五、Spark Shuffle文件寻址
1、Shuffle文件寻址
1)、MapOutputTracker
MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
2)、BlockManager
BlockManager块管理者,是Spark架构中的一个模块,也是一个主从架构。
BlockManagerMaster会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave传输或者删除数据。
BlockManagerSlave会与BlockManagerSlave之间通信。
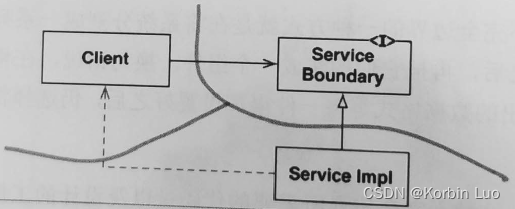
3)、Shuffle文件寻址图
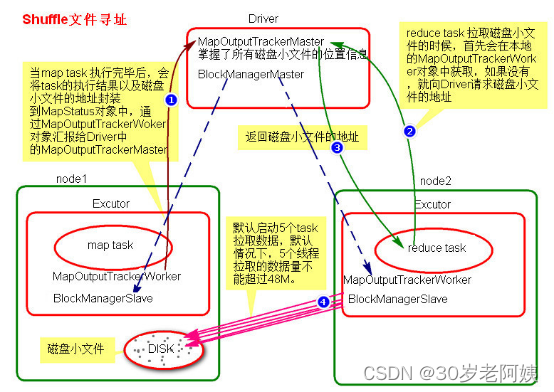
4)、Shuffle文件寻址流程
六、Spark 内存管理和Shuffle优化
1、Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
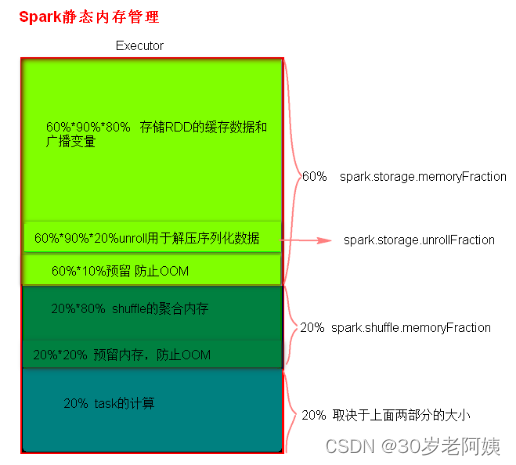
1)、静态内存管理分布图
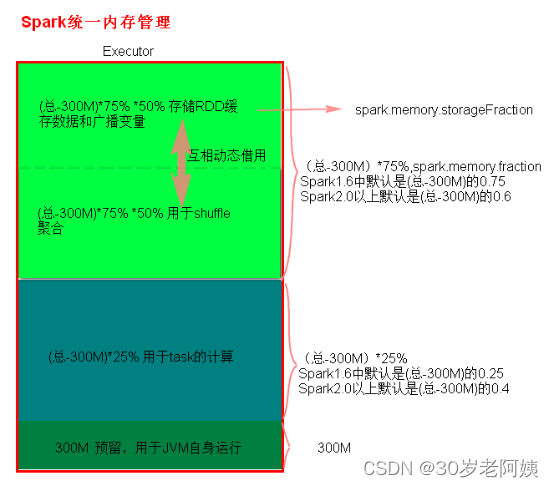
2)、统一内存管理分布图
3)、reduce 中OOM如何处理?
2、Shuffle调优
1)、SparkShuffle调优配置项如何使用?
2)、Shuffle调优附件
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。