产品概述

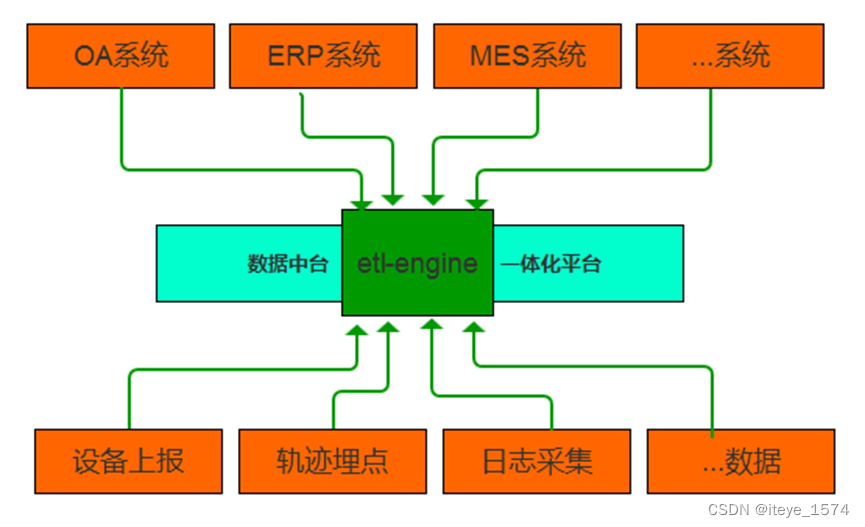
应用场景
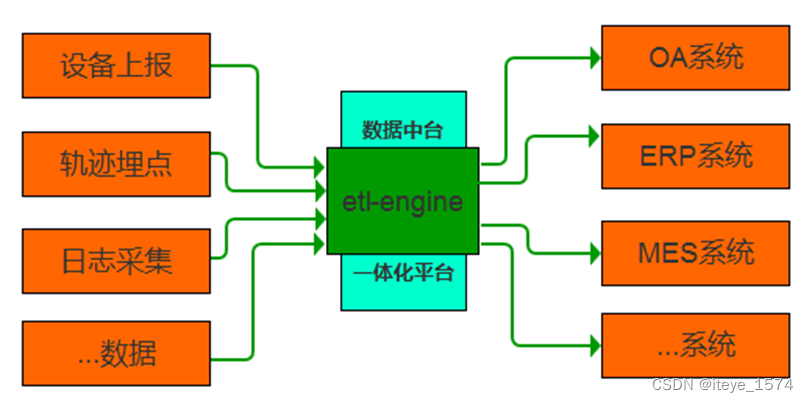
异构系统数据交换
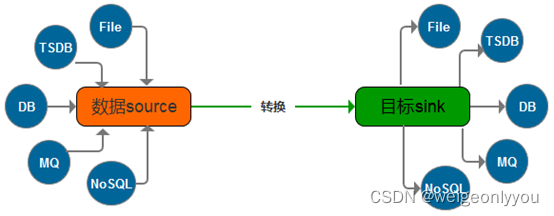
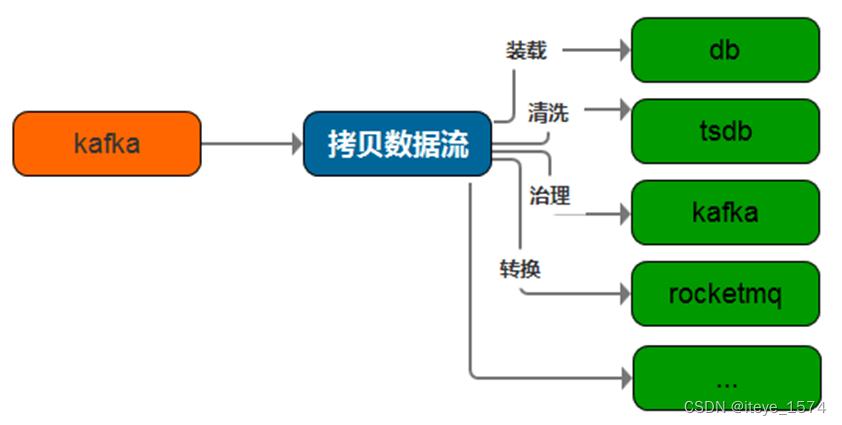
数据分发网关
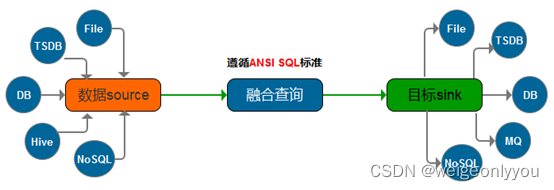
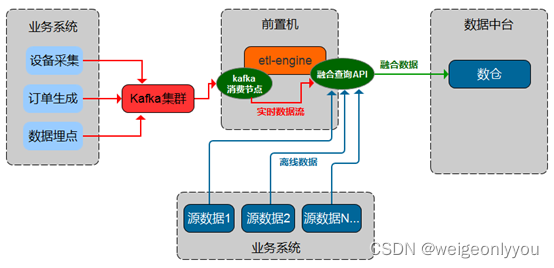
融合查询
以往数据迁移过程是从一个A数据源到抽取、转换、再装载到另一个B数据源的过程,然后再做查询分析,即将多个业务系统产生的数据抽取到数据仓库中,然后再对数据仓库中事实表和维表进行统计查询及分析,相当于是两阶段操作。
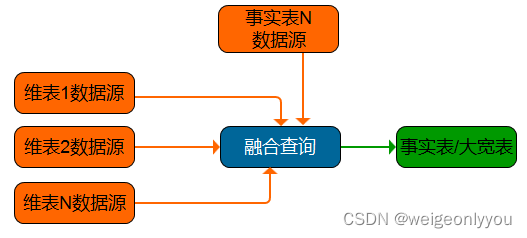
融合查询可同时从多个业务系统中读取数据,并在内存中对已读取的数据做数据关联查询,最终将关联后的结果输出到数据仓库,对比上述场景是一个轻量级的一阶段操作,常用在将多个维表数据转换成一个大宽表的场景。
 ### 流式计算
### 流式计算
互联网诞生之初虽然数据量暴增,单日事实表条数达千万级别,但客户需求场景更多是“t+1”形式,只需对当日、当周、当月数据进行分析,这些诉求仅离线分析就可满足。
随着大数据领域不断发展,企业对于业务场景的诉求也从离线的满足转到高实时性的要求,数栈产品也在这一过程中进行着不断的迭代升级,随之数据栈诞生了kafka + flink组合实现对动态数据进行流式计算,同时kafka + etl-engine(融合计算的加持)组合也实现了轻量级的流式计算引擎。
产品优势
支持部署模式
支持操作系统
支持数据源类型
产品试用地址
github地址
https://github.com/hw2499/etl-engine
技术支持
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。