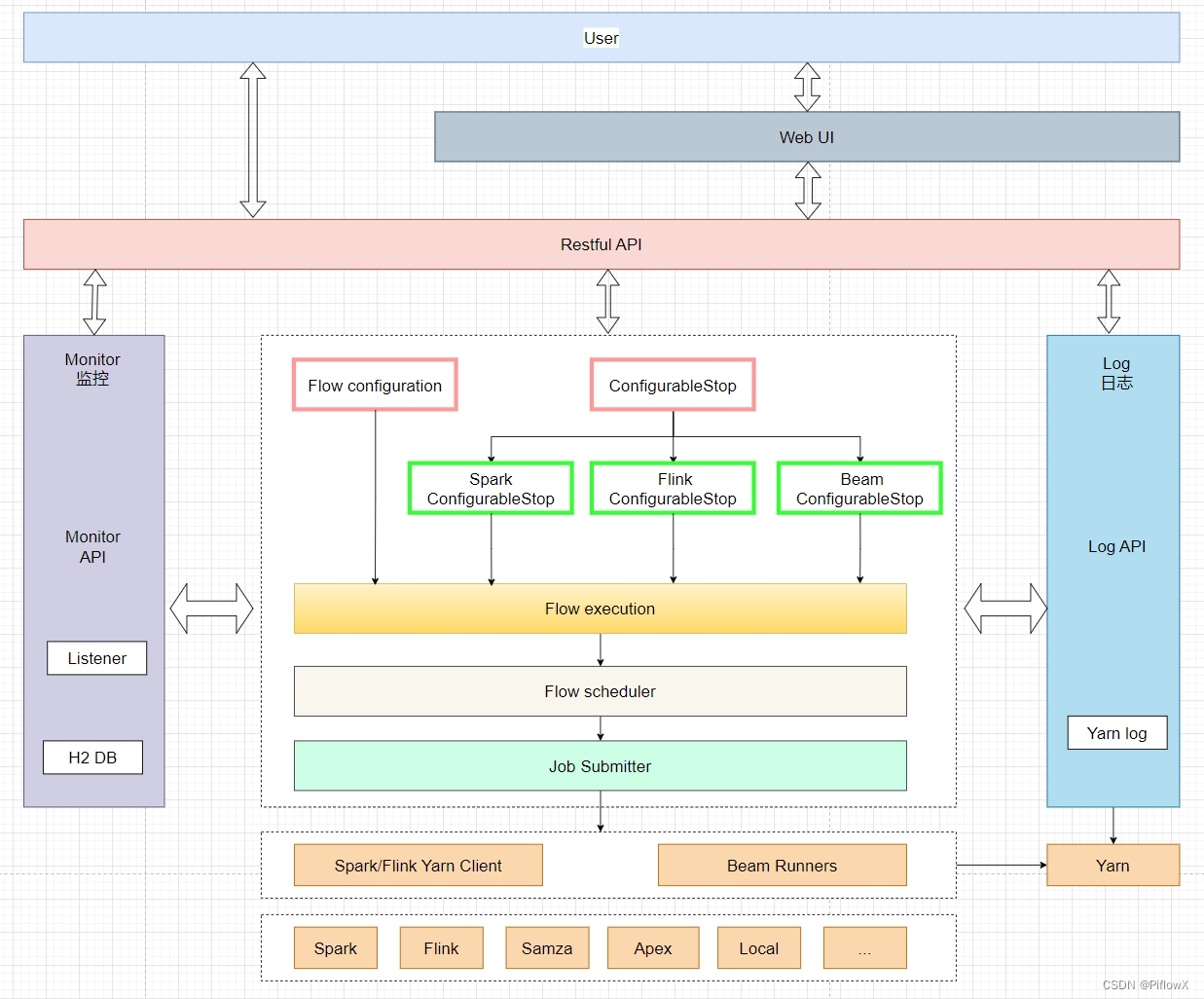
1.概览
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接一个外部数据目录时,我们只能在Database 或 Table 层级进行对接。比如通过 create external table 的方式创建一个外部数据目录中的表的映射,或通过 create external database 的方式映射一个外部数据目录中的 Database。如果外部数据目录中的 Database 或 Table 非常多,则需要用户手动进行一一映射,使用体验不佳。
而新的 Multi-Catalog 功能在原有的元数据层级上,新增一层Catalog,构成 Catalog -> Database -> Table 的三层元数据层级。其中,Catalog 可以直接对应到外部数据目录。目前支持的外部数据目录包括:
- Apache Hive
- Apache Iceberg
- Apache Hudi
- Elasticsearch
- JDBC: 对接数据库访问的标准接口(JDBC)来访问各式数据库的数据。
- Apache Paimon(Incubating)
该功能将作为之前外表连接方式(External Table)的补充和增强,帮助用户进行快速的多数据目录联邦查询。
这篇教程将展示如何使用 Flink + paimon + Doris 构建实时湖仓一体的联邦查询分析,Doris 2.0.3 版本提供了 的支持,本文主要展示 Doris 和 paimon 怎么使用,同时本教程整个环境是都基于伪分布式环境搭建,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
2. 环境
3. 安装
- 下载 Flink 1.17.1
wget https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
## 解压安装
tar zxf flink-1.17.1-bin–scala_2.12.tgz - 下载相关的依赖到 Flink/lib 目录
cp /Users/zhangfeng/hadoop/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.6.jar ./lib/
wget https://repo1.maven.org/maven2/org/apache/paimon/paimon-flink-1.17/0.5.0-incubating/paimon-flink-1.17-0.5.0-incubating.jar
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.2/flink-sql-connector-mysql-cdc-2.4.2.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.3_2.12/1.17.1/flink-sql-connector-hive-3.1.3_2.12-1.17.1.jarenv.java.opts.all: "-Dfile.encoding=UTF-8"
classloader.check-leaked-classloader: false
taskmanager.numberOfTaskSlots: 3
execution.checkpointing.interval: 10s
state.backend: rocksdb
state.checkpoints.dir: hdfs://zhangfeng:9000/flink/myckp
state.savepoints.dir: hdfs://zhangfeng:9000/flink/savepoints
state.backend.incremental: truebin/start-cluster.sh
bin/sql-client.sh embedded
set 'sql-client.execution.result-mode' = 'tableau';
Catalog
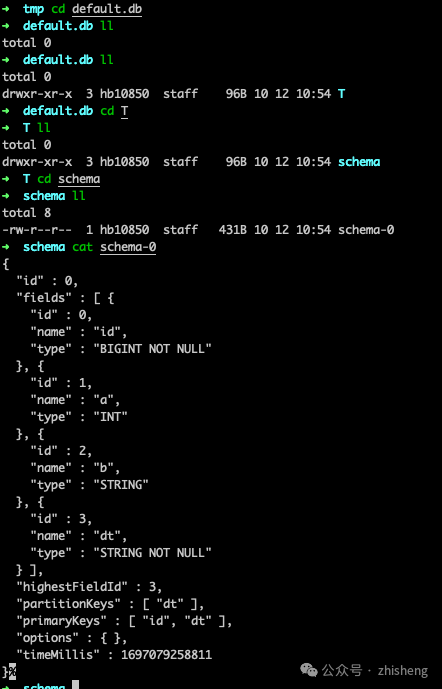
Paimon Catalog可以持久化元数据,当前支持两种类型的metastore
文件系统
下面的 Flink SQL 注册并使用一个名为 paimon_catalog 的catalog。元数据和表文件存放在hdfs://localhost:9000/paimon/data下
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs://localhost:9000/paimon/data'
);
show catalogs;
Hive Catalog
我们也可以直接使用 hive metastore 来存储 paimon 元数据。
CREATE CATALOG paimon_hive WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://localhost:9083',
'hive-conf-dir' = '/Users/zhangfeng/hadoop/apache-hive-3.1.3-bin/conf/',
'warehouse' = 'hdfs://localhost:9000/paimon/hive'
);
show catalogs;
USE CATALOG paimon_hive;
CREATE TABLE test_paimon_01 (
userid BIGINT,
age INT,
address STRING,
regiter_dt STRING ,
PRIMARY KEY(userid, regiter_dt) NOT ENFORCED
) PARTITIONED BY (regiter_dt);
show tables
下面我们演示怎么基于Flink CDC 快速实时同步 MySQL 表的数据到 Paimon表里。
这里首先你的MySQL 数据库要开启 binlog,具体的方法网上很多,这里不在叙述。
MySQL 表:
CREATE DATABASE emp_1;
USE emp_1;
CREATE TABLE employees_1 (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
INSERT INTO `employees_1` VALUES (10055,'1956-06-06','Georgy','Dredge','M','1992-04-27'),
(10056,'1961-09-01','Brendon','Bernini','F','1990-02-01'),
(10057,'1954-05-30','Ebbe','Callaway','F','1992-01-15'),
(10058,'1954-10-01','Berhard','McFarlin','M','1987-04-13'),
(10059,'1953-09-19','Alejandro','McAlpine','F','1991-06-26'),
(10060,'1961-10-15','Breannda','Billingsley','M','1987-11-02'),
(10061,'1962-10-19','Tse','Herber','M','1985-09-17'),
(10062,'1961-11-02','Anoosh','Peyn','M','1991-08-30'),
(10063,'1952-08-06','Gino','Leonhardt','F','1989-04-08'),
(10064,'1959-04-07','Udi','Jansch','M','1985-11-20'),
(10065,'1963-04-14','Satosi','Awdeh','M','1988-05-18'),
(10066,'1952-11-13','Kwee','Schusler','M','1986-02-26'),
(10067,'1953-01-07','Claudi','Stavenow','M','1987-03-04'),
(10068,'1962-11-26','Charlene','Brattka','M','1987-08-07'),
(10069,'1960-09-06','Margareta','Bierman','F','1989-11-05'),
(10070,'1955-08-20','Reuven','Garigliano','M','1985-10-14'),
(10071,'1958-01-21','Hisao','Lipner','M','1987-10-01'),
(10072,'1952-05-15','Hironoby','Sidou','F','1988-07-21'),
(10073,'1954-02-23','Shir','McClurg','M','1991-12-01'),
(10074,'1955-08-28','Mokhtar','Bernatsky','F','1990-08-13'),
(10075,'1960-03-09','Gao','Dolinsky','F','1987-03-19'),
(10076,'1952-06-13','Erez','Ritzmann','F','1985-07-09'),
(10077,'1964-04-18','Mona','Azuma','M','1990-03-02'),
(10078,'1959-12-25','Danel','Mondadori','F','1987-05-26'),
(10079,'1961-10-05','Kshitij','Gils','F','1986-03-27'),
(10080,'1957-12-03','Premal','Baek','M','1985-11-19'),
(10081,'1960-12-17','Zhongwei','Rosen','M','1986-10-30'),
(10082,'1963-09-09','Parviz','Lortz','M','1990-01-03'),
(10083,'1959-07-23','Vishv','Zockler','M','1987-03-31'),
(10084,'1960-05-25','Tuval','Kalloufi','M','1995-12-15');在Flink sql–client 下创建 MySQL CDC 表:
CREATE TABLE employees_source (
database_name STRING METADATA VIRTUAL,
table_name STRING METADATA VIRTUAL,
emp_no int NOT NULL,
birth_date date,
first_name STRING,
last_name STRING,
gender STRING,
hire_date date,
PRIMARY KEY (`emp_no`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = 'zhangfeng',
'database-name' = 'emp_1',
'table-name' = 'employees_1'
);使用Create table as select 创建Paimon表,并将数据实时同步到Paimon表里:
create table mysql_to_paimon_01 as select * from default_catalog.default_database.employees_source;查看Job

我们这个时候可以在Flink sql-client 下查询 paimon ,看到 Paimon 表里已经有数据了。

5. Doris On Paimon
Doris 提供了 Paimon 的 catalog 支持,我们可以通过这种方式,通过Doris 快速的去读 Paimon 表的数据,同时也可以通过 catalog 方式将 paimon 表的数据迁移到 Doris 表里
5.1 Doris 整合查询Paimon表
CREATE CATALOG `paimon_hdfs` PROPERTIES (
"type" = "paimon",
"warehouse" = "hdfs://localhost:9000/paimon/hive",
"hadoop.username" = "hadoop"
);
CREATE CATALOG `paimon_hms` PROPERTIES (
"type" = "paimon",
"paimon.catalog.type" = "hms",
"warehouse" = "hdfs://localhost:9000/paimon/hive",
"hive.metastore.uris" = "thrift://localhost:9083"
);创建成功之后我们通过 show catalogs方式可以看到我们创建好的 paimon catalog;
mysql> show catalogs;
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| CatalogId | CatalogName | Type | IsCurrent | CreateTime | LastUpdateTime | Comment |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| 1308010 | hive | hms | | 2023-11-17 09:42:22.872 | 2023-11-17 09:42:46 | NULL |
| 1326307 | hudi | hms | | 2023-11-27 11:33:22.231 | 2023-11-27 11:33:35 | NULL |
| 0 | internal | internal | | UNRECORDED | NULL | Doris internal catalog |
| 35689 | jdbc | jdbc | | 2023-11-03 12:52:24.695 | 2023-11-03 12:52:59 | NULL |
| 38003 | mysql | jdbc | | 2023-11-07 11:46:40.006 | 2023-11-07 11:46:54 | NULL |
| 1329142 | paimon_hdfs | paimon | | 2023-11-27 14:06:13.744 | 2023-11-27 14:06:41 | |
| 1328144 | paimon_hms | paimon | yes | 2023-11-27 14:00:32.925 | 2023-11-27 14:00:44 | NULL |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
7 rows in set (0.00 sec)切换 paimon catalog,通过下面这些操作我们可以看到我们在 paimon 里创建的表
mysql> switch paimon_hdfs;
Query OK, 0 rows affected (0.00 sec)
mysql> show databases;
+----------+
| Database |
+----------+
| default |
+----------+
1 row in set (0.02 sec)
mysql> use default;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+--------------------------+
| Tables_in_default |
+--------------------------+
| example_tbl_partition_01 |
| example_tbl_unique_01 |
| mysql_to_paimon_01 |
| test_paimon_01 |
+--------------------------+
4 rows in set (0.00 sec)通过 Doris 查询 Paimon 表
select * from mysql_to_paimon_01;
5.2 将Paimon 表的数据导入到 Doris
我们也可以快速的利用catalog 方式将 paimon 数据迁移到 Doris 里,我们可以使用 CATS方式:
create table doris_paimon_01
PROPERTIES("replication_num" = "1") as select * from paimon_hdfs.`default`.mysql_to_paimon_01;
注意:
org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "hdfs"需要再 hdfs 需要再core–site.xml 文件中加上下面的配置:
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>6. 总结
是不是使用非常简单,快快体验Doris 湖仓一体,联邦查询的能力,来加速你的数据分析性能
原文地址:https://blog.csdn.net/hf200012/article/details/134707352
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_33782.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!