本文介绍: Kafka 是一个开源的分布式事件流平台(Event Streaming Plantform),主要用于大数据实时领域。本质上是一个分布式的基于发布/订阅模式的消息队列(Message Queue)。
kafka概述
定义
Kafka 是一个开源的分布式事件流平台(Event Streaming Plantform),主要用于大数据实时领域。本质上是一个分布式的基于发布/订阅模式的消息队列(Message Queue)。
消息队列
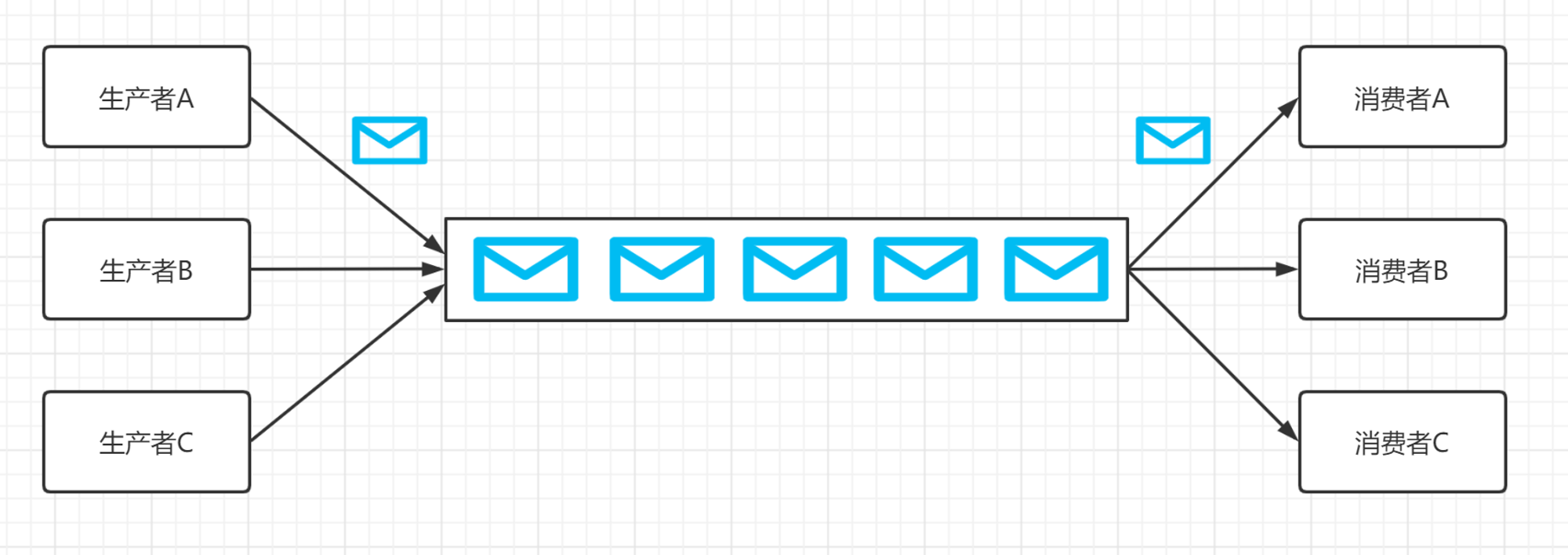
在大数据场景中主要采用Kafka 作为消息队列。传统消息队列主要应用场景包括:缓存/削峰、解耦和异步通信。
消息队列的模式包含了 2 种,点对点订阅模式和发布/订阅模式。
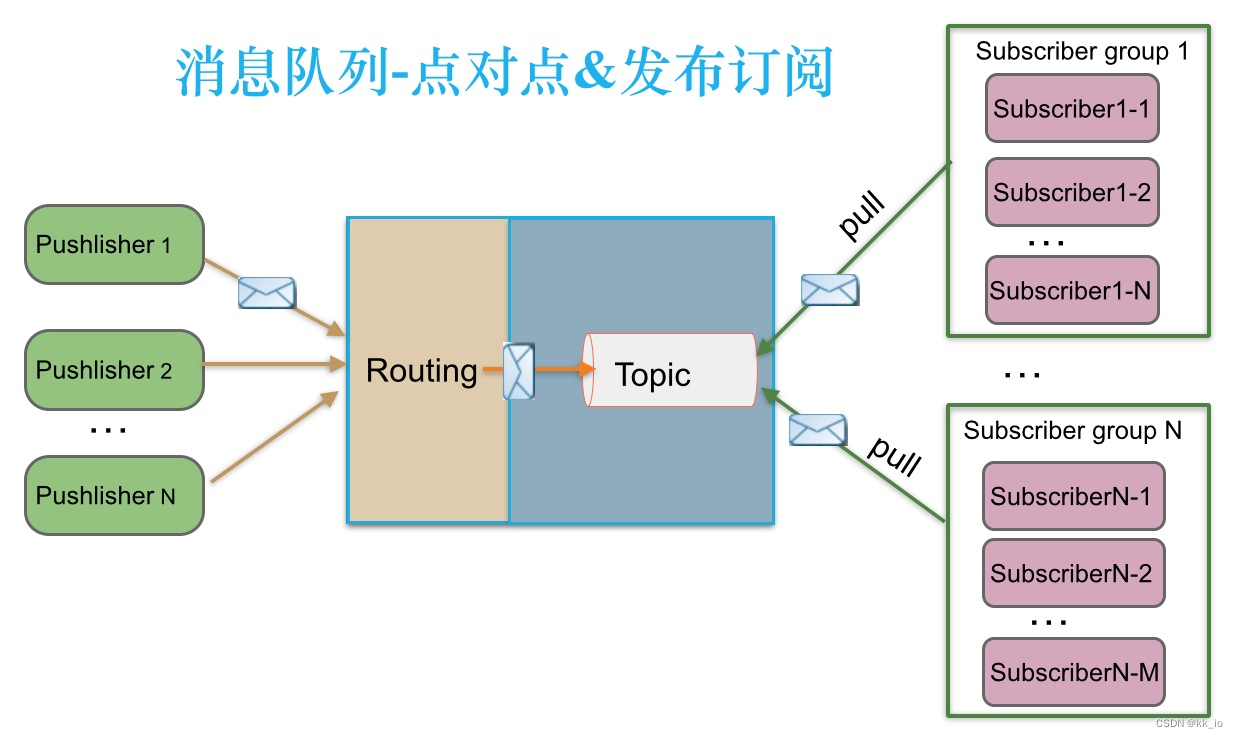
Kafka采用了发布/订阅模式,这种模式有以下特点:
Kafka 基础架构
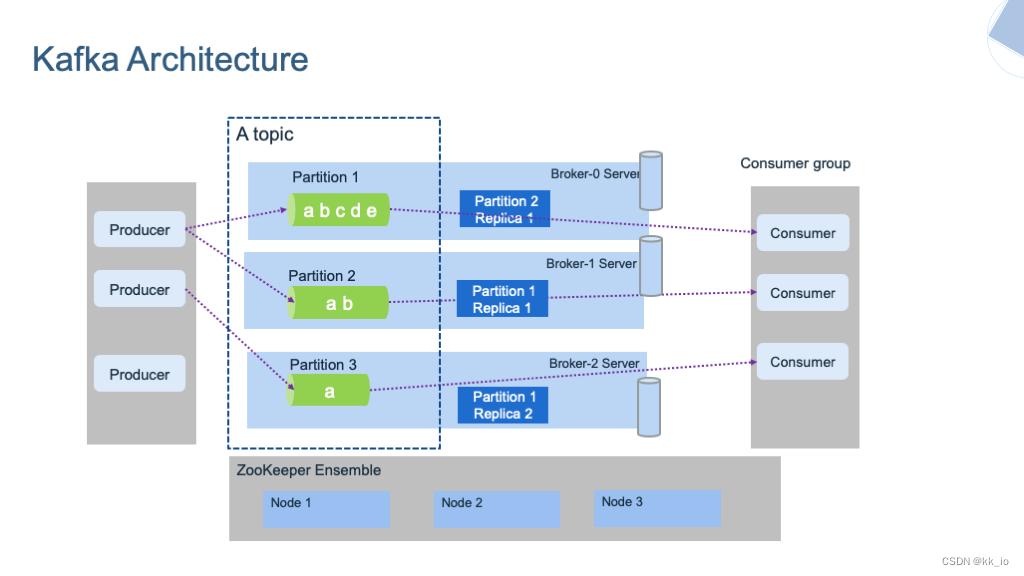
为了方便扩展,提高吞吐量,一个 topic可以分为多个 partition。为了配合分区设计,提出了消费者组的概念,组内每个消费者并行消费。为提高可用性,每个 partition 增加若干可配置副本。在 2.8 之下的版本,将数据 leader提交给 Zookeeper 保管,2.8 版本之后,可以不配置 zookeeper。
Kafka 快速安装
规划
集群部署
kafka命令行操作
说明:
3.消费者命令行
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。