案例背景
本次案例来自2021年matchcop大数据竞赛A题数据集。要预测二手车的价格。训练集3万条数据,测试集5千条。官方给了二手车的很多特征,有的是已知的,有的是匿名的。要求就是做模型去预测测试集的二手车的价格。价格是一个连续变量,所以这是一个回归问题。(需要数据集可以留言)
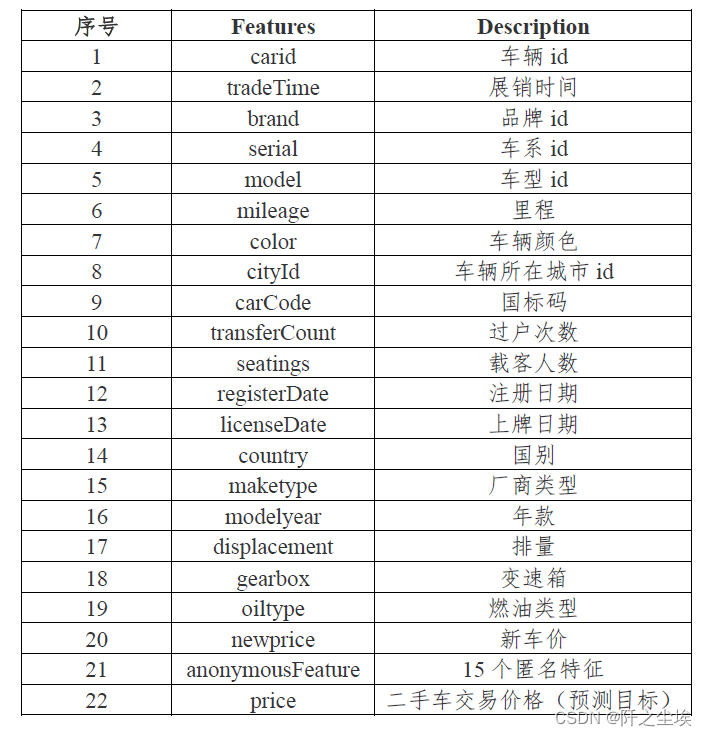
数据集:
说实话有点复杂,给的是txt文件,而且各种花样缺失数据…..要是新手估计读取数据这一步就直接劝退了。下面我们从读取数据开始,一点点完成这个案例。
读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号由于txt文件里面没有列名称,所以读取数据的时候要给个名称,名称按顺序用列表装好,用pandas读取的时候传入header。
columns=['carid', 'tradeTime', 'brand', 'serial', 'model', 'mileage', 'color','cityid', 'carCode', 'transferCount','seatings',
'registerDate', 'licenseDate', 'country', 'maketype', 'modelyear', 'displacement','gearbox','oiltype', 'newprice',
'AF1', 'AF2', 'AF3', 'AF4', 'AF5','AF6', 'AF7', 'AF8', 'AF9', 'AF10', 'AF11','AF12', 'AF13', 'AF14','AF15', 'price']
data=pd.read_csv('附件1:估价训练数据.txt',sep='t',header=None,names=columns)
data2=pd.read_csv('附件2:估价验证数据.txt',sep='t',header=None,names=columns[:-1])
data.head()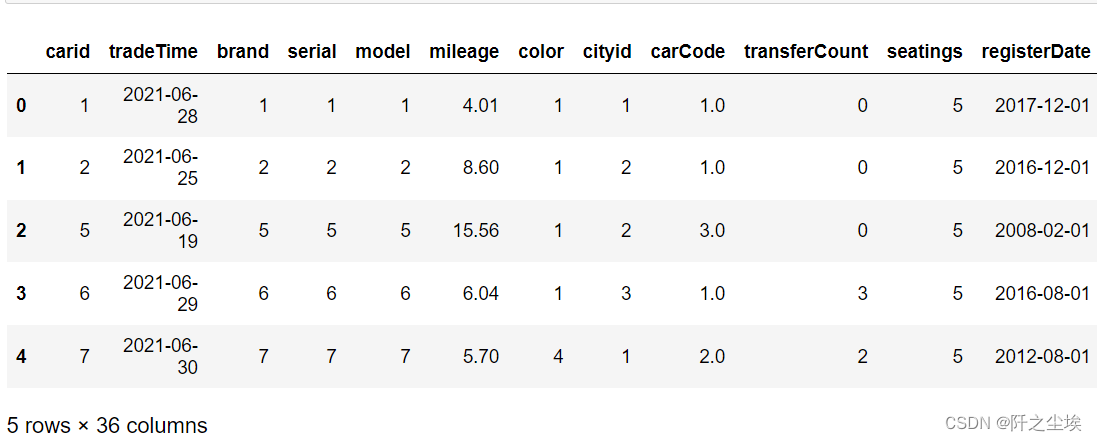
data.infer_objects()
data2.infer_objects()
data.info() ,data2.info()#查看数据基础信息
可以看到每个数据的类型,还有非空的个数。测试集也是一样,只是少了一列数据‘price’,这是响应变量,是我们要预测的,测试集当然没有。
数据清洗
首先要看数据的缺失量
#观察缺失值
import missingno as msno
msno.matrix(data)
这个图黑色的位置表示有数据,白色的表示缺失值。可以看到AF15,AF7,AF4等缺失值都较多,测试集也差不多
msno.matrix(data2) 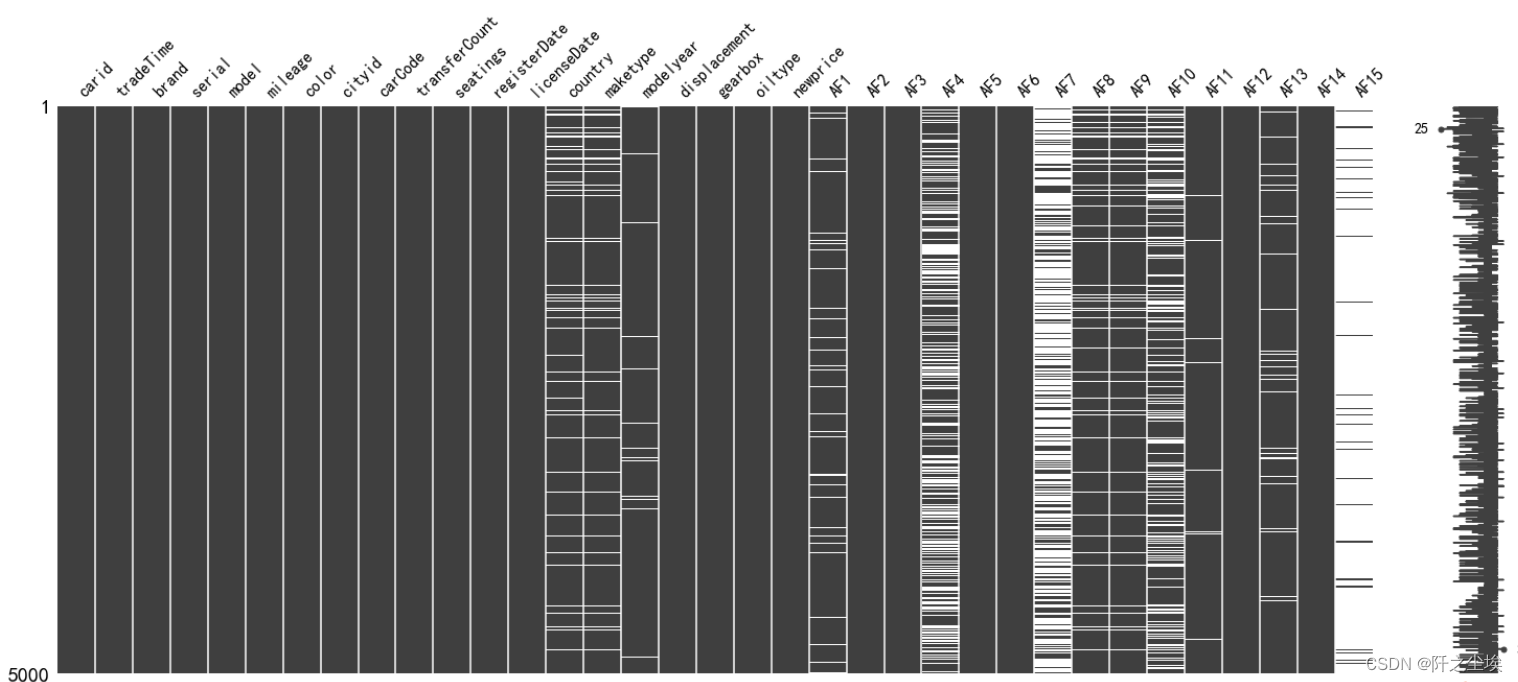
首先要处理第一列,ID列,这一列是每个车都有的独一无二的的标号,对预测没什么帮助。训练集就直接删了,测试集的id号要留一下,因为后面预测的时候要把ID号和你预测的车的价格要对应起来,才能提交。
#删除id序号
data.drop('carid',axis=1,inplace=True)
ID=data2['carid']#若是有一行全为空值就删除
data.dropna(how='all',inplace=True)
data2.dropna(how='all',inplace=True)再对列进列进行处理。如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用
#取值唯一的变量删除
for col in data.columns:
if len(data[col].value_counts())==1:
print(col)
data.drop(col,axis=1,inplace=True)缺失量达到一定程度就给他删了,缺失太多不如不要这个特征。我这里的比例是15%
#缺失到一定比例就删除
miss_ratio=0.15
for col in data.columns:
if data[col].isnull().sum()>data.shape[0]*miss_ratio:
print(col)
data.drop(col,axis=1,inplace=True)
可以看到上面这四个特征的缺失比例都高于15%,所以都删掉了。
然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。
首先查看数值型数据
#查看数值型数据,
pd.set_option('display.max_columns', 30)
data.select_dtypes(exclude=['object']).head()
可以看到虽然都是数值型,但是有的是分类数据,有的还是是年份、日期,,所以看情况需要处理一下。
我这里就年份型数据modelyear留着了,然后删除AF13,它是个日期,也不知道含义,没啥用
#删除不要数值变量,不知道含义
data.drop('AF13',axis=1,inplace=True)做机器学习当然需要特征越分散越好,因为这样就可以在X上更加有区分度,从而更好的分类。所以那些数据分布很集中的变量可以扔掉。我们用异众比例来衡量数据的分散程度,也可以用方差,但是由于数据的口径大小不一致,方差不好对比我这里就没有用。
#计算异众比例
variation_ratio_s=0.1
for col in data.select_dtypes(exclude=['object']).columns:
df_count=data[col].value_counts()
kind=df_count.index[0]
variation_ratio=1-(df_count.iloc[0]/len(data[col]))
if variation_ratio<variation_ratio_s:
print(f'{col} 最多的取值为{kind},异众比例为{round(variation_ratio,4)},太小了,没区分度删掉')
data.drop(col,axis=1,inplace=True)
又删了3个特征。
#查看非数值型数据
data.select_dtypes(exclude=['int64','float64']).head()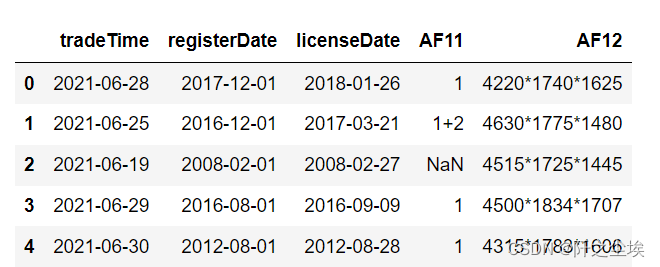
本次只有5个特征是非数值型数据,可以看到前三列是时间,AF11猜测是销售方式,AF12猜测是什么编号之类的。
和数值型数据一样,不要的就扔掉,需要的等下特征工程去处理。#有用的等下构建特征去做特征,该独热独热,没用的才删除。
这里删掉AF12,因为也不知道是啥,还有licenseDate,上牌时间没啥用。剩下两个时间可以算车子的年龄,等下特征工程有用,所以留着。AF11可以独热变为新特征,也留着。
#删除不要的字符变量
data.drop(['licenseDate','AF12'],axis=1,inplace=True)#总结一下现在的变量,并给测试集也筛一下
columns=data.columns
print(columns)
data2=data2[columns[:-1]] #y值不要填充缺失值
#均值填充,中位数填充,众数填充
#前填充,后填充
data.fillna(data.median(),inplace=True) #mode,mean
data.fillna(method='ffill',inplace=True) #pad,bfill/backfill
data2.fillna(data2.median(),inplace=True)
data2.fillna(method='ffill',inplace=True)特征工程
#首先对训练集取出y
y=data['price']
data.drop(['price'],axis=1,inplace=True) #对前面的说要处理的变量单独处理,
#时间类型变量的处理,得出二手车年龄,天数
#对前面的要处理的变量单独处理,
#时间类型变量的处理,得出二手车年龄,天数
data['age']=(pd.to_datetime(data['tradeTime'])-pd.to_datetime(data['registerDate'])).map(lambda x:x.days)
#测试集也一样变化
data2['age']=(pd.to_datetime(data2['tradeTime'])-pd.to_datetime(data2['registerDate'])).map(lambda x:x.days)构建了新特征后,原来的特征不要的就删除
#然后删除原来的不需要的特征变量
data.drop(['tradeTime','registerDate'],axis=1,inplace=True)
data2.drop(['tradeTime','registerDate'],axis=1,inplace=True)#剩下的变量独热处理
data=pd.get_dummies(data)
data2=pd.get_dummies(data2)其实也可以映射,用map把分类的文本转化为数值(这里没运行,只是说明有这种做法)
#可以映射
# d1={'male':0,'female':1}
# data['Sex']=data['Sex'].map(d1)
# data2['Sex']=data2['Sex'].map(d1)
#还可以因子化
#codes,uniques=pd.factorize(data['Sex'])有时候训练集和测试集的特征变量独热出来数量可能不一样,要处理一下。
#独热多出来的特征处理
for col in data.columns:
if col not in data2.columns:
data2[col]=0print(data.shape,data2.shape,y.shape) 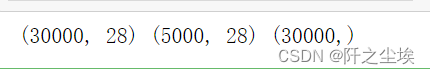
特征个数都是28,一样。
#查看处理完的数据信息
data.info(),data2.info()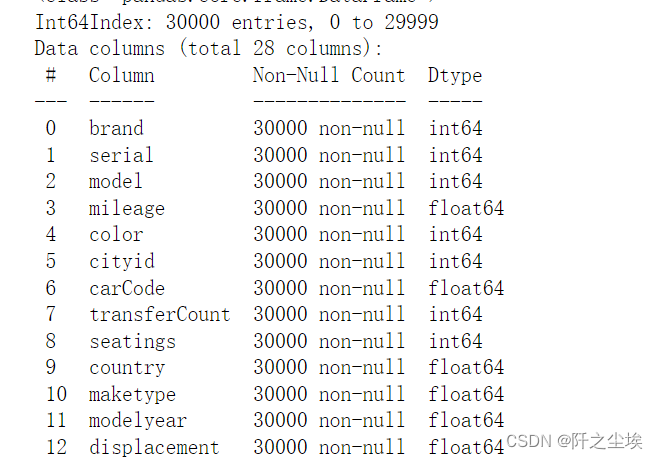
数据画图探索
训练集的箱线图
#查看特征变量的箱线图分布
columns = data.columns.tolist() # 列表头
dis_cols = 7 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
plt.subplot(dis_rows,dis_cols,i+1)
sns.boxplot(data=data[columns[i]], orient="v",width=0.5)
plt.xlabel(columns[i],fontsize = 20)
plt.tight_layout()
#plt.savefig('特征变量箱线图',formate='png',dpi=500)
plt.show()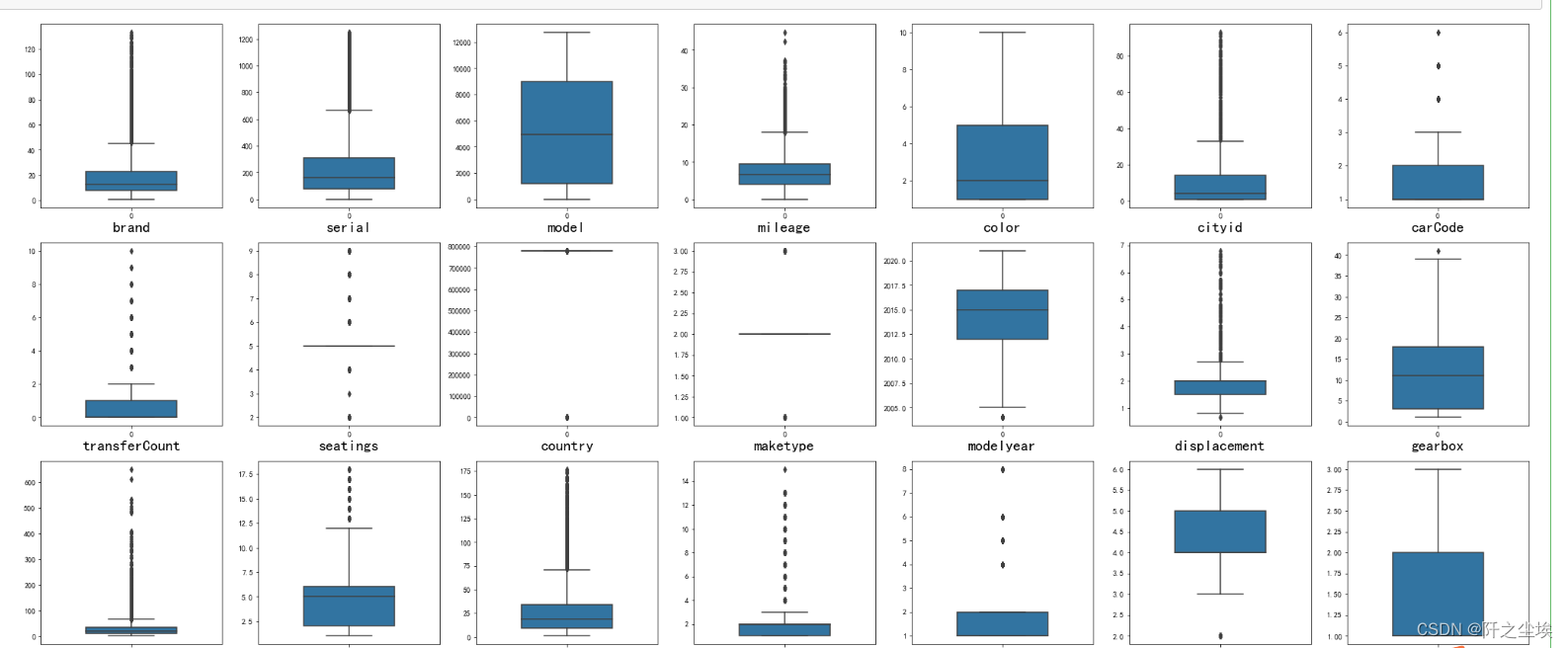
#画密度图,训练集和测试集对比
dis_cols = 5 #一行几个
dis_rows = len(columns)
plt.figure(figsize=(4 * dis_cols, 4 * dis_rows))
for i in range(len(columns)):
ax = plt.subplot(dis_rows, dis_cols, i+1)
ax = sns.kdeplot(data[columns[i]], color="Red" ,shade=True)
ax = sns.kdeplot(data2[columns[i]], color="Blue",warn_singular=False,shade=True)
ax.set_xlabel(columns[i],fontsize = 20)
ax.set_ylabel("Frequency",fontsize = 18)
ax = ax.legend(["train", "test"])
plt.tight_layout()
#plt.savefig('训练测试特征变量核密度图',formate='png',dpi=500)
plt.show()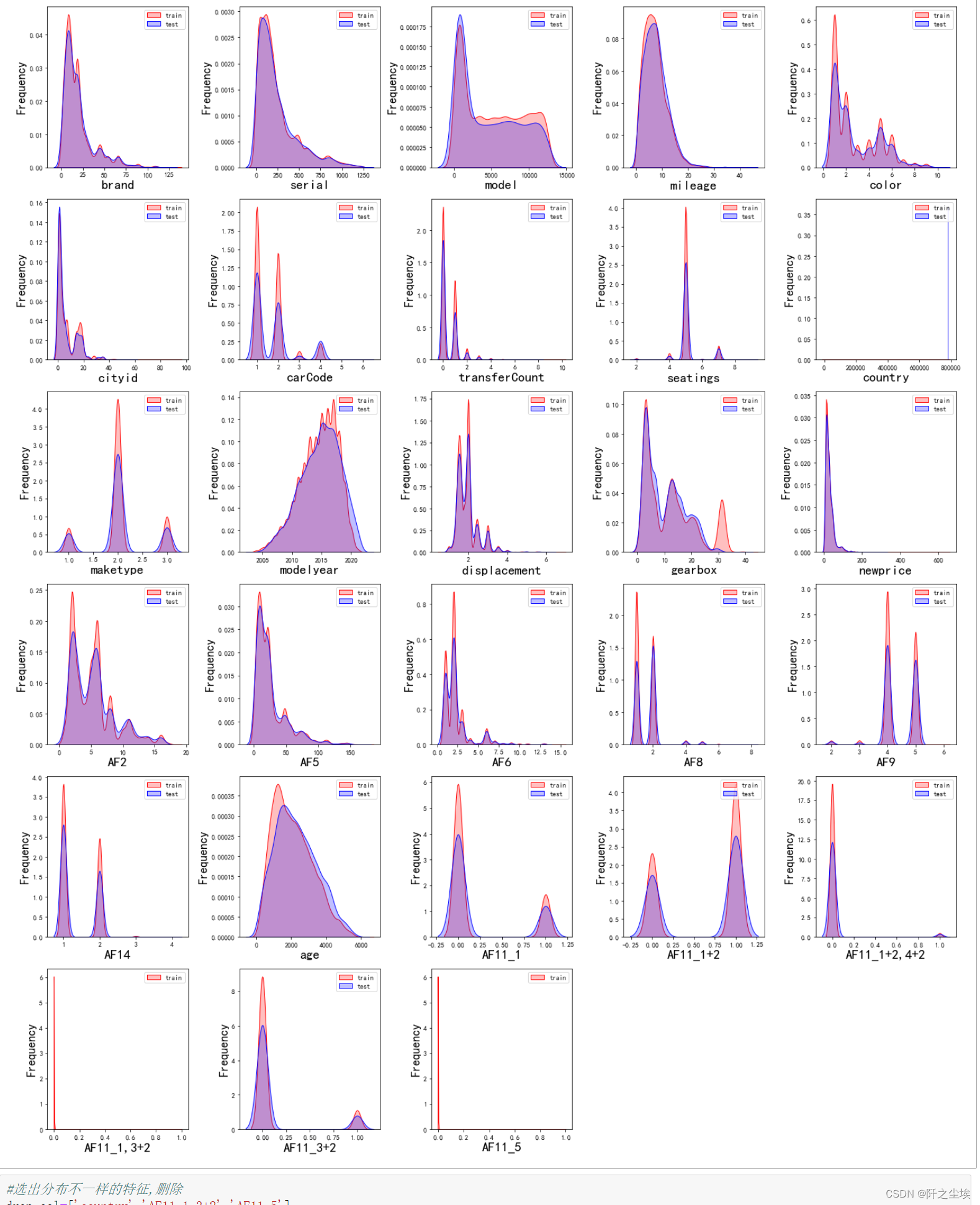
如果训练集和测试集的X数据分布是不一致的,差太远的话会影响模型的泛化能力,使用这样的变量要删除,这里’country‘,’AF11_1,3+2’,’AF11_5’可以从图中看出分布不一致。要删除
#选出分布不一样的特征,删除
drop_col=['country','AF11_1,3+2','AF11_5']
data.drop(drop_col,axis=1,inplace=True)
data2.drop(drop_col,axis=1,inplace=True)# 查看y的分布
#回归问题
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()

可以看到有很严重的异常值,要筛掉
异常值处理
y异常值处理
我们将y大于200的样本都筛掉
#处理y的异常值
y=y[y <= 200]
plt.figure(figsize=(6,2),dpi=128)
plt.subplot(1,3,1)
y.plot.box(title='响应变量箱线图')
plt.subplot(1,3,2)
y.plot.hist(title='响应变量直方图')
plt.subplot(1,3,3)
y.plot.kde(title='响应变量核密度图')
#sns.kdeplot(y, color='Red', shade=True)
#plt.savefig('响应变量.png')
plt.tight_layout()
plt.show()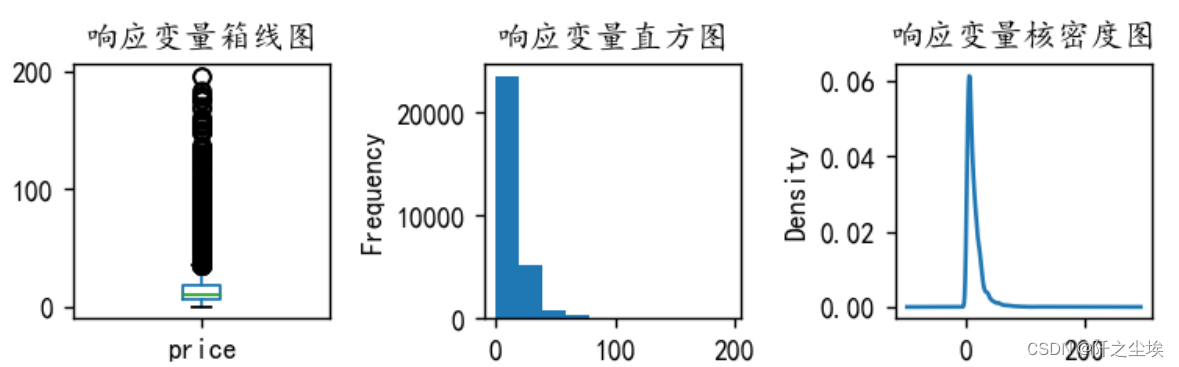
可以看到极端值情况好了一些
#筛选给x
data=data.iloc[y.index,:]
data.shape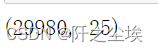
3万条数据变成了29980条
X异常值处理
#X异常值处理,先标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_s = scaler.fit_transform(data)
X2_s = scaler.fit_transform(data2)然后画图查看
plt.figure(figsize=(20,8))
plt.boxplot(x=X_s,labels=data.columns)
#plt.hlines([-10,10],0,len(columns))
plt.show()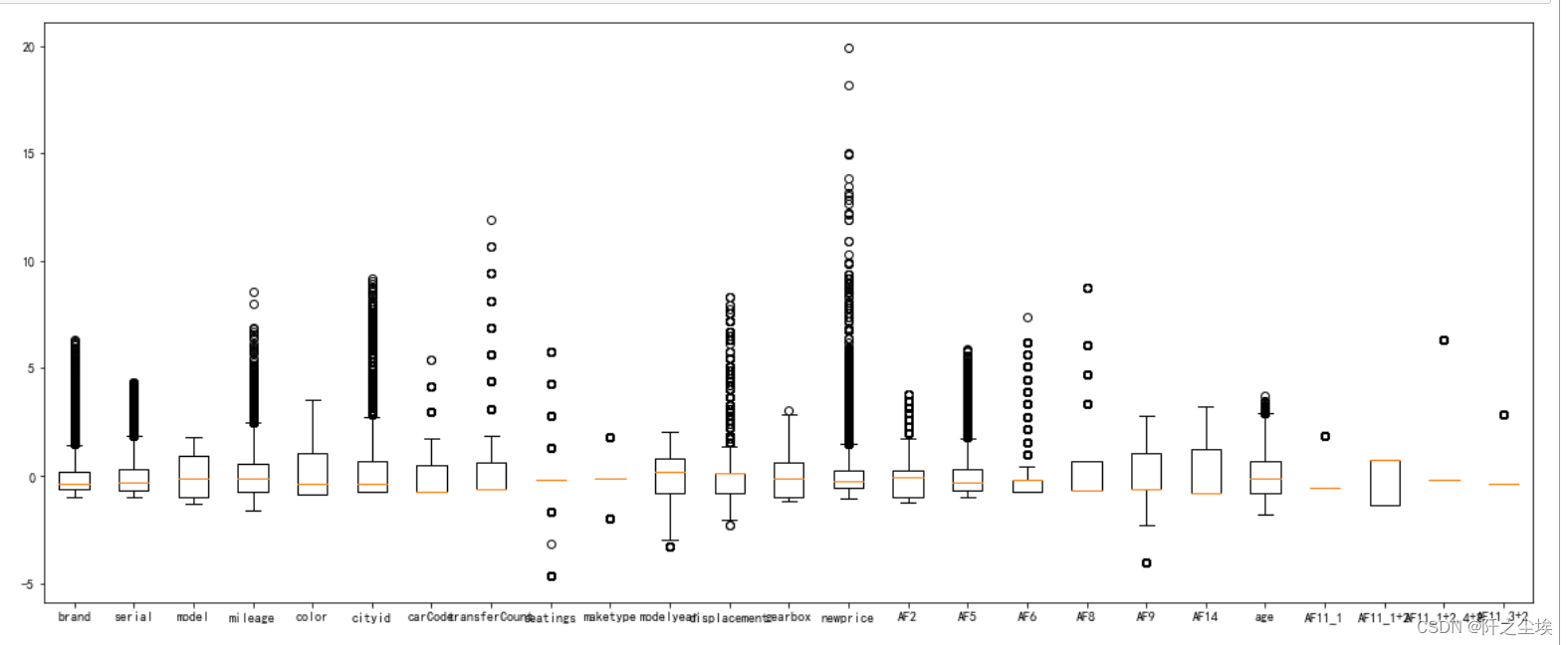
可以看到,newprice这个变量的异常点有点多,,, 后面要处理一下
测试集的箱线图,也差不多就不展示了
plt.figure(figsize=(20,8))
plt.boxplot(x=X2_s,labels=data2.columns)
#plt.hlines([-10,10],0,len(columns))
plt.show()#异常值多的列进行处理
def deal_outline(data,col,n): #数据,要处理的列名,几倍的方差
for c in col:
mean=data[c].mean()
std=data[c].std()
data=data[(data[c]>mean-n*std)&(data[c]<mean+n*std)]
#print(data.shape)
return data这个函数传入三个参数,要处理的数据框,异常值多的变量列名,还有筛掉几倍的方差。我下面选用的是10,也是就说如果一个样本数据大于整体10倍的标准差之外就筛掉。
data=deal_outline(data,['newprice'],10)
y=y[data.index]
data.shape,y.shape
样本又变少了一点。
相关系数矩阵
如果全是数值型变量就用皮尔逊相关系数。由于这里的X的分类变量有点多,我采用了斯皮尔曼相关系数计算,画出热力图。在训练集上带上了y
corr = plt.subplots(figsize = (18,16),dpi=128)
corr= sns.heatmap(data.assign(Y=y).corr(method='spearman'),annot=True,square=True)
从图中可以看出每个变量之间的相关性。最主要的看Y和谁的相关性高。我们这里的y,也就是二手车价格,和newprice,也就是新车的价格相关性最高。
测试集也差不多,不展示了
corr = plt.subplots(figsize = (18,16),dpi=128)
corr= sns.heatmap(data2.corr(method='spearman'),annot=True,square=True)特征工程差不多结束了
当然还可以进行降维等操作(PCA,RFE,LDA,正则化),但我这里特征目前才25个,不多,就不用降维 了
开始机器学习!
对前面的X也就是data,还有Y,也就是y,进行训练集和验证集的划分
#划分训练集和验证集
from sklearn.model_selection import train_test_split
X_train,X_val,y_train,y_val=train_test_split(data,y,test_size=0.2,random_state=0)#数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_s = scaler.transform(X_train)
X_val_s = scaler.transform(X_val)
X2_s=scaler.transform(data2)
print('训练数据形状:')
print(X_train_s.shape,y_train.shape)
print('验证测试数据形状:')
(X_val_s.shape,y_val.shape,X2_s.shape)
模型选择
学过李航的书应该都了解常见的回归算法,我这里选择了十种算法模型,企业对比他们在验证集的精度,再来进一步选择模型。
#采用十种模型,对比验证集精度
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import ElasticNet
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from xgboost.sklearn import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.svm import SVR
from sklearn.neural_network import MLPRegressor#线性回归
model1 = LinearRegression()
#弹性网回归
model2 = ElasticNet(alpha=0.05, l1_ratio=0.5)
#K近邻
model3 = KNeighborsRegressor(n_neighbors=10)
#决策树
model4 = DecisionTreeRegressor(random_state=77)
#随机森林
model5= RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
#梯度提升
model6 = GradientBoostingRegressor(n_estimators=500,random_state=123)
#极端梯度提升
model7 = XGBRegressor(objective='reg:squarederror', n_estimators=1000, random_state=0)
#轻量梯度提升
model8 = LGBMRegressor(n_estimators=1000,objective='regression', # 默认是二分类
random_state=0)
#支持向量机
model9 = SVR(kernel="rbf")
#神经网络
model10 = MLPRegressor(hidden_layer_sizes=(16,8), random_state=77, max_iter=10000)
model_list=[model1,model2,model3,model4,model5,model6,model7,model8,model9,model10]
model_name=['线性回归','惩罚回归','K近邻','决策树','随机森林','梯度提升','极端梯度提升','轻量梯度提升','支持向量机','神经网络']拟合对比
for i in range(10):
model_C=model_list[i]
name=model_name[i]
model_C.fit(X_train_s, y_train)
s=model_C.score(X_val_s, y_val)
print(name+'方法在验证集的准确率为:'+str(s))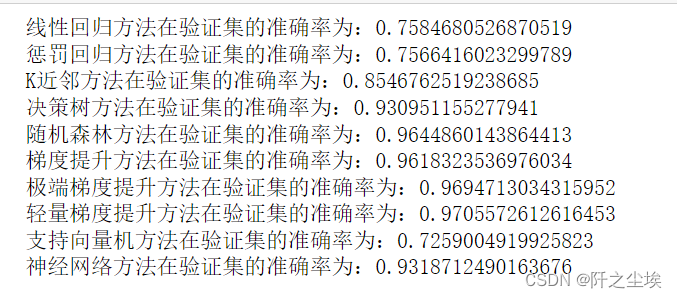
一般来说,对于这种表格数据,集成模型方法都是最好的,也就是XGB,LGBM,RF等。前人的经验也都是这样说的。使用后面交叉验证我们只选三个模型,随机森林,极端梯度提升,轻量梯度提升。
交叉验证
回归问题交叉验证,可以使用拟合优度,mae, rmse, mape 作为评价标准
交叉验证也可以直接使用sklearn库的cross_val_score,但是这个不能自定义评价准则,所以我这里手动循环去进行K折交叉验证。采用R2,mae,rmse,mape 四个指标作为评价标准。然后使用不同的随机数种子多次K折交叉验证,将每次K折交叉验证的结果均值和方差记录下来。再和每个模型都进行对比。
#回归问题交叉验证,使用拟合优度,mae,rmse,mape 作为评价标准
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error,r2_score
from sklearn.model_selection import KFold
def evaluation(y_test, y_predict):
mae = mean_absolute_error(y_test, y_predict)
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mean_squared_error(y_test, y_predict))
mape=(abs(y_predict -y_test)/ y_test).mean()
r_2=r2_score(y_test, y_predict)
return mae, rmse, mape
def evaluation2(lis):
array=np.array(lis)
return array.mean() , array.std()def cross_val(model=None,X=None,Y=None,K=5,repeated=1):
df_mean=pd.DataFrame(columns=['R2','MAE','RMSE','MAPE'])
df_std=pd.DataFrame(columns=['R2','MAE','RMSE','MAPE'])
for n in range(repeated):
print(f'正在进行第{n+1}次重复K折.....随机数种子为{n}n')
kf = KFold(n_splits=K, shuffle=True, random_state=n)
R2=[]
MAE=[]
RMSE=[]
MAPE=[]
print(f" 开始本次在{K}折数据上的交叉验证.......n")
i=1
for train_index, test_index in kf.split(X):
print(f' 正在进行第{i}折的计算')
X_train=X.values[train_index]
y_train=y.values[train_index]
X_test=X.values[test_index]
y_test=y.values[test_index]
model.fit(X_train,y_train)
score=model.score(X_test,y_test)
R2.append(score)
pred=model.predict(X_test)
mae, rmse, mape=evaluation(y_test, pred)
MAE.append(mae)
RMSE.append(rmse)
MAPE.append(mape)
print(f' 第{i}折的拟合优度为:{round(score,4)},MAE为{round(mae,4)},RMSE为{round(rmse,4)},MAPE为{round(mape,4)}')
i+=1
print(f' ———————————————完成本次的{K}折交叉验证———————————————————n')
R2_mean,R2_std=evaluation2(R2)
MAE_mean,MAE_std=evaluation2(MAE)
RMSE_mean,RMSE_std=evaluation2(RMSE)
MAPE_mean,MAPE_std=evaluation2(MAPE)
print(f'第{n+1}次重复K折,本次{K}折交叉验证的总体拟合优度均值为{R2_mean},方差为{R2_std}')
print(f' 总体MAE均值为{MAE_mean},方差为{MAE_std}')
print(f' 总体RMSE均值为{RMSE_mean},方差为{RMSE_std}')
print(f' 总体MAPE均值为{MAPE_mean},方差为{MAPE_std}')
print("n====================================================================================================================n")
df1=pd.DataFrame(dict(zip(['R2','MAE','RMSE','MAPE'],[R2_mean,MAE_mean,RMSE_mean,MAPE_mean])),index=[n])
df_mean=pd.concat([df_mean,df1])
df2=pd.DataFrame(dict(zip(['R2','MAE','RMSE','MAPE'],[R2_std,MAE_std,RMSE_std,MAPE_std])),index=[n])
df_std=pd.concat([df_std,df2])
return df_mean,df_std对LGBM使用,进行5次k折交叉验证,每次3折。
model = LGBMRegressor(n_estimators=1000,objective='regression',random_state=0)
lgb_crosseval,lgb_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)
这里就不展示完了。总之会返回两个表,记录每次K折的四个平均指标。一个返回均值,一个返回标准差。
查看lgb的均值表
lgb_crosseval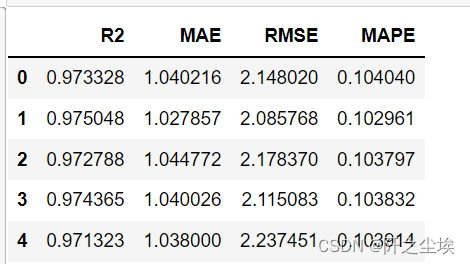
然后我们对xgb和rf都进行重复的K折交叉验证。记录表
model = XGBRegressor(n_estimators=1000,objective='reg:squarederror',random_state=0)
xgb_crosseval,xgb_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)model = RandomForestRegressor(n_estimators=500, max_features=int(X_train.shape[1]/3) , random_state=0)
rf_crosseval,rf_crosseval2=cross_val(model=model,X=data,Y=y,K=3,repeated=5)plt.subplots(1,4,figsize=(16,3))
for i,col in enumerate(lgb_crosseval.columns):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(lgb_crosseval[col], 'k', label='LGB')
plt.plot(xgb_crosseval[col], 'b-.', label='XGB')
plt.plot(rf_crosseval[col], 'r-^', label='RF')
plt.title(f'不同模型的{col}对比')
plt.xlabel('重复交叉验证次数')
plt.ylabel(col,fontsize=16)
plt.legend()
plt.tight_layout()
plt.show()
黑色是LGB,很明显我们可以看到在拟合优度上LGB明显好于其他两个模型,其他三个误差指标上看,lgb都是最小的。四个指标都说明LGB最好。
再来画方差图
plt.subplots(1,4,figsize=(16,3))
for i,col in enumerate(lgb_crosseval2.columns):
n=int(str('14')+str(i+1))
plt.subplot(n)
plt.plot(lgb_crosseval2[col], 'k', label='LGB')
plt.plot(xgb_crosseval2[col], 'b-.', label='XGB')
plt.plot(rf_crosseval2[col], 'r-^', label='RF')
plt.title(f'不同模型的{col}方差对比')
plt.xlabel('重复交叉验证次数')
plt.ylabel(col,fontsize=16)
plt.legend()
plt.tight_layout()
plt.show()
方差代表稳定性,可以看到三个模型的方差都差不多,稳定性都差不多。
并且在运行的时候,LGBM的时间是小于XGB小于随机森林的。
所以综合他们的表现效果、稳定性、运行时间来看——LGBM优于XGB优于RF。
搜超参数
sklearn库的超参数搜索有两种,一种是网格化搜参,也是暴力搜索,遍历每一种可能性。一种是随机搜索,在超参数的解空间随机选。
网格化出来的一定是最优解,而随机搜索出来的可能是局部最优。但是为什么我们还是会用随机搜索,因为网格搜索花费时间太多了,超参数很多情况下,遍历每一种可能是不现实的,只能随机搜索,找个还可以的超参数用用。
LGBM的调参思路一般都是先对决策树的参数进行调整,然后再去调整学习率和估计器个数。
#利用K折交叉验证搜索最优超参数
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.model_selection import GridSearchCV,RandomizedSearchCV# Choose best hyperparameters by RandomizedSearchCV
#随机搜索决策树的参数
param_distributions = {'max_depth': range(4, 10), 'subsample':np.linspace(0.5,1,5 ),'num_leaves': [15, 31, 63, 127],
'colsample_bytree': [0.6, 0.7, 0.8, 1.0]}
# 'min_child_weight':np.linspace(0,0.1,2 ),
kfold = KFold(n_splits=3, shuffle=True, random_state=1)
model =RandomizedSearchCV(estimator= LGBMRegressor(objective='regression',random_state=0),
param_distributions=param_distributions, n_iter=200)
model.fit(X_train_s, y_train)这里的n_iter=200表示搜索200次,200次就花费了我三分多钟。。
查看最优参数
model.best_params_
model = model.best_estimator_
model.score(X_val_s, y_val)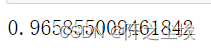
#网格化搜索学习率和估计器个数
param_grid={'learning_rate': np.linspace(0.05,0.3,6 ), 'n_estimators':[100,500,1000,1500, 2000]}
model =GridSearchCV(estimator= LGBMRegressor(objective='regression',random_state=0), param_grid=param_grid, cv=3)
model.fit(X_train_s, y_train)最优参数
model.best_params_
model = model.best_estimator_
model.score(X_val_s, y_val)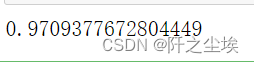
然后将寻找到的最优参数传入模型,再次进行拟合评价
#利用找出来的最优超参数在所有的训练集上训练,然后预测
model=LGBMRegressor(objective='regression',subsample=0.875,learning_rate= 0.05,n_estimators= 2500,num_leaves=127,
max_depth= 9,colsample_bytree=0.8,random_state=0)
model.fit(X_train_s, y_train)
model.score(X_val_s, y_val)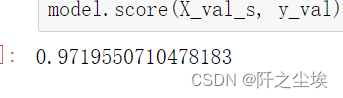
可以看到拟合优度上升了一点点。
当然有时间有算力可以继续搜索,还可以使用优化算法,启发式智能算法去搜索更好的超参数。
变量重要性排序图
用前面的最优模型在全部训练集数据上训练
model=LGBMRegressor(objective='regression',subsample=0.875,learning_rate= 0.05,n_estimators= 2500,num_leaves=127,
max_depth= 9,colsample_bytree=0.8,random_state=0)
model.fit(data.to_numpy(),y.to_numpy())
model.score(data.to_numpy(), y.to_numpy())![]()
画出变量重要性排序图
sorted_index = model.feature_importances_.argsort()
plt.barh(range(data.shape[1]), model.feature_importances_[sorted_index])
plt.yticks(np.arange(data.shape[1]), data.columns[sorted_index])
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.title('Gradient Boosting')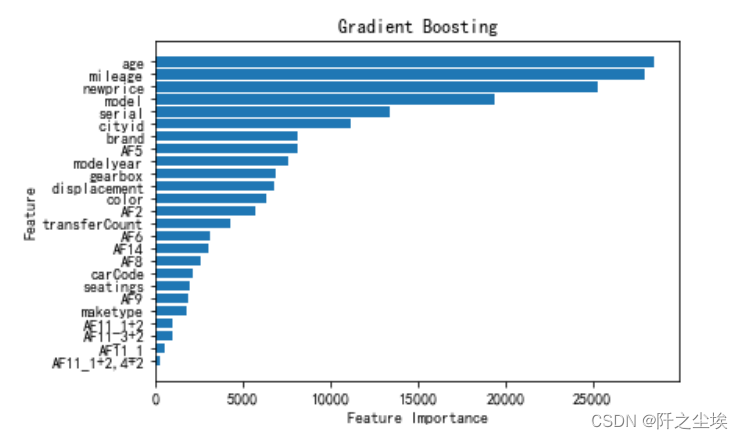
可以看到对二手车价格影响最大的变量是车龄age,车跑的里程数mileage,还有同款新车的价格newprice。
预测储存
对测试集进行预测,然后和车的编号id放一起存起来。就可以提交了
pred = model.predict(data2)
df=pd.DataFrame(ID)
df['price']=pred
df.to_csv('全部数据预测结果.csv',index=False) 储存的效果。
储存的效果。
原文地址:https://blog.csdn.net/weixin_46277779/article/details/126448518
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34174.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







