降采样提供了一种通过以降低的粒度存储时间序列数据来减少时间序列数据占用的方法。
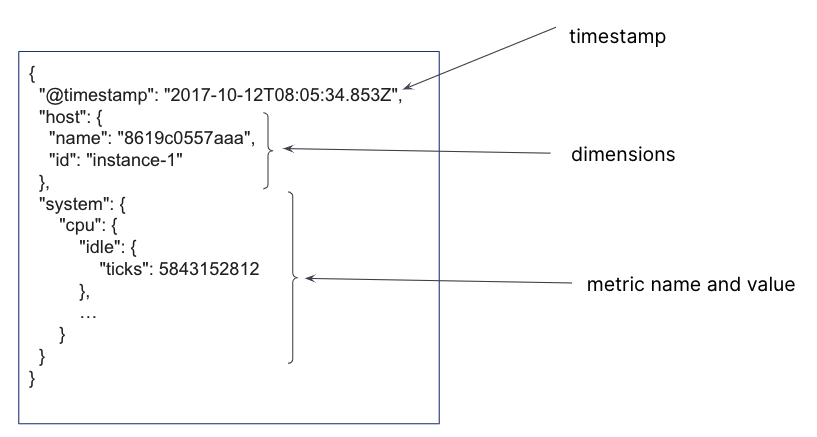
指标(metrics)解决方案收集大量随时间增长的时间序列数据。 随着数据老化,它与系统当前状态的相关性越来越小。 降采样过程将固定时间间隔内的文档汇总为单个摘要文档。 每个摘要文档都包含原始数据的统计表示:每个指标的最小值(min)、最大值 (max)、总和 (sum)、值计数 (value_count) 和平均值 (average)。 数据流时间序列维度存储不变。
实际上,降采样可以让你用数据分辨率和精度来换取存储大小。 你可以将其包含在索引生命周期管理 (ILM) 策略中,以自动管理指标数据的数量和相关成本。
它是如何工作的?
时间序列是特定实体随时间推移的一系列观察结果。 观察到的样本可以表示为连续函数,其中时间序列维度保持不变,时间序列指标随时间变化。
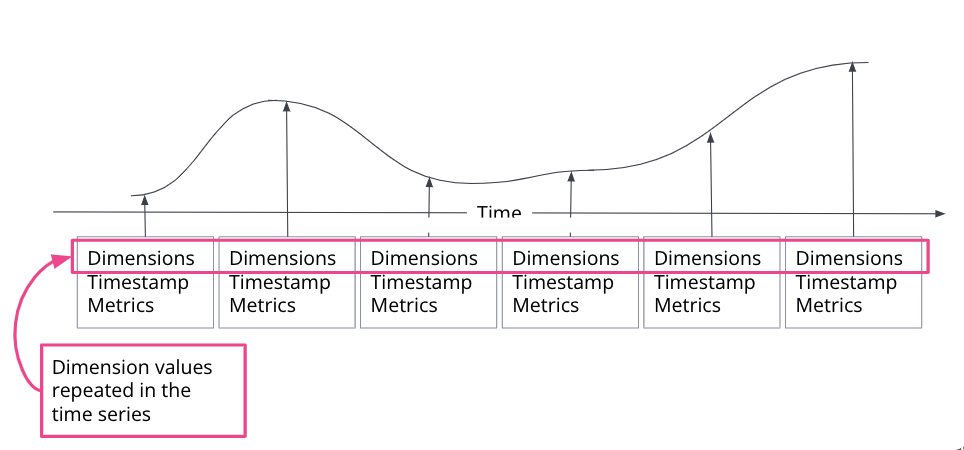
在 Elasticsearch 索引中,会为每个时间戳创建一个文档,其中包含不可变的时间序列维度以及指标名称和变化的指标值。 对于单个时间戳,可以存储多个时间序列维度和指标。
对于最新的相关数据,指标系列通常具有较低的采样时间间隔,因此它针对需要高数据分辨率的查询进行了优化。

降采样通过用更高采样间隔的数据流和该数据的统计表示替换原始时间序列来处理较旧的、访问频率较低的数据。 在原始指标样本可能已采集的情况下,例如每十秒采集一次,随着数据老化,你可以选择将样本粒度减少到每小时或每天。 你可以选择将冷归档数据的粒度减少到每月或更小。
对时间序列数据运行降采样
要对时间序列索引进行降采样,请使用 Downsample API 并将 fixed_interval 设置为你想要的粒度级别:
POST /my-time-series-index/_downsample/my-downsampled-time-series-index
{
"fixed_interval": "1d"
}要将时间序列数据降采样作为 ILM 的一部分,请在 ILM 策略中包含降采样操作,并将 fixed_interval 设置为你想要的粒度级别:
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"downsample" : {
"fixed_interval": "1h"
}
}
}
}
}
}查询降采样索引
你可以使用 _search 和 _async_search 端点来查询降采样索引。 可以在单个请求中查询多个原始数据和降采样索引,并且单个请求可以包括不同粒度(不同桶时间跨度)的降采样索引。 也就是说,你可以查询包含具有多个降采样间隔(例如15m、1h、1d)的降采样索引的数据流。
基于时间的直方图聚合的结果采用统一的桶大小,并且每个降采样索引返回忽略降采样时间间隔的数据。 例如,如果你对已按每小时分辨率 ( “fixed_interval“: “1h“) 降采样的降采样索引运行带有 “fixed_interval“: “1m” 的 date_histogram 聚合,则查询将返回一个存储桶,其中包含位于 第 0 分钟,然后是 59 个空桶,然后是下一小时内再次有数据的桶。
关于降采样查询的注意事项
- 当你在 Kibana 中并通过 Elastic 解决方案运行查询时,会返回正常响应,而不会通知某些查询索引已被降采样。
- 对于日期直方图聚合,仅支持 fixed_intervals(而不支持日历感知间隔)。
- 仅支持协调世界时 (UTC) 日期时间。
限制和局限
- 仅支持时间序列数据流中的索引。
- 仅根据时间维度对数据进行降采样。 所有其他维度都将复制到新索引而不进行任何修改。
- 在数据流内,降采样索引替换原始索引,并且原始索引被删除。 给定时间段内只能存在一个索引。
- 源索引必须处于只读模式才能成功进行降采样过程。 有关详细信息,请查看如下的手动运行降采样示例。
- 支持对同一时段的数据进行多次降采样(降采样索引的降采样)。 降采样间隔必须是降采样索引间隔的倍数。
- 降采样作为 ILM 操作提供。 请参阅降采样。
- 新的降采样索引是在原始索引的数据层上创建的,并继承其设置(例如,分片和副本的数量)。
- 支持 gauge 和 counter 指标类型。
- 降采样配置是从时间序列数据流索引映射中提取的。 唯一需要的额外设置是降采样固定间隔。
手动运行降采样
对时间序列数据流 (TSDS) 进行降采样的推荐方法是通过索引生命周期管理 (ILM)。我们将在下面进行详述。 但是,如果你不使用 ILM,则可以手动对 TSDS 进行降采样。 本指南向你展示如何使用典型的 Kubernetes 集群监控数据。
前提条件
- 请参阅 TSDS 先决条件。
- 不可能直接对数据流进行降采样,也不可能一次对多个索引进行降采样。 只能对一个时间序列索引(TSDS 后备索引)进行降采样。
- 为了对索引进行降采样,它需要是只读的。 对于 TSDS 写入索引,这意味着需要先滚动并使其变为只读。
- 降采样使用 UTC 时间戳。
- 降采样需要时间序列索引中至少存在一个指标字段。
创建时间序列数据流
首先,你将创建 TSDS。 为了简单起见,在时间序列映射中,所有 time_series_metric 参数都设置为 gauge 类型,但也可以使用其他值,例如 counter 和 histogram。 time_series_metric 值确定降采样期间使用的统计表示的类型。
索引模板包含一组静态时间序列维度:主机 (host)、命名空间 (namespace)、节点 (node) 和 Pod。 时间序列维度不会因降采样过程而改变。
PUT _index_template/my-data-stream-template
{
"index_patterns": [
"my-data-stream*"
],
"data_stream": {},
"template": {
"settings": {
"index": {
"mode": "time_series",
"routing_path": [
"kubernetes.namespace",
"kubernetes.host",
"kubernetes.node",
"kubernetes.pod"
],
"number_of_replicas": 0,
"number_of_shards": 2
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"kubernetes": {
"properties": {
"container": {
"properties": {
"cpu": {
"properties": {
"usage": {
"properties": {
"core": {
"properties": {
"ns": {
"type": "long"
}
}
},
"limit": {
"properties": {
"pct": {
"type": "float"
}
}
},
"nanocores": {
"type": "long",
"time_series_metric": "gauge"
},
"node": {
"properties": {
"pct": {
"type": "float"
}
}
}
}
}
}
},
"memory": {
"properties": {
"available": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
},
"majorpagefaults": {
"type": "long"
},
"pagefaults": {
"type": "long",
"time_series_metric": "gauge"
},
"rss": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
},
"usage": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
},
"limit": {
"properties": {
"pct": {
"type": "float"
}
}
},
"node": {
"properties": {
"pct": {
"type": "float"
}
}
}
}
},
"workingset": {
"properties": {
"bytes": {
"type": "long",
"time_series_metric": "gauge"
}
}
}
}
},
"name": {
"type": "keyword"
},
"start_time": {
"type": "date"
}
}
},
"host": {
"type": "keyword",
"time_series_dimension": true
},
"namespace": {
"type": "keyword",
"time_series_dimension": true
},
"node": {
"type": "keyword",
"time_series_dimension": true
},
"pod": {
"type": "keyword",
"time_series_dimension": true
}
}
}
}
}
}
}摄取时间序列数据
由于时间序列数据流被设计为仅接受最近的数据,因此在本例中,你将使用摄取管道在数据被索引时对数据进行时移。 因此,索引数据将具有最近 15 分钟的 @timestamp。
PUT _ingest/pipeline/my-timestamp-pipeline
{
"description": "Shifts the @timestamp to the last 15 minutes",
"processors": [
{
"set": {
"field": "ingest_time",
"value": "{{_ingest.timestamp}}"
}
},
{
"script": {
"lang": "painless",
"source": """
def delta = ChronoUnit.SECONDS.between(
ZonedDateTime.parse("2022-06-21T15:49:00Z"),
ZonedDateTime.parse(ctx["ingest_time"])
);
ctx["@timestamp"] = ZonedDateTime.parse(ctx["@timestamp"]).plus(delta,ChronoUnit.SECONDS).toString();
"""
}
}
]
}接下来,使用批量 API 请求自动创建 TSDS 并为一组 10 个文档编制索引:
PUT /my-data-stream/_bulk?refresh&pipeline=my-timestamp-pipeline
{"create": {}}
{"@timestamp":"2022-06-21T15:49:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":91153,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":463314616},"usage":{"bytes":307007078,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":585236},"rss":{"bytes":102728},"pagefaults":120901,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:45:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":124501,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":982546514},"usage":{"bytes":360035574,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1339884},"rss":{"bytes":381174},"pagefaults":178473,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:50Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":38907,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":862723768},"usage":{"bytes":379572388,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":431227},"rss":{"bytes":386580},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":86706,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":103266017,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1724908},"rss":{"bytes":105431},"pagefaults":233166,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:44:00Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":150069,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":639054643},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1786511},"rss":{"bytes":189235},"pagefaults":138172,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:40Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":82260,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":854735585},"usage":{"bytes":309798052,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":924058},"rss":{"bytes":110838},"pagefaults":259073,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:42:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":153404,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":279586406},"usage":{"bytes":214904955,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1047265},"rss":{"bytes":91914},"pagefaults":302252,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:20Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":125613,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":822782853},"usage":{"bytes":100475044,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2109932},"rss":{"bytes":278446},"pagefaults":74843,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:40:10Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":100046,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":567160996},"usage":{"bytes":362826547,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":1986724},"rss":{"bytes":402801},"pagefaults":296495,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}
{"create": {}}
{"@timestamp":"2022-06-21T15:38:30Z","kubernetes":{"host":"gke-apps-0","node":"gke-apps-0-0","pod":"gke-apps-0-0-0","container":{"cpu":{"usage":{"nanocores":40018,"core":{"ns":12828317850},"node":{"pct":2.77905e-05},"limit":{"pct":2.77905e-05}}},"memory":{"available":{"bytes":1062428344},"usage":{"bytes":265142477,"node":{"pct":0.01770037710617187},"limit":{"pct":9.923134671484496e-05}},"workingset":{"bytes":2294743},"rss":{"bytes":340623},"pagefaults":224530,"majorpagefaults":0},"start_time":"2021-03-30T07:59:06Z","name":"container-name-44"},"namespace":"namespace26"}}GET /my-data-stream/_search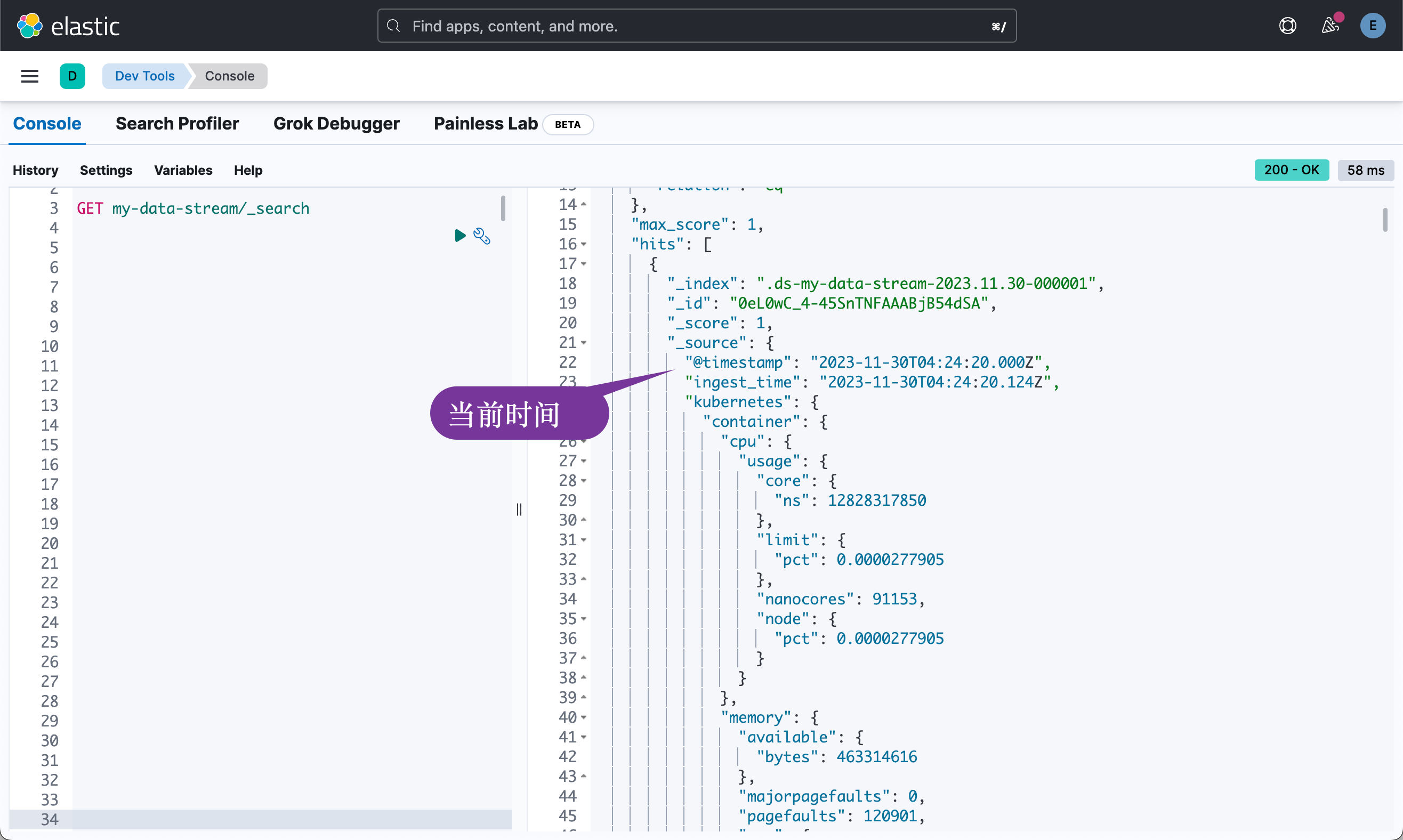
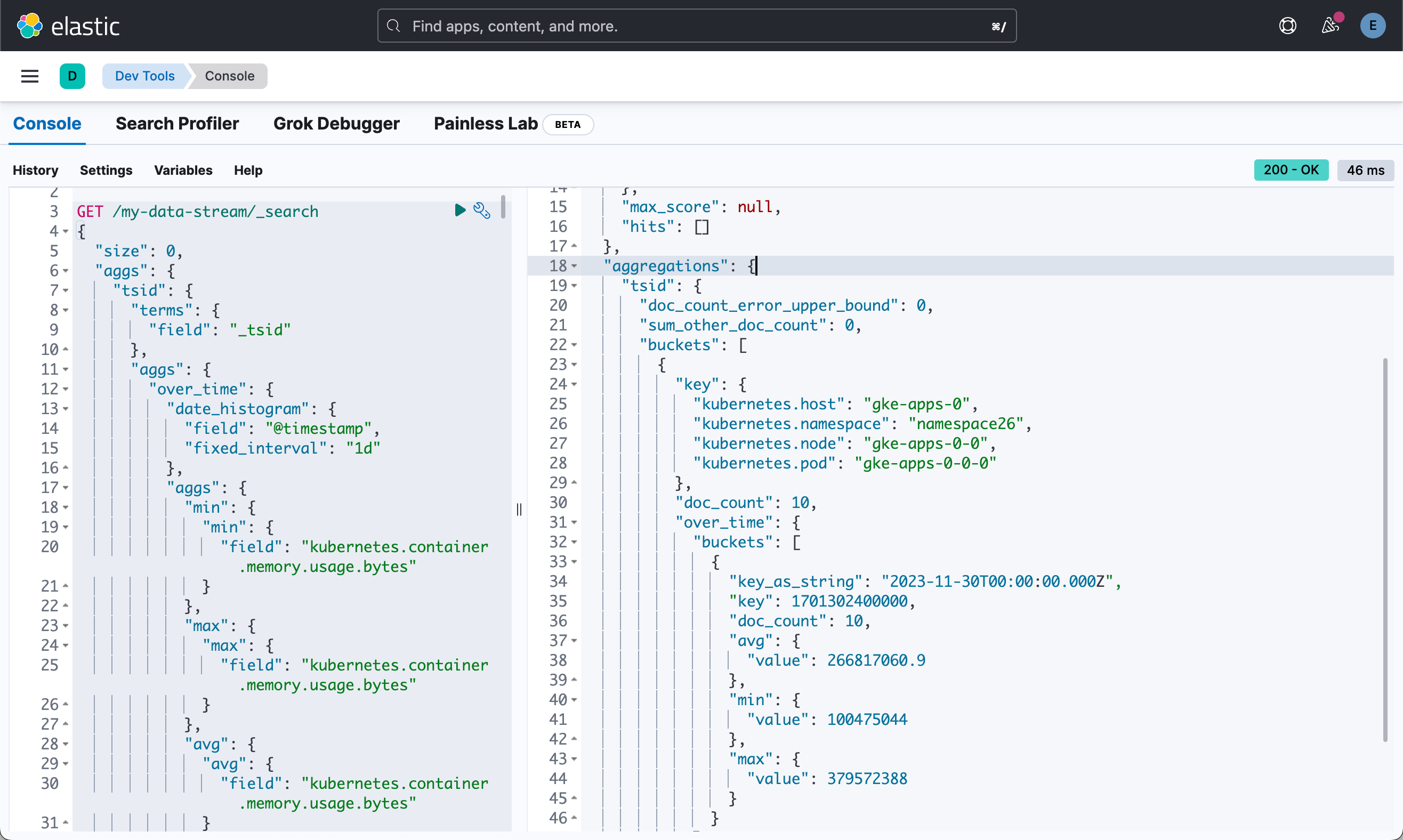
GET /my-data-stream/_search
{
"size": 0,
"aggs": {
"tsid": {
"terms": {
"field": "_tsid"
},
"aggs": {
"over_time": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1d"
},
"aggs": {
"min": {
"min": {
"field": "kubernetes.container.memory.usage.bytes"
}
},
"max": {
"max": {
"field": "kubernetes.container.memory.usage.bytes"
}
},
"avg": {
"avg": {
"field": "kubernetes.container.memory.usage.bytes"
}
}
}
}
}
}
}
}
对 TSDS 进行降采样
TSDS 无法直接降采样。 你需要对其后备索引进行降采样。 你可以通过运行以下命令查看数据流的后备索引:
GET /_data_stream/my-data-stream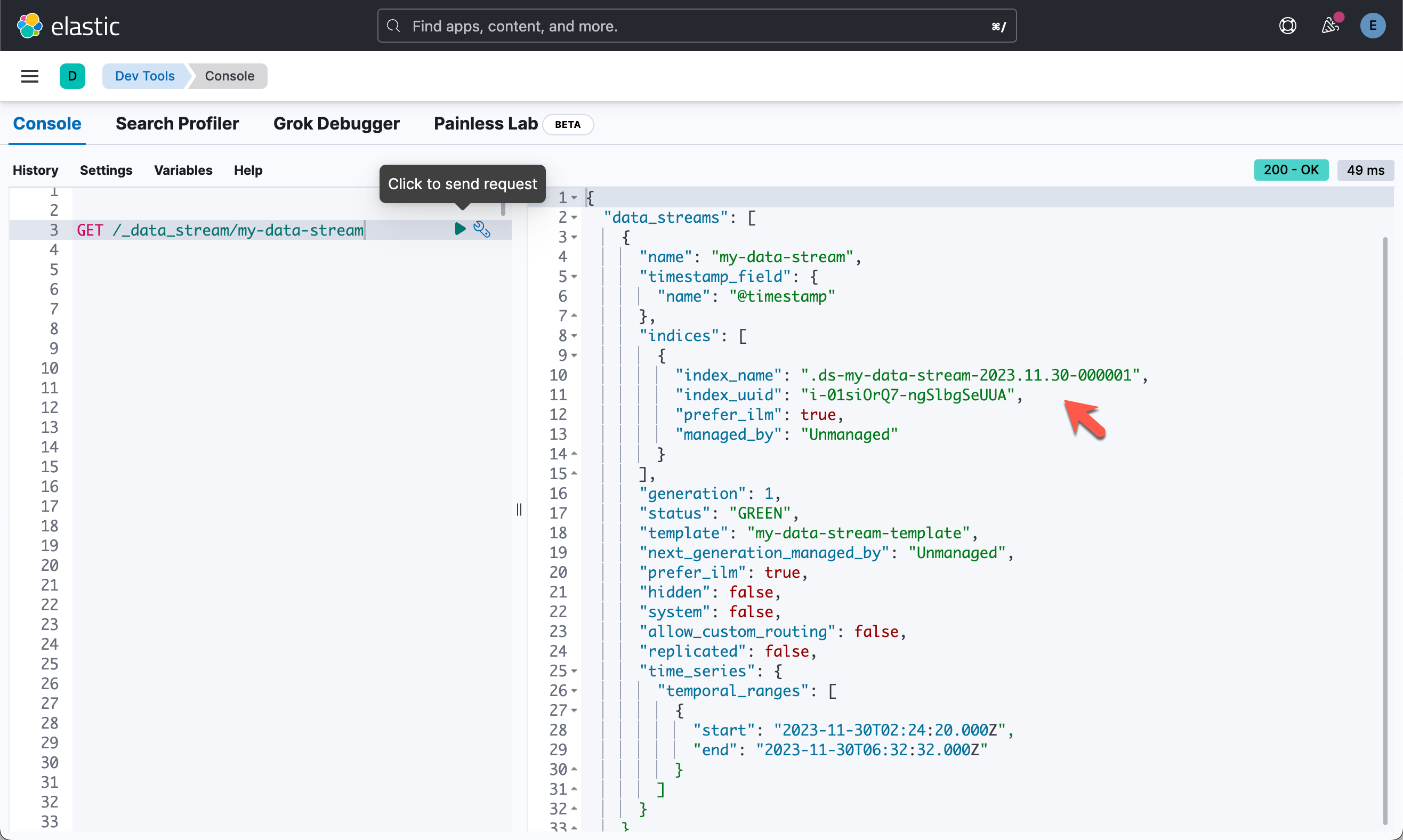
在对支持索引进行降采样之前,需要滚动 TSDS,并且需要将旧索引设为只读。
使用 rollver API 滚动 TSDS:
POST /my-data-stream/_rollover/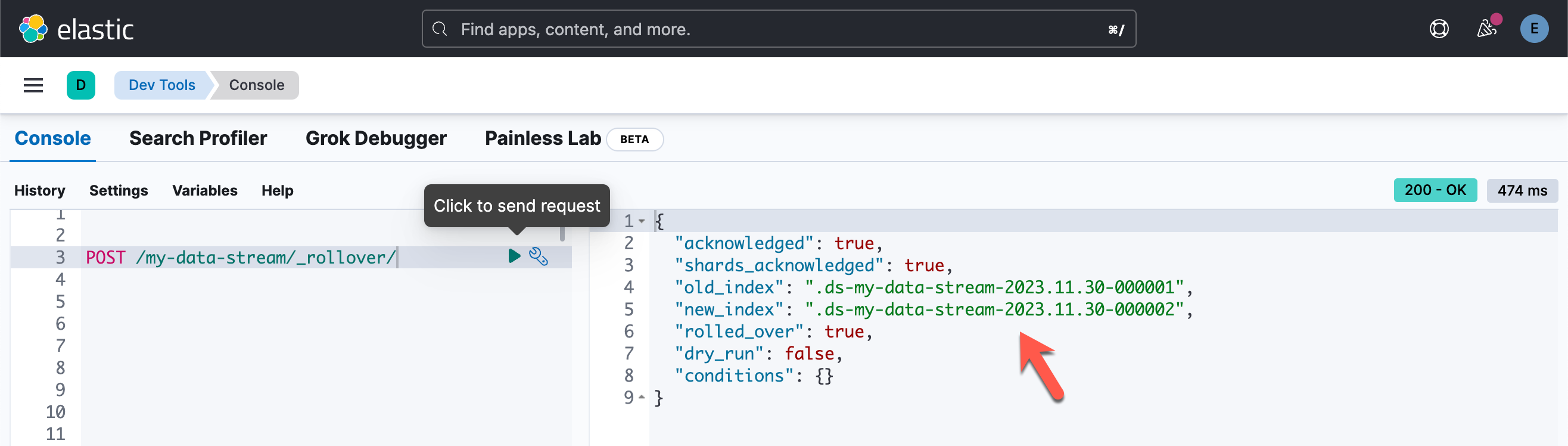
从响应中复制 old_index 的名称。 在以下步骤中,将索引名称替换为你的 old_index 的名称。
PUT /.ds-my-data-stream-2023.11.30-000001/_block/write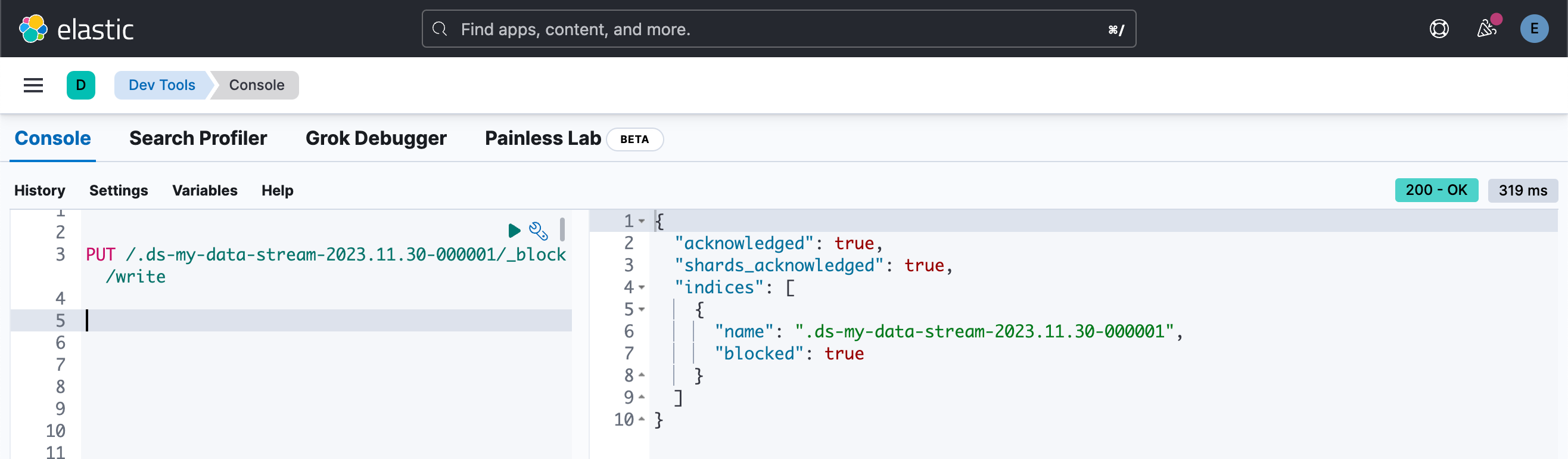
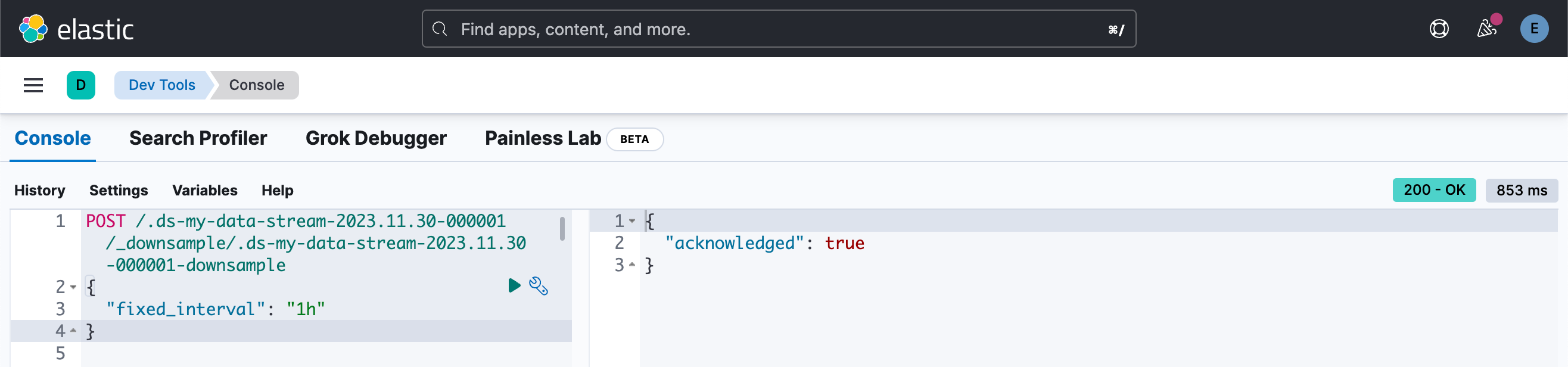
接下来,使用 downsample API 对索引进行降采样,将时间序列间隔设置为一小时:
POST /.ds-my-data-stream-2023.11.30-000001/_downsample/.ds-my-data-stream-2023.11.30-000001-downsample
{
"fixed_interval": "1h"
}
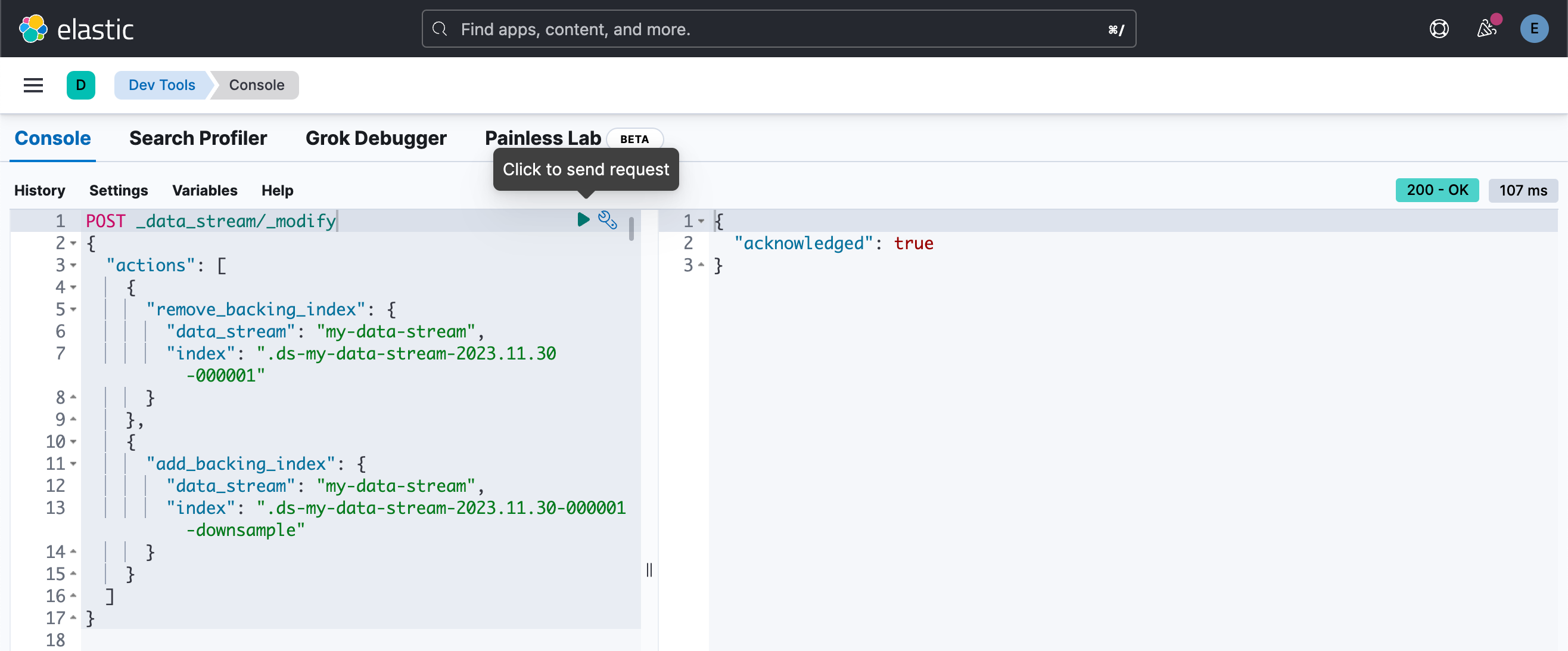
POST _data_stream/_modify
{
"actions": [
{
"remove_backing_index": {
"data_stream": "my-data-stream",
"index": ".ds-my-data-stream-2023.11.30-000001"
}
},
{
"add_backing_index": {
"data_stream": "my-data-stream",
"index": ".ds-my-data-stream-2023.11.30-000001-downsample"
}
}
]
}
你现在可以删除旧的后备索引。 但请注意,这会删除原始数据。 如果将来可能需要原始数据,请不要删除索引。
查看结果
重新运行之前的搜索查询(请注意,在查询降采样索引时,需要注意一些细微差别):
GET /my-data-stream/_search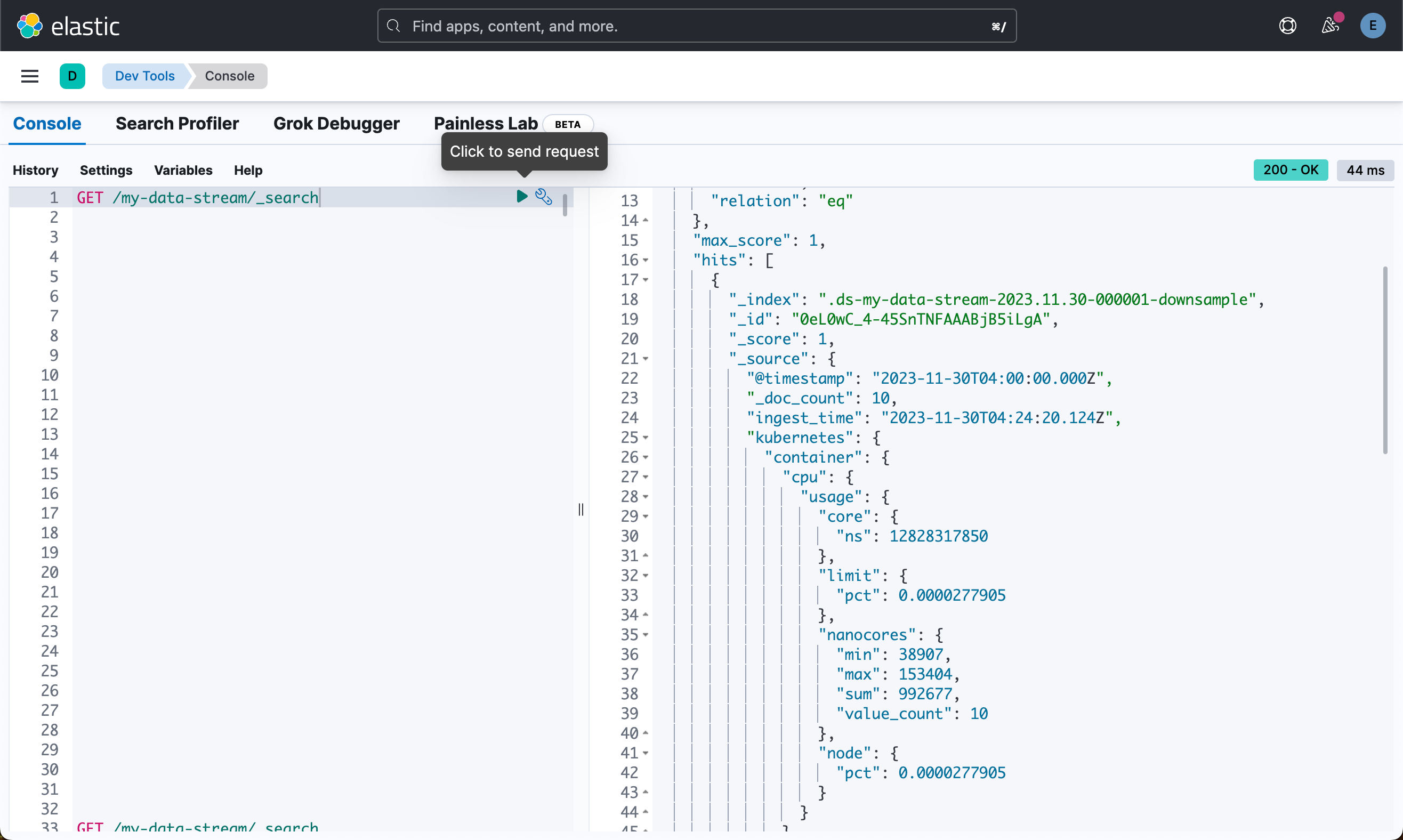
具有新的降采样后备索引的 TSDS 仅包含一份文档。 对于计数器,该文档仅具有最后的值。 对于 gauge,字段类型现在为 aggregate_metric_double。 你会看到基于原始采样指标的 min、max、sum 和 value_count 统计信息:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 4,
"successful": 4,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": ".ds-my-data-stream-2023.11.30-000001-downsample",
"_id": "0eL0wC_4-45SnTNFAAABjB5iLgA",
"_score": 1,
"_source": {
"@timestamp": "2023-11-30T04:00:00.000Z",
"_doc_count": 10,
"ingest_time": "2023-11-30T04:24:20.124Z",
"kubernetes": {
"container": {
"cpu": {
"usage": {
"core": {
"ns": 12828317850
},
"limit": {
"pct": 0.0000277905
},
"nanocores": {
"min": 38907,
"max": 153404,
"sum": 992677,
"value_count": 10
},
"node": {
"pct": 0.0000277905
}
}
},
"memory": {
"available": {
"bytes": {
"min": 279586406,
"max": 1062428344,
"sum": 7101494721,
"value_count": 10
}
},
"majorpagefaults": 0,
"pagefaults": {
"min": 74843,
"max": 302252,
"sum": 2061071,
"value_count": 10
},
"rss": {
"bytes": {
"min": 91914,
"max": 402801,
"sum": 2389770,
"value_count": 10
}
},
"usage": {
"bytes": {
"min": 100475044,
"max": 379572388,
"sum": 2668170609,
"value_count": 10
},
"limit": {
"pct": 0.00009923134
},
"node": {
"pct": 0.017700378
}
},
"workingset": {
"bytes": {
"min": 431227,
"max": 2294743,
"sum": 14230488,
"value_count": 10
}
}
},
"name": "container-name-44",
"start_time": "2021-03-30T07:59:06.000Z"
},
"host": "gke-apps-0",
"namespace": "namespace26",
"node": "gke-apps-0-0",
"pod": "gke-apps-0-0-0"
}
}
}
]
}
}重新运行之前的聚合。 即使聚合在仅包含 1 个文档的降采样 TSDS 上运行,它也会返回与原始 TSDS 上的早期聚合相同的结果。
GET /my-data-stream/_search
{
"size": 0,
"aggs": {
"tsid": {
"terms": {
"field": "_tsid"
},
"aggs": {
"over_time": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1d"
},
"aggs": {
"min": {
"min": {
"field": "kubernetes.container.memory.usage.bytes"
}
},
"max": {
"max": {
"field": "kubernetes.container.memory.usage.bytes"
}
},
"avg": {
"avg": {
"field": "kubernetes.container.memory.usage.bytes"
}
}
}
}
}
}
}
}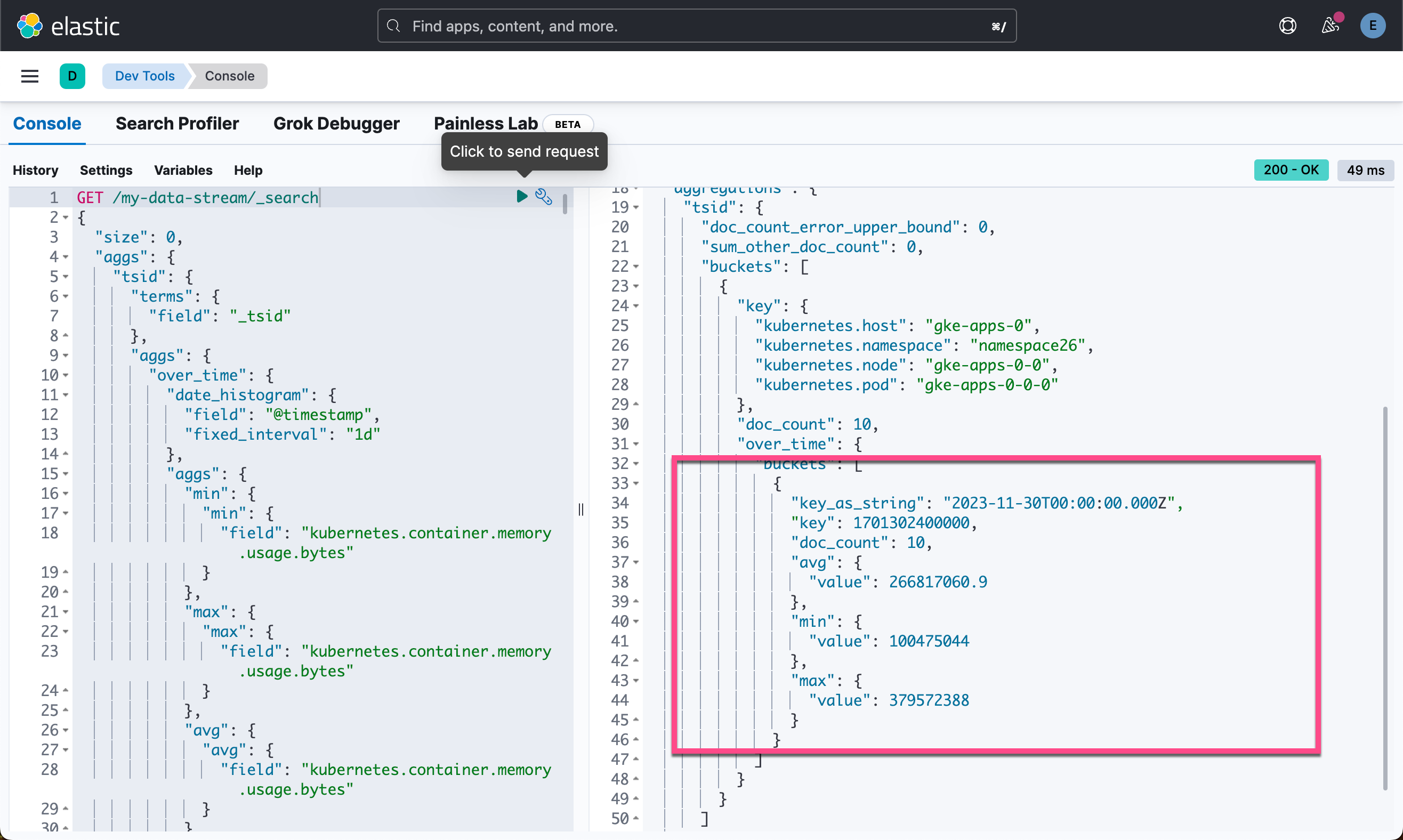
此示例演示了降采样如何在你选择的任何时间范围内显着减少为时间序列数据存储的文档数量。 随着时间序列数据的老化和数据分辨率变得不那么重要,还可以对已经降采样的数据执行降采样,以进一步减少存储和相关成本。
对 TSDS 进行降采样的推荐方法是使用 ILM。 要了解更多信息,请尝试使用 ILM 运行降采样示例。这个将在我们的下面一篇文章中进行介绍。
原文地址:https://blog.csdn.net/UbuntuTouch/article/details/134703148
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_33982.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






