本文介绍: 根据图片生成推广文案, 用的HuggingFace中的image–caption模型生成效果先安装相关的lib根据以下图片生成的文案这段代码展示了如何使用深度学习模型来生成图像的字幕,并结合LangChain智能体框架进行自动化处理.():实现代码。
根据图片生成推广文案, 用的HuggingFace中的image–caption模型
- LangChain 实现给动物取名字,
- LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字
- LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
- LangChain 4用向量数据库Faiss存储,读取YouTube的视频文本搜索Indexes for information retrieve
- LangChain 5易速鲜花内部问答系统
生成效果
pip install --upgrade langchain
pip install transformers
pip install pillow
pip install torch torchvision torchaudio
根据以下图片生成的文案

这段代码展示了如何使用深度学习模型来生成图像的字幕,并结合LangChain智能体框架进行自动化处理.(代码为黄佳老师的课程Demo,如需要知道代码细节请读原文):
import os # 导入os库,用于操作系统级别的接口,比如环境变量
import requests # 导入requests库,用于执行HTTP请求
from PIL import Image # 导入PIL库的Image模块,用于图像处理
from transformers import BlipProcessor, BlipForConditionalGeneration # 导入transformers库中的Blip模块,用于图像字幕生成
from langchain.tools import BaseTool # 导入langchain的BaseTool类,用于创建新的工具
from langchain import OpenAI # 导入langchain中的OpenAI模块,用于与OpenAI API交互
from langchain.agents import initialize_agent, AgentType # 导入langchain的agent初始化和类型定义
from dotenv import load_dotenv # 导入dotenv库,用于加载环境变量
load_dotenv() # 加载.env文件中的环境变量
# 初始化图像字幕生成模型
hf_model = "Salesforce/blip-image-captioning-large" # 指定使用HuggingFace中的模型
processor = BlipProcessor.from_pretrained(hf_model) # 初始化处理器,用于图像的预处理
model = BlipForConditionalGeneration.from_pretrained(hf_model) # 初始化模型,用于生成字幕
# 定义图像字幕生成工具类
class ImageCapTool(BaseTool):
name = "Image captioner"
description = "为图片创作说明文案."
def _run(self, url: str):
# 下载图像并将其转换为PIL对象
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
inputs = processor(image, return_tensors="pt") # 对图像进行预处理
out = model.generate(**inputs, max_new_tokens=20) # 使用模型生成字幕
caption = processor.decode(out[0], skip_special_tokens=True) # 解码字幕
return caption
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async") # 异步函数未实现
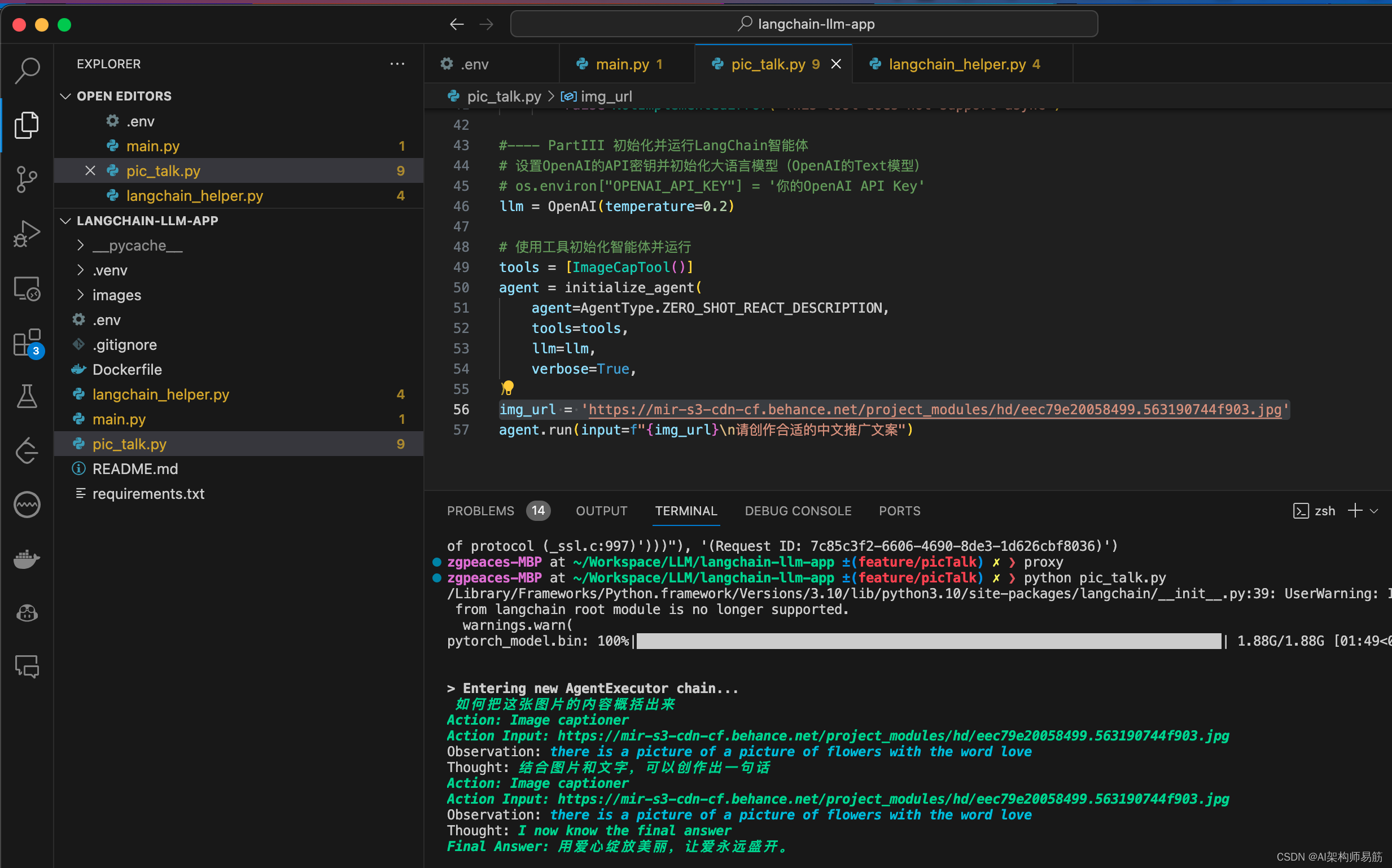
# 初始化并运行LangChain智能体
llm = OpenAI(temperature=0.2) # 使用OpenAI模型
tools = [ImageCapTool()] # 创建工具实例
agent = initialize_agent(
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=tools,
llm=llm,
verbose=True,
)
img_url = 'https://mir-s3-cdn-cf.behance.net/project_modules/hd/eec79e20058499.563190744f903.jpg' # 定义图像URL
agent.run(input=f"{img_url}n请创作合适的中文推广文案") # 使用智能体处理图像并生成字幕

代码
参考
- https://github.com/huangjia2019/langchain/blob/main/00_%E5%BC%80%E7%AF%87%E8%AF%8D_%E5%A5%87%E7%82%B9%E6%97%B6%E5%88%BB/02_%E7%9C%8B%E5%9B%BE%E8%AF%B4%E8%AF%9D.py
原文地址:https://blog.csdn.net/zgpeace/article/details/134544306
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_3402.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






