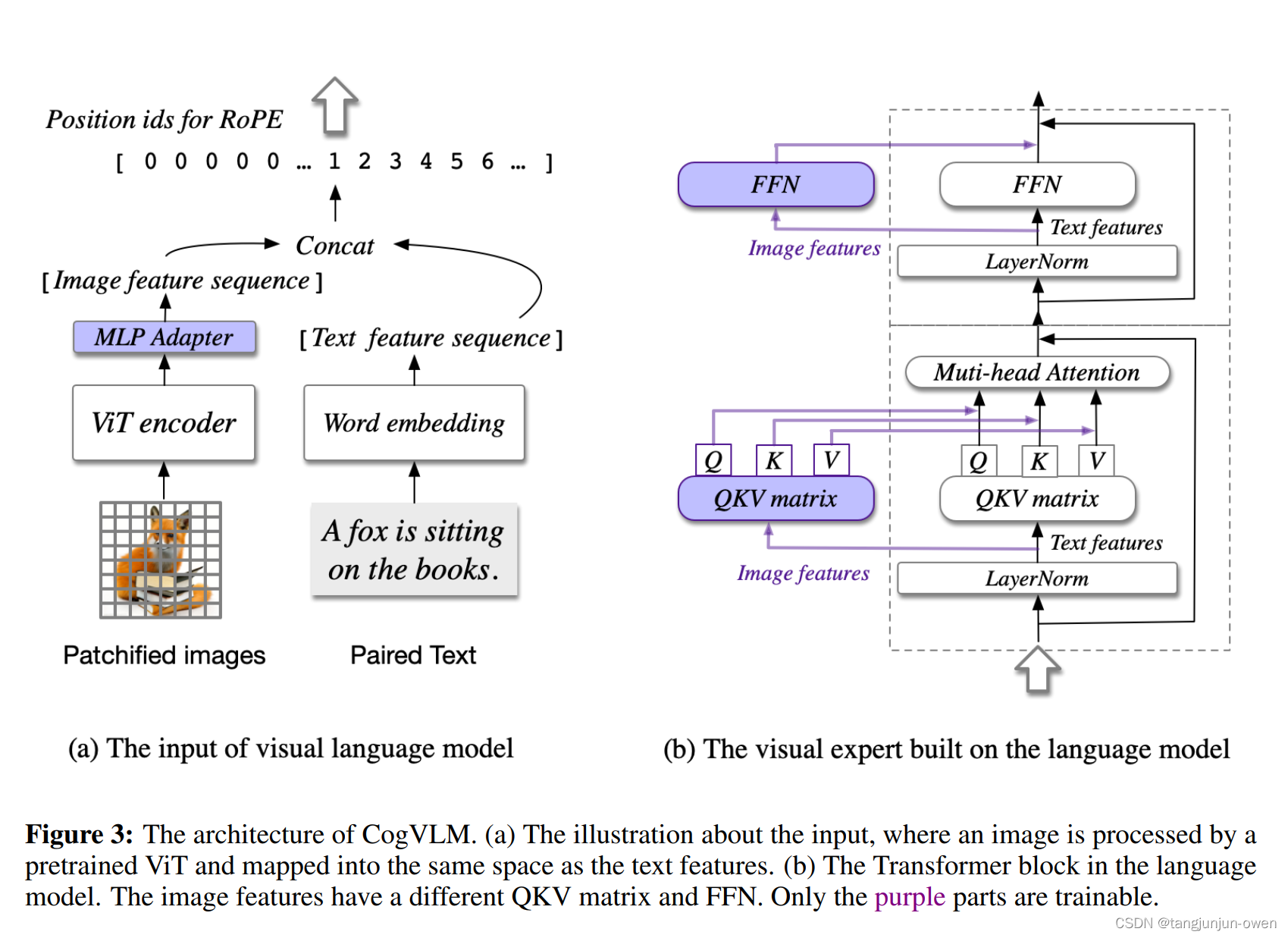
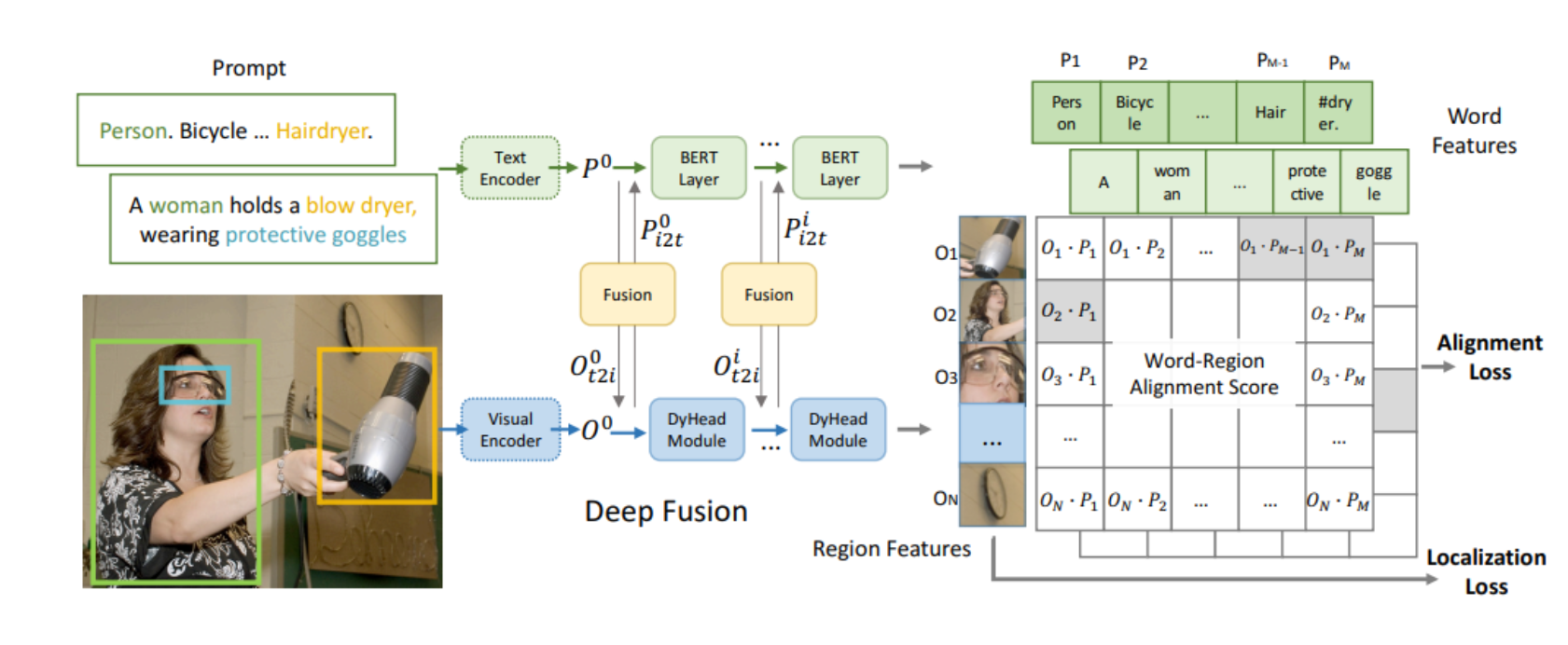
我们提出了CogVLM模型,一个更强的open–sorce视觉语言基准模型。该模型不同于现有受欢迎大模型,是直接使图像特征嵌入语言空间浅对齐的方法。而CogVLM缩小语言模型与图像编码特征融合的gap,在这里语言模型是已训练好且冻结的模型,图像特征编码是使用了attention and FFN layer构建的可训练视觉专家模块编码图像特征。结果是,CogVLM能深度融合视觉语言特征,而不牺牲NLP任务新能。 CogVLM在10中 cross–modal基准上实现最先进性能,基准包含…

二、引言
VLMS模式是功能强大且应用很广的。很多视觉和多模态任务看做是token的预测,如图像说明、视觉问答、视觉定位与分割等任务。作者特别说到之前方法,以BLIP-2举列,The popular shallow alignment methods represented by BLIP-2,是一个浅对齐模型,使用Q-FORMER结构,速度快但性能不够优秀。引出弱的视觉理解能力导致模型幻觉问题,提到CogVLM保持NLP语言模型能力同时添加一个强大视觉理解模型。为此,作者提到的模型可以解决这些问题,实现深层次融合,作者也提到P-tuning与lora方法,更多细节作者说了2点:
More detailed reasons for the performance degradation of p-tuning and shallow alignment include:
第一点:训练好的语言模型权重被冻结。视觉特征嵌入文本空间无法完美匹配,在多个transformer后,视觉特征无法在更深层匹配。
第二点:在预训练期间,先前视觉描述(如 writing style and caption length) 通过粗浅的align方法编码为视觉特征,在视觉与文本一致性是很差的。