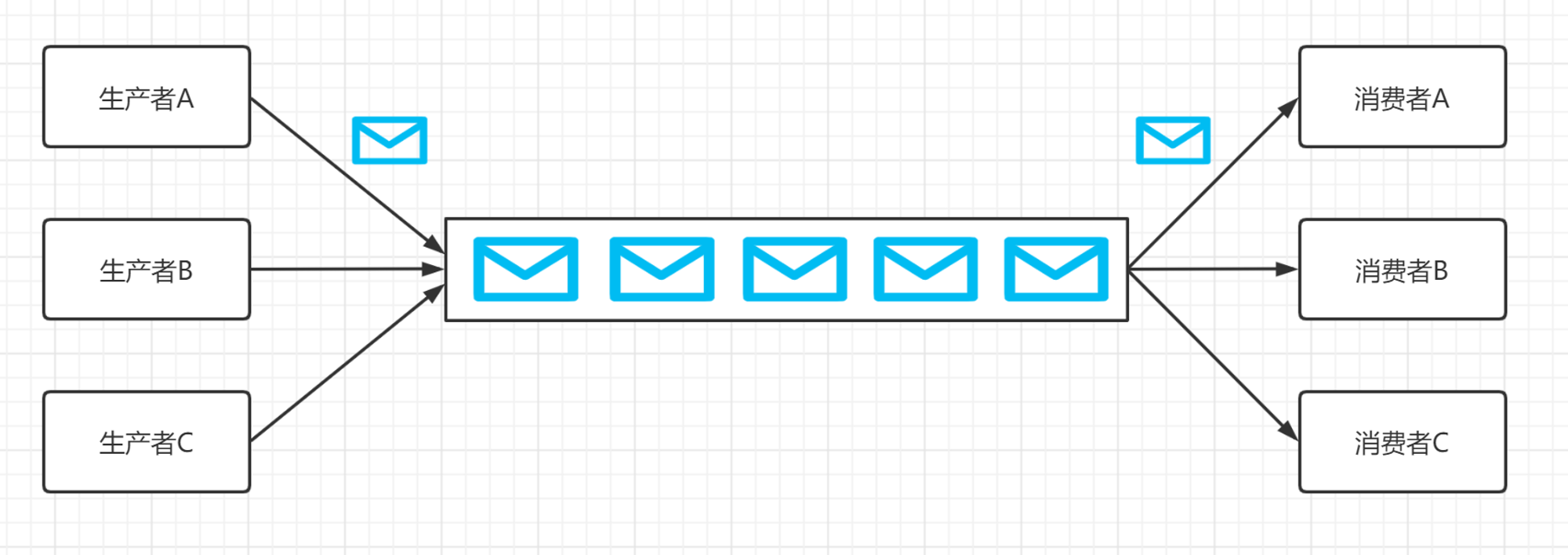
1、kafka的消费者是pull(拉)还是push(推)模式,这种模式有什么好处?
producer从broker拉取消息,consumer从broker拉取消息
优点:pull模式消费者自主决定是否批量从broker拉取数据,而push模式在无法知道消费者消费能力情况下,不易控制推送速度,太快可能造成消费者奔溃,太慢又可能造成浪费。
缺点:如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到到达。为了避免这点,Kafka 有个参数可以让 consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)。
2、kafka中ack的三种机制
request.required.acks 有三个值 0 1 -1(all),具体如下:
0:生产者不会等待 broker 的 ack,这个延迟最低但是存储的保证最弱当 server 挂掉的时候就会丢数据。
1:服务端会等待 ack 值 leader 副本确认接收到消息后发送 ack 但是如果 leader挂掉后他不确保是否复制完成新 leader 也会导致数据丢失。
-1(all):服务端会等所有的 follower 的副本受到数据后才会受到 leader 发出的ack,这样数据不会丢失。
3、kafka集群情况下怎么保证消息的顺序消费
Kafka 中发送 1 条消息的时候,可以指定(topic, partition, key) 3 个参数,partiton 和 key 是可选的。
Kafka 分布式的单位是 partition,同一个 partition 用一个 write ahead log 组织,所以可以保证FIFO 的顺序。不同 partition 之间不能保证顺序。因此你可以指定 partition,将相应的消息发往同 1个 partition,并且在消费端,Kafka 保证1 个 partition 只能被1 个 consumer 消费,就可以实现这些消息的顺序消费。
另外,你也可以指定 key(比如 order id),具有同 1 个 key 的所有消息,会发往同 1 个partition,那这样也实现了消息的顺序消息。
4、kafka如何不重复消费数据
这个问题换种问法,就是kafka如何保证消息的幂等性。对于消息队列来说,出现重复消息的概率还是挺大的,不能完全依赖消息队列,而是应该在业务层进行数据的一致性幂等校验。
比如你处理的数据要写库(mysql,redis等),你先根据主键查一下,如果这数据都有了,你就别插入了,进行一些消息登记或者update等其他操作。另外,数据库层面也可以设置唯一健,确保数据不要重复插入等 。一般这里要求生产者在发送消息的时候,携带全局的唯一id。
原文地址:https://blog.csdn.net/twjjava/article/details/134688848
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_33986.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!