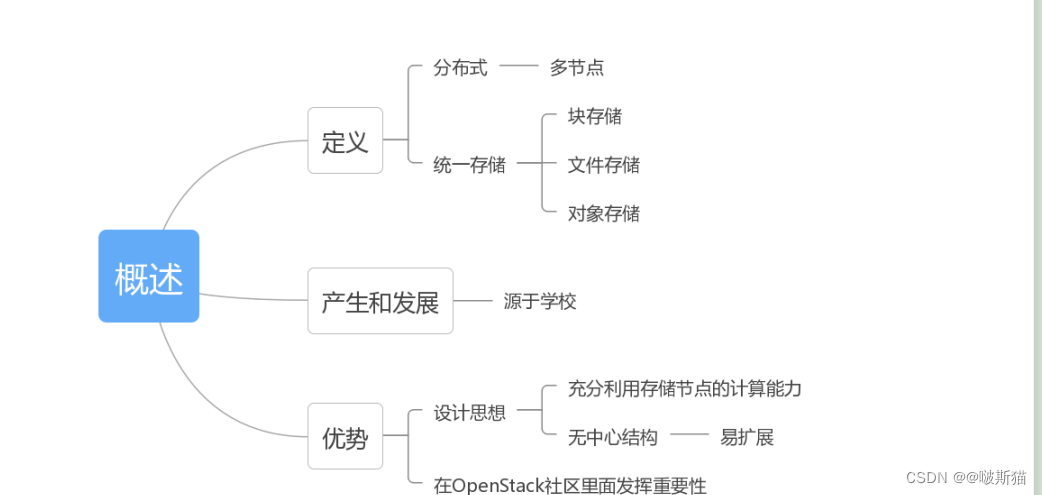
Ceph简介
Ceph是一种分布式存储系统,所谓分布式,指的是Ceph可以部署在多台服务器上,通过多台服务器并行处理来对外提供高性能的读写块。
同时Ceph除了能提供块存储,还可以提供文件存储、对象存储。
实际上Ceph不是一个才出现的开源项目,而是走过了 7年的路程,那么Ceph有什么样的优势呢?
1)Ceph的优势在于它的设计思想:无需查表,算算就好。也就是说它可以充分利用服务器的计算能力,消除了对单一中心节点的依赖,可以实现真正的无中心结构,这样Ceph的可靠性和可扩展性都很强,而且客户端访问延迟也比较少。
2)Ceph在OpenStack开源社区中备受重视。OpenStack是现在最为流行的开源云操作系统,目前Ceph已经成为OpenStack中呼声最高的开源存储方案之一。
- Ceph的产生和发展
1)一般来说开源项目的来源主要有两个,一个是从学校里面的一些课题,一个是企业里面的大牛对产品进行开源。Ceph就是典型的学院派,它起源于Sage Weil博士期间的课题,使用C++开发。
2)2011年Sage创建了Inktank公司以主导Ceph的开发和社区维护。
(1)对象存储:
也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
(2)块存储:
这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口,如 Sheepdog,AWS 的 EBS,青云的云硬盘和阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph面向块存储的接口)。在常见的存储中 DAS、SAN 提供的也是块存储;
(3)文件系统存储:
通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力,如 Ceph 的 CephFS (CephFS是Ceph面向文件存储的接口),但是有时候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储;
1)Ceph最初的目标场景是大规模、分布式存储系统,Ceph起源于04年,那个时候CPU还是单核,硬盘容量只有几十GB,所以当时的想法是至少能承载PB级别的数据。
2)Ceph与传统的存储不太一样的地方在于,它的眼光是动态的,首先是存储规模是会变的。也就是可以根据业务的规模扩展存储的容量。
存储的设备会变。我们使用的不是高可靠性的小机,而是可能发生故障的x86服务器,所以极有可能某个节点发生故障,那么需要在软件层面进行保障。
3)存储数据也会变。也就是,需要考虑到存储的数据可能被增删读写,而不是一层不变的。
4)Ceph的目标场景,它希望能应对存储容量会变,同时可以对数据进行快速的增删读写的场景,而且底层的硬件主要使用廉价的X86服务器,使用上层软件来保证可靠性。
(1)高性能:
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
(2)高可用性:
(3)高可扩展性:
b. 扩展灵活。
(4)特性丰富:
(5)高可靠性:
a.首先存储在里面的数据不会丢失,同时数据在写入的时候,需要保证原子性。
b.另外因为数据会经常迁移,而且故障了以后会有恢复的过程,我们希望Ceph能自动完成这些工作,而不需要人为参与。
二、ceph组件介绍
(1)Monitors:监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 “ceph mon dump“查看 monitor map。
(2)MDS(Metadata Server):Ceph 元数据,主要保存的是Ceph文件系统的元数据。注意:ceph的块存储和ceph对象存储都不需要MDS。
(3)OSD:即对象存储守护程序,但是它并非针对对象存储。是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor
(4)RADOS:Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
(5)librados:librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
(6)RADOSGW:网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift(openstack) 兼容的RESTful API接口。
(7)RBD:块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
(8)CephFS:Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
三、ceph数据存储过程
1.无论使用哪种存储方式(对象、块、文件系统),存储的数据都会被切分成Objects。Objects size大小可以由管理员调整,通常为2M或4M。每个对象都会有一个唯一的OID,由ino与ono生成。
ino:即是文件的File ID,用于在全局唯一标识每一个文件
(2)Object -> PG映射,hash(oid) & mask -> pgid
3.pool:是ceph存储数据时的逻辑分区,它起到namespace的作用。每个pool包含一定数量(可配置) 的PG。PG里的对象被映射到不同的Object上。pool是分布到整个集群的。 pool可以做故障隔离域,根据不同的用户场景不统一进行隔离。
四、ceph IO流程
3)client 连接上monitor,获取集群map信息。
4)client 读写io 根据crshmap 算法请求对应的主osd数据节点。
7)主节点及副本节点写入状态都成功后,返回给client,io写入完成。
2)同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
7)osd2三份数据都写入成功返回给client, 此时client io读写完毕。
五、ceph 命令
#ceph -s#ceph osd tree#ceph osd lspools
4、创建pool
#ceph osd pool create vms 1024
#ceph osd pool delete data #会提示确认信息(增加命令,如下)
#ceph osd pool delete data data --yes-i-really-really-mean-it#ceph osd dump | grep pool六、ceph对接openstack环境
#useradd cent && echo "123" | passwd --stdin cent
#echo -e 'Defaults:cent !requirettyncent ALL = (root) NOPASSWD:ALL' | tee /etc/sudoers.d/ceph
#chmod 440 /etc/sudoers.d/ceph#yum install python-rbd
#yum install ceph-common3、在ceph部署节点上为openstack节点安装ceph
#ceph-deploy install controller
#ceph-deploy admin controller#sudo chmod 644 /etc/ceph/ceph.client.admin.keyring在一个ceph节点上创建pool
#ceph osd pool create images 1024
#ceph osd pool create vms 1024
#ceph osd pool create volumes 1024
#ceph osd lspools6、在ceph集群中创建glance和cinder用户,只需在一个ceph节点上操作即可
#ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images'
#ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images'7、拷贝ceph-ring, 只需在一个ceph节点上操作即可:
#ceph auth get-or-create client.glance > /etc/ceph/ceph.client.glance.keyring
#ceph auth get-or-create client.cinder > /etc/ceph/ceph.client.cinder.keyring#chown glance:glance /etc/ceph/ceph.client.glance.keyring
#chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring9、更改libvirt权限(只需在nova–compute节点上操作即可,每个计算节点都做)
#uuidgen
#940f0485-e206-4b49-b878-dcd0cb9c70a4
cat > secret.xml <<EOF
<secret ephemeral='no' private='no'>
<uuid>940f0485-e206-4b49-b878-dcd0cb9c70a4</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
EOF将 secret.xml 拷贝到所有compute节点,并执行::
#virsh secret-define --file secret.xml
#ceph auth get-key client.cinder > ./client.cinder.key
#virsh secret-set-value --secret 940f0485-e206-4b49-b878-dcd0cb9c70a4 --base64 $(cat ./client.cinder.key)10、配置Glance, 在所有的controller节点上做如下更改:
#vim /etc/glance/glance-api.conf
[DEFAULT]
default_store = rbd
[glance_store]
stores = rbd
default_store = rbd
rbd_store_pool = images
rbd_store_user = glance
rbd_store_ceph_conf = /etc/ceph/ceph.conf
rbd_store_chunk_size = 8
#systemctl restart openstack-glance-api.service创建image验证:
#openstack image create "cirros" --file cirros-0.3.3-x86_64-disk.img.img --disk-format qcow2 --container-format bare --public
#rbd ls images #有输出镜像说明成功了11、配置cinder(/etc/cinder/cinder.conf)
[DEFAULT]
enabled_backends = lvm,ceph
[ceph]
volume_driver = cinder.volume.drivers.rbd.RBDDriver
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = false
rbd_max_clone_depth = 5
rbd_store_chunk_size = 4
rados_connect_timeout = -1
glance_api_version = 2
rbd_user = cinder
rbd_secret_uuid = 940f0485-e206-4b49-b878-dcd0cb9c70a4
volume_backend_name=ceph
#systemctl restart openstack-cinder-api.service openstack-cinder-scheduler.service openstack-cinder-volume.service
#rbd ls volumes12、配置nova(/etc/nova/nova.conf)
[libvirt]
virt_type=qemu
images_type = rbd
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_user = cinder
rbd_secret_uuid = 940f0485-e206-4b49-b878-dcd0cb9c70a4
#systemctl restart openstack-nova-api.service openstack-nova-consoleauth.service openstack-nova-scheduler.service openstack-nova-compute.service openstack-nova-cert.service七、ceph添加/删除osd
1、添加osd
列出节点磁盘:#ceph-deploy disk list rab1
擦净节点磁盘:
#ceph-deploy disk zap rab1 /dev/sbd(或者)ceph-deploy disk zap rab1:/dev/vdb1#ceph-deploy osd prepare rab1:/var/lib/ceph/osd1#ceph-deploy osd activate rab1:/var/lib/ceph/osd12、删除osd
(1)把 OSD 踢出集群
#ceph osd out osd.4#systemctl stop ceph-osd@4.service
#systemctl disable ceph-osd@4.service(3)删除 CRUSH 图的对应 OSD 条目,它就不再接收数据了
#ceph osd crush remove osd.4#ceph auth del osd.4(5)删除osd.4
#ceph osd rm osd.4(1)关闭ceph集群数据迁移(osd硬盘故障,状态变为down)
#for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd set $i;done(2)定位故障osd
#umount /var/lib/ceph/osd/ceph-5
#ceph osd crush remove osd.5
(5)删除故障osd
#ceph osd rm 5
(7)添加新的osd(cent用户)
#ceph-deploy osd create —data /dev/sdd node3
(8)待新osd添加crush map后,重新开启集群禁用标志
#for i in noout nobackfill norecover noscrub nodeep-scrub;do ceph osd unset $i;done
ceph集群经过一段时间的数据迁移后,恢复active+clean状态
八.Ceph的安装和部署
该环境使用三个虚机作为Ceph节点,每个节点上增加两个虚拟磁盘 vda 和 vdb 作为 OSD 存储磁盘,每个节点上安装 MON,前两个节点上安装 MDS。三个节点使用物理网络进行通信。
(0)准备好三个节点 ceph{1,2,3}:安装操作系统、设置 NTP、配置 ceph1 可以通过 ssh 无密码访问其余节点(依次运行 ssh-keygen,ssh–copy-id ceph2,ssh–copy-id ceph3,修改 /etc/ssh/sshd_config 文件中的 PermitRootLogin yes 来使得 ssh 支持 root 用户)
(1)在 ceph1 上安装 ceph-deploy,接下来会使用这个工具来部署 ceph 集群
(2)在ceph 上,运行 ceph-deploy install ceph{1,2,3} 命令在各节点上安装 ceph 软件。安装好后可以查看 ceph 版本:
root@ceph1:~# ceph -v
ceph version 0.80.10 (ea6c958c38df1216bf95c927f143d8b13c4a9e70)
ceph-deploy mon create ceph{1,2,3}
ceph-deploy mon create-initial
{“name”:”ceph1″,”rank“:0,”state“:”leader“,”election_epoch”:16,”quorum”:[0,1,2],”outside_quorum”:[],”extra_probe_peers”:[],”sync_provider“:[],”monmap“:{“epoch”:1,”fsid”:”4387471a-ae2b-47c4-b67e-9004860d0fd0″,”modified”:”0.000000″,”created”:”0.000000″,”mons”:[{“rank“:0,”name”:”ceph1″,”addr“:”192.168.1.194:6789/0”},{“rank“:1,”name”:”ceph2″,”addr“:”192.168.1.195:6789/0”},{“rank“:2,”name”:”ceph3″,”addr“:”192.168.1.218:6789/0”}]}}
(4)在各节点上准备数据盘,只需要在 fdisk -l 命令输出中能看到数据盘即可,不需要做任何别的操作,然后在 ceph1 上执行如下命令添加 OSD
ceph-deploy –overwrite–conf osd prepare ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda
ceph-deploy –overwrite–conf osd activate ceph1:/data/osd:/dev/vda ceph2:/data/osd:/dev/vda ceph3:/data/osd:/dev/vda
ceph-deploy –overwrite–conf osd prepare ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb
ceph-deploy –overwrite-conf osd activate ceph1:/data/osd2:/dev/vdb ceph2:/data/osd2:/dev/vdb ceph3:/data/osd2:/dev/vdb
格式: ceph-deploy osd prepare {node-name}:{data-disk}[:{journal-disk}]
其中,node-name 表示待创建 OSD 的目标 Ceph 节点;data-disk 表示 OSD 的数据盘;journal-disk 表示日志盘,它可以是一个单独的磁盘,后者 OSD 数据盘上的一个分区,或者一个 SSD 磁盘上的分区。
(5)将 Admin key 复制到其余各个节点,然后安装 MDS 集群
ceph-deploy admin ceph1 ceph2 ceph3
ceph-deploy mds create ceph1 ceph2
完成后可以使用 “ceph mds” 命令来操作 MDS 集群,比如查看状态:
e13: 1/1/1 up {0=ceph1=up:active}, 1 up:standby
看起来 MDS 集群是个 active/standby 模式的集群。
至此,Ceph 集群部署完成,可以使用 ceph 命令查看集群状态:
在这过程中,失败和反复是难免的,在任何时候,可以使用如下的命令将已有的配置擦除然后从头安装:
ceph-deploy purge ceph{1,2,3}
ceph-deploy purgedata ceph{1,2,3}
九、Ceph RBD接口和工具
Ceph 提供一个消息层协议使得 ceph 客户端可以和 Ceph Monitor 以及 Ceph OSD Daemon 交互。librados 就是一个该协议的编码库形式的实现。所有的 Ceph clients 要么使用 librados 要么使用其封装的更高层 API 与对象存储进行交互。比如,librbd 使用 librados 提供 Ceph 客户端与 RBD 交互 API。
一个 Ceph client 通过 librados 存放或者读取数据块到 Ceph 中,需要经过以下步骤:
(1)Client 调用 librados 连接到 Ceph monitor,获取 Cluster map。
(2)当 client 要读或者写数据时,它创建一个与 pool 的 I/O Context。该 pool 关联有ruleset,它定义了数据在 Ceph 存储集群中是怎么存放的。
(3)client 通过 I/O Context 提供 object name 给 librados,它使用该 object name 和 cluster map 计算出 PG 和 OSD 来定位到数据的位置。
(4)client 直接和 OSD Deamon 交互来读或者写数据。
2.librados for phthon
Python rados 模块是 librados 的 Python 的很薄的封装,它在 github 上的源文件在 /src/pybind/rados.py, 安装到 Ubunt 后的在 /usr/lib/python2.7/dist–packages/rados.py。
(1)要使用 rados.py 模块,在你的代码中 import rados
(2)创建一个 cluster handler,你需要提供 ceph.conf 文件和 keystring
(4)获取 ceph cluster 的信息,以及操作 pool
cluster_stats = cluster.get_cluster_stats()
cluster.create_pool(‘test‘)
(5)向 ceph 集群读写数据,需要有一个 I/O Context (ioctx)
ioctx = cluster.open_ioctx(‘data’)
(6)然后就可以读写数据了
ioctx.write_full(“hw”, “Hello World!”) #向 “hw” object 写入 “Hello World!”
print ioctx.read(“hw”) #读取 ”hw“ object 的数据
ioctx.remove_object(“hw”) #删除 “hw” object
十.Ceph物理和逻辑结构
1.Ceph 内部集群
从物理上来讲,一个 Ceph 集群内部其实有几个子集群存在:
(1)MON集群:MON 集群有由少量的、数目为奇数个的 Monitor 守护进程组成,它们负责通过维护 Ceph Cluster map 的一个主拷贝来维护整 Ceph 集群的全局状态。理论上来讲,一个 MON 就可以完成这个任务,之所以需要一个多个守护进程组成的集群的原因是保证高可靠性。每个 Ceph node 上最多只能有一个 Monitor Daemon。
# ps -ef | grep ceph-mon
root 964 1 0 Sep18 ? 00:36:33 /usr/bin/ceph-mon –cluster=ceph -i ceph1 -f
实际上,除了维护 Cluster map 以外,MON 还承担一些别的任务,比如用户校验、日志等。
(2)OSD 集群:OSD 集群由一定数目的 OSD Daemon 组成,负责数据存储和复制,向 Ceph client 提供存储资源。每个 OSD 守护进程监视它自己的状态,以及别的 OSD 的状态,并且报告给 Monitor;而且,OSD 进程负责在数据盘上的文件读写操作;它还负责数据拷贝和恢复。在一个服务器上,一个数据盘有一个 OSD Daemon。
# ps -ef | grep ceph-osd
root 1204 1 0 Sep18 ? 00:24:39 /usr/bin/ceph-osd –cluster=ceph -i 3 -f
root 2254 1 0 Sep18 ? 00:20:52 /usr/bin/ceph-osd –cluster=ceph -i 6 -f
(3)若干个数据盘:一个Ceph 存储节点上可以有一个或者多个数据盘,每个数据盘上部署有特定的文件系统,比如 xfs,ext4 或者 btrfs,由一个 OSD Daemon 负责照顾其状态以及向其读写数据。
Disk /dev/vda: 21.5 GB, 21474836480 bytes/dev/vda1 1 41943039 20971519+ ee GPT
Disk /dev/vdb: 32.2 GB, 32212254720 bytes/dev/vdb1 1 62914559 31457279+ ee GPT
(4)要使用 CephFS,还需要 MDS 集群,用于保存 CephFS 的元数据
(5)要使用对象存储接口,还需要 RADOS Gateway, 它对外提供REST接口,兼容S3和Swift的API。
(1)服务器(主机)上:RAID 卡或者 HBA 卡上做缓存。
(3)客户机操作系统内:以 Windows 2012 为例,它提供 write-back 缓存机制。
(1)扩容粒度
Ceph在实践中,扩容受“容错域”制约,一次只能扩一个“容错域”。容错域就是:副本隔离级别,即同一个replica的数据,放在不同的磁盘/机器/Rack/机房。默认是机器,通常设为机架。Ceph扩容需要对PGs进行调整。正因为这个调整,导致Ceph受“容错域”制约。
Ceph是根据crushmap去放置PG的物理位置的,倘若在扩容进行了一半时,又有硬盘坏掉了,那Ceph的crushmap就会改变,Ceph又会重新进行PG的re-hash,很多PG的位置又会重新计算。如果运气比较差,很可能一台机器的扩容进度被迫进行了很久才回到稳定的状态。
这个crushmap改变导致的Ceph重平衡,不单单在扩容时,几乎在任何时候,对一个大的存储集群都有些头疼。在建立一个新集群时,硬盘都比较新,因此故障率并不高。但是在运行了2-3年的大存储集群,坏盘真的是一个稀松平常的事情,1000台规模的集群一天坏个2-3块盘很正常。crushmap经常变动,对Ceph内部不稳定,影响真的很大。随之而来,可能是整体IO的下降(磁盘IO被反复的rebalance占满),甚至是某些数据暂时不可用。
(3)OSD 增加时候的PG数量调整
假设我们现在有10台机器,每台一块硬盘一共10块盘,有1024个PG,PG都是单副本,那么每个盘会存100个PG。此时这个设置非常健康,但当我们集群扩容到1000台机器,每台硬盘就只放一个PG了,这会导致伪随机造成的不平衡现象放大。因此,admin就要面临调整PG数量,这就带来了问题。调PG,基本也就意味着整个集群会进入一种严重不正常的状态。几乎50%的对象,涉及到调整后的PG都需要重新放置物理位置,这会引起服务质量的严重下降。
(4)盘满造成的系统不可访问
在集群整体使用率不高时,都没有问题。而在使用率达到70%后,就需要管理员介入了。因为方差大的盘,很有可能会触及95%这条红线。admin开始调低容量过高磁盘的reweight,但如果在这一批磁盘被调整reweight没有结束时,又有一些磁盘被写满了,那管理员就必须被迫在Ceph没有达到稳定状态前,又一次reweight过高的磁盘。 这就导致了crushmap的再一次变更,从而导致Ceph离稳定状态越来越远。而此时扩容又不及时的话,更是雪上加霜。而且之前的crushmap的中间状态,也会导致一些PG迁移了一半,这些“不完整的”PG并不会被马上删除,这给本来就紧张的磁盘空间又加重了负担。
一块磁盘满了,Ceph为什么就不可用了。Ceph还真的就是这样设计的,因为Ceph没法保证新的对象是否落在空盘而不落在满盘,所以Ceph选择在有盘满了时,就拒绝服务。基本上大家的Ceph集群都是在达到50%使用率时,就要开始准备扩容了。
(2)指定使用那个节点作为故障隔离域
十一、Ceph的基础数据结构
1.image 之 ceph 系统所见
(1)RBD image 是简单的块设备,可以直接被 mount 到主机,成为一个 device,用户可以直接写入二进制数据。
(2)image 的数据被保存为若干在 RADOS 对象存储中的对象。
(3)image 的数据空间是 thin provision 的,意味着ceph 不预分配空间,而是等到实际写入数据时按照 object 分配空间。
(4)每个 data object 被保存为多份。
(5)pool 将 RBD 镜像的ID和name等基本信息保存在 rbd_directory 中,这样,rbd ls 命令就可以快速返回一个pool中所有的 RBD 镜像了。
(6)每个 RBD 镜像的元数据将保存在一个对象中,命名为 rbd_header.<image id>。
(7)RBD 镜像保存在多个对象中,这些对象的命名为 rbd_data.<image id>.<顺序编号序列>。
(8)RADOS 对象以 OSD 文件系统上的文件形式被保存,其文件名为 udata<image id>.<顺序编号序列>.<其它字符串>。
2.snapshot 之 Ceph 系统所见
(1)snapshot 的 data objects 是和 image 的 data objects 保存在同一个目录中。
(2)snapshot 的粒度不是整个 image,而是RADOS 中的 data object。
(3)当 snapshot 创建时,只是在 image 的元数据对象中增加少量字节的元数据;当 image 的 data objects 被修改(write)时,变修改的 objects 会被拷贝(copy)出来,作为 snapshot 的 data objects。这就是 COW 的含义。
十二、Ceph与OpenStack集成的实现
(1)获取 image 数据:根据传入的Glance image location,获取 image 的 IO Interator
def get(self, location, offset=0, chunk_size=None, context=None):
return (ImageIterator(loc.pool, loc.image, loc.snapshot, self), self.get_size(location))
1. 根据 location,定位到 rbd image
2. 调用 image.read 方法,按照 chunk size 读取 image data
(2)获取 image 的 size
def get_size(self, location, context=None):1. 找到 store location:loc = location.store_location2. 使用 loc 中指定的 pool 或者配置的默认pool3. 建立 connection 和 打开 IO Context:with rbd.Image(ioctx, loc.image, snapshot=loc.snapshot) as image4. 获取 image.stat() 并获取 “size”
(3)添加 image
def add(self, image_id, image_file, image_size, context=None):1. 将 image_id 作为 rbd image name:image_name = str(image_id)2. 创建 rbd image:librbd.create(ioctx, image_name, size, order, old_format=False, features=rbd.RBD_FEATURE_LAYERING)。如果 rbd 支持 RBD_FEATURE_LAYERING 的话,创建一个 clonable snapshot:rbd://fsid/pool/image/snapshot;否则,创建一个 rbd image:rbd://image 3. 调用 image.write 方法将 image_file 的内容按照 chunksize 依次写入 rbd image4. 如果要创建 snapshot 的话,调用 image.create_snap(loc.snapshot) 和 image.protect_snap(loc.snapshot) 创建snapshot
(4)删除 image
def delete(self, location, context=None):1. 根据 location 计算出 rbd image,snapshot 和 pool2. 如果它是一个 snapshot (location 是 rbd://fsid/pool/image/snapshot),则 unprotect_snap,再 remove_snap,然后删除 image;这时候有可能出错,比如存在基于该 image 的 volume。3. 如果它不是一个 snapshot (location 是 rbd://image),直接删除 rbd image。这操作也可能会出错。
OpenStack Cinder 组件和 Ceph RBD 集成的目的是将 Cinder 卷(volume)保存在 Ceph RBD 中。当使用 Ceph RBD 作为 Cinder 的后端存储时,你不需要单独的一个 Cinder -volume 节点。
(1)Cinder 不支持单个 volume 的条带化参数设置,而只是使用了公共配置项 rbd_store _chunk_size 来指定 order。
十三、QEMU-KVM和Ceph RBD的缓存机制总结
1.GUEST 应用读 I/O 过程
(1)GUEST OS 中的一个应用发出 read request。
(2)OS 在 guest page cache 中检查。如果有(hit),则直接将 data 从 guest page cache 拷贝到 application space。
(3)如果没有(miss),请求被转到 guest virtual disk。该 request 会被 QEMU 转化为对 host 上镜像文件的 read request。
(4)Host OS 在 HOST Page cache 中检查。如果 hit,则通过 QEMU 将 data 从 host page cache 传到 guest page cache,再拷贝到 application space。
(5)如果没有(miss),则启动 disk (或者 network)I/O 请求去从实际文件系统中读取数据,读到后再写入 host page cache,在写入 guest page cache,再到 GUEST OS application space。
从该过程可以看出:
两重 page cache 会对数据重复保存,这会带来内存浪费。
两重 page cache 也会提高 hit ratio,因为往往 guest page cache 比 host page cache 会小很多。
QEMU-KVM Linux 支持关闭和开启任一一个 Page cache,也就是说有四种组合模式,分别会带来不同的效果。在各种I/O的过程中,最好是绕过一个或者两个 Page cache。
(2)对于数据库这样的应用,使用 directsync 模式,数据直接写入物理磁盘才算成功。
(3)对于重要的数据或者小 I/O 的场景,使用 writethrough。
(4)对于一般的应用,或者大 I/O 场景,使用 none。这个可以说是大部分情况下的最优选项。
(5)对于丢失了也无所谓的数据,可以使用 writeback。
十四、Ceph的基本操作和常见故障排除方法
1.将一个 OSD 加入集群
(1)将 /dev/sdb1 分区删除
(2)清理磁盘: ceph-deploy disk zap ceph2:/dev/sdb
(3)创建 OSD:ceph-deploy osd create ceph2:sdb:/dev/sdd1
结果OSD就回来了:
# ceph-deploy osd create ceph2:sdb:/dev/sdd1c^C
# id weight type name up/down reweight-1 2 root default
-2 2 host ceph10 1 osd.0 up 12 1 osd.2 up 1
-3 0 host ceph24 0 osd.4 up 11 0 osd.1 up 1
其实将上面第四步和第五步合并在一起,就是替换一个故障磁盘的过程。
2. 在特定 OSD 上创建存储池
我们假设 osd.0 和 osd.2 的磁盘是 SSD 磁盘,osd.1 和 osd.4 的磁盘是 SATA 磁盘。我们将创建两个pool:pool-ssd 和 pool-sata,并确保 pool-ssd 中的对象都保存在 osd.0 和 osd.2 上,pool-sata 中的对象都保存在 osd.1 和 osd.4 上。
(1)修改 CRUSH map
# ceph osd getcrushmap -o crushmapdump
got crush map from osdmap epoch 124
# crushtool -d crushmapdump -o crushmapdump-decompiled
# crushtool -c crushmapdump-decompiled -o crushmapdump-compiled
# ceph osd setcrushmap -i crushmapdump-compiled
(2)创建 ssd-pool,其默认的 ruleset 为 0:
# ceph osd pool create ssd-pool 8 8
pool ‘ssd-pool’ created
pool 4 ‘ssd-pool’ replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 126 flags hashpspool stripe_width 0
(3)修改 ssd-pool 的 ruleset 为 ssd-pool 其id 为 1:
# ceph osd pool set ssd-pool crush_ruleset 1set pool 4 crush_ruleset to 1
# ceph osd dump | grep -i ssd
pool 4 ‘ssd-pool’ replicated size 2 min_size 1 crush_ruleset 1 object_hash rjenkins pg_num 8 pgp_num 8 last_change 128 flags hashpspool stripe_width 0
(4)类似地创建 sata-pool 并设置其 cursh ruleset 为 sata-pool 其id 为 2:
# ceph osd pool create sata-pool 8 8
pool ‘sata-pool’ created
# ceph osd pool set sata-pool crush_ruleset 2set pool 5 crush_ruleset to 2
# ceph osd dump | grep -i sata
pool 5 ‘sata-pool’ replicated size 2 min_size 1 crush_ruleset 2 object_hash rjenkins pg_num 8 pgp_num 8 last_change 131 flags hashpspool stripe_width 0
(5)分别放一个文件进这两个pool:
# rados -p ssd-pool put root-id_rsa root-id_rsa
# rados -p sata-pool put root-id_rsa root-id_rsa
# rados -p ssd-pool ls
root-id_rsa
# rados -p sata-pool ls
root-id_rsa
(6)查看对象所在的 OSD
# ceph osd map ssd-pool root-id_rsa
osdmap e132 pool ‘ssd-pool’ (4) object ‘root-id_rsa‘ -> pg 4.38e001ef (4.7) -> up ([2,0], p2) acting ([2,0], p2)
# ceph osd map sata-pool root-id_rsa
osdmap e132 pool ‘sata-pool’ (5) object ‘root-id_rsa‘ -> pg 5.38e001ef (5.7) -> up ([4,1], p4) acting ([4,1], p4)
可见,两个pool各自在ssd 和 sata 磁盘上。
原文地址:https://blog.csdn.net/qq_61604164/article/details/125158791
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_33950.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!