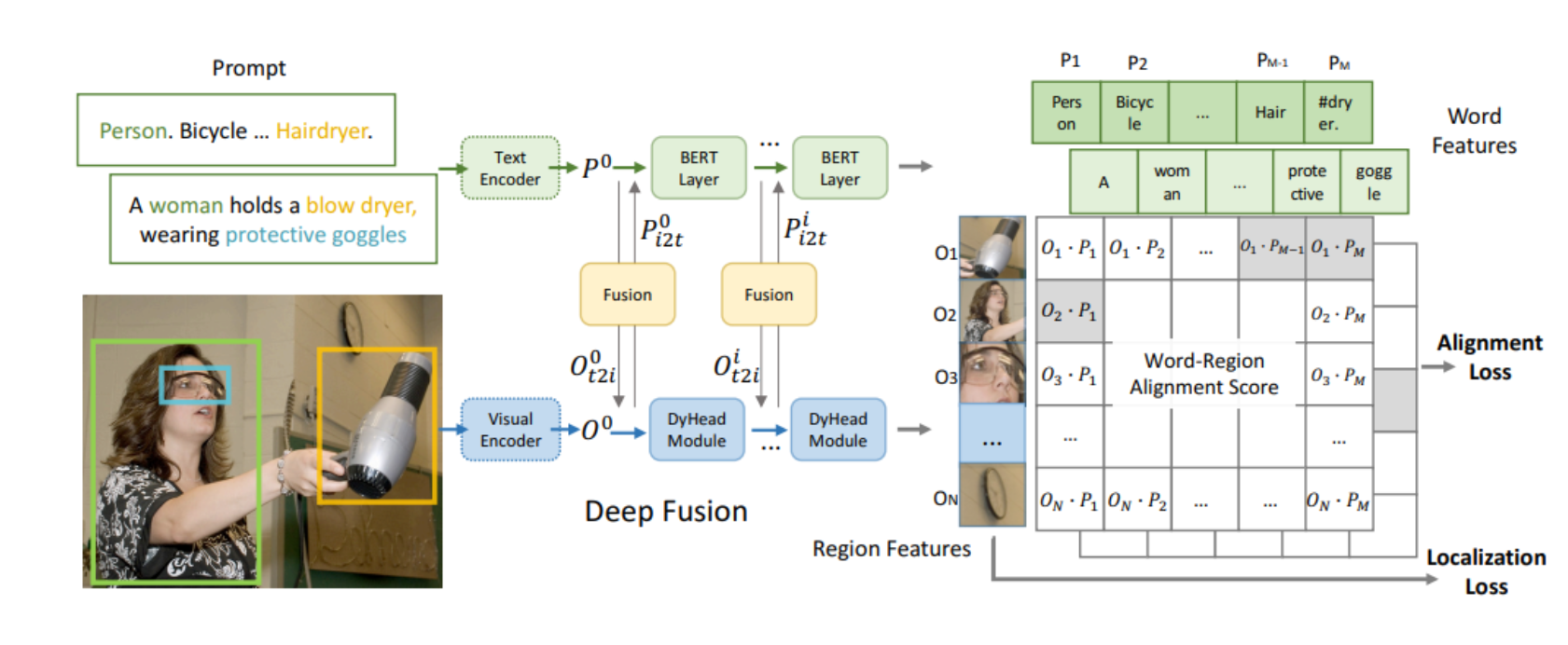
本文介绍: 许多机器学习模型包括神经网络,总是会将对抗样本错误分类,对抗样本是指对数据集中的样本施加微小的但是有目的的最坏情况下(最大化预测误差)的扰动,这样的扰动最终会导致模型以较高自信度来输出一个错误的结果。早期对于对抗样本现象的解释集中于非线性和过拟合。我们反而认为神经网络对于对抗样本脆弱性表现的主要原因在于神经网络模型的线性性质。在我们给出对抗网络在不同架构和训练集上泛化的解释时的大量结果证明了我们这个观点。而且,这个观点产生了一个简单并且快速生成对抗样本的方法。使用这个方法我们能够提供对抗样本来进行对抗训练。
(θ,x,y)=αJ(θ,x,y)+(1−α)J(θ,x+εsign(▽xJ(θ,x,y)))
本论文的实验直接令
α
=
0.5
alpha = 0.5
α=0.5,没有尝试其他值。以上的方法可以不断更新对抗样本来抵抗当前版本的模型。
对于对抗训练的看法:
不同模型的能力
为什么对抗样本具有泛化性?
η
ε
可能的假设
总结和讨论
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。