goquery 简介
goquery是一款基于Go语言的HTML解析库,它使用了类似于jQuery的语法,使得在Go语言中进行HTML解析变得更加方便。使用goquery,开发者可以在HTML文档中轻松地查询、遍历和操作文档中的各种元素和属性。
总的来说,goquery是一款非常实用的HTML解析工具,它可以大大简化开发者在Go语言中进行HTML解析的工作。
goquery quick start
Document 是 goquery 包的核心类之一,创建一个 Document 是使用 goquery 的第一步:
type Document struct {
*Selection
Url *url.URL
rootNode *html.Node
}
func NewDocumentFromNode(root *html.Node) *Document
func NewDocument(url string) (*Document, error)
func NewDocumentFromReader(r io.Reader) (*Document, error)
func NewDocumentFromResponse(res *http.Response) (*Document, error)通过源码可以知道 Document 继承了 Selection(先不管 Selection 是什么),除此之外最重要的是rootNode,它是 HTML 的根节点,Url这个字段作用不大,在使用NewDocument和NewDocumentFromResponse时会对该字段赋值。
拥有Document类后,我们就可以利用从Selection类继承的Find函数来获得自己想要的数据,比如我们想拿到
func TestFind(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div>DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("div").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind
DIV1
DIV2玩转goquery.Find()
goquery 提供了大量的函数,个人认为最重要的是Find函数,把它用好了才能快速从大量文本中筛选出我们想要的数据,下面这一章主要展示使用Find函数的各种姿势:
查找多个标签
func TestMultiFind(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div>DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("div,span").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestMultiFind
DIV1
DIV2
SPANId 选择器
func TestFind_IdSelector(t *testing.T) {
html := `<body>
<div id="div1">DIV1</div>
<div>DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("#div1").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_IdSelector
DIV1Class 选择器
func TestFind_ClassSelector(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div class="name">DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find(".name").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_ClassSelector
DIV2属性选择器
func TestFind_AttributeSelector(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div lang="zh">DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("div[lang]").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_AttributeSelector
DIV2func TestFind_AttributeSelector_2(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div lang="zh">DIV2</div>
<div lang="en">DIV3</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("div[lang=zh]").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_AttributeSelector_2
DIV2| 选择器 | 说明 |
|---|---|
| Find(“div[lang]”) | 筛选含有lang属性的div元素 |
| Find(“div[lang=zh]”) | 筛选lang属性为zh的div元素 |
| Find(“div[lang!=zh]”) | 筛选lang属性不等于zh的div元素 |
| Find(“div[lang¦=zh]”) | 筛选lang属性为zh或者zh-开头的div元素 |
| Find(“div[lang*=zh]”) | 筛选lang属性包含zh这个字符串的div元素 |
| Find(“div[lang~=zh]”) | 筛选lang属性包含zh这个单词的div元素,单词以空格分开的 |
| Find(“div[lang$=zh]”) | 筛选lang属性以zh结尾的div元素,区分大小写 |
| Find(“div[lang^=zh]”) | 筛选lang属性以zh开头的div元素,区分大小写 |
当然也可以将多个属性筛选器组合,比如:Find("div[id][lang=zh]")
子节点选择器
使用>代表子节点选择器。
func TestFind_ChildrenSelector(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div>DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("body>span").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_ChildrenSelector
SPAN内容过滤器
func TestFind_ContentFilter_Contains(t *testing.T) {
html := `<body>
<div>DIV1</div>
<div>DIV2</div>
<span>SPAN</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("div:contains(V2)").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_ContentFilter_Contains
DIV2过滤节点
func TestFind_ContentFilter_Has(t *testing.T) {
html := `<body>
<span>SPAN1</span>
<span>
SPAN2
<div>DIV</div>
</span>
</body>
`
dom, err := goquery.NewDocumentFromReader(strings.NewReader(html))
if err != nil {
log.Fatalln(err)
}
dom.Find("span:has(div)").Each(func(i int, selection *goquery.Selection) {
fmt.Println(selection.Text())
})
}
------------运行结果--------------
=== RUN TestFind_ContentFilter_Has
SPAN2
DIV此外,还有:first-child、:first-of-type过滤器分别可以筛选出第一个子节点、第一个同类型的子节点。
相应的:last-child、:last-of-type、:nth-child(n)、:nth-of-type(n)用法类似,不做过多解释。
goquery 源码分析
func (s *Selection) Find(selector string) *Selection {
return pushStack(s, findWithMatcher(s.Nodes, compileMatcher(selector)))
}func pushStack(fromSel *Selection, nodes []*html.Node) *Selection {
result := &Selection{nodes, fromSel.document, fromSel}
return result
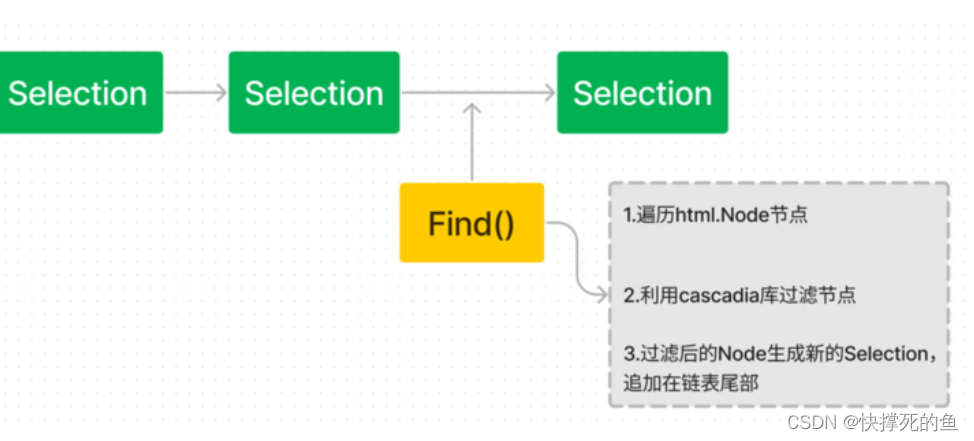
}该函数就是拿着nodes参数去创建一个新的 Selection 类,构建一个 Selection 链表。
无论是函数命名pushStack,还是 Selection 类的字段都可以证实上面的判断:
type Selection struct {
Nodes []*html.Node
document *Document
prevSel *Selection // 上一个节点的地址
}现在焦点来到了pushStack函数的nodes参数,nodes参数是什么直接决定了我们构建了一个怎样的链表、决定了Find函数的最终返回值,这就需要我们研究下findWithMatcher函数的实现:
func findWithMatcher(nodes []*html.Node, m Matcher) []*html.Node {
return mapNodes(nodes, func(i int, n *html.Node) (result []*html.Node) {
for c := n.FirstChild; c != nil; c = c.NextSibling {
if c.Type == html.ElementNode {
result = append(result, m.MatchAll(c)...)
}
}
return
})
}findWithMatcher函数 的功能由mapNodes函数实现:
func mapNodes(nodes []*html.Node, f func(int, *html.Node) []*html.Node) (result []*html.Node) {
set := make(map[*html.Node]bool)
for i, n := range nodes {
if vals := f(i, n); len(vals) > 0 {
result = appendWithoutDuplicates(result, vals, set)
}
}
return result
}mapNodes函数把参数f的返回值[]*html.Node做去重处理,所以重点在于这个参数f func(int, *html.Node) []*html.Node的实现:
func(i int, n *html.Node) (result []*html.Node) {
for c := n.FirstChild; c != nil; c = c.NextSibling {
if c.Type == html.ElementNode {
result = append(result, m.MatchAll(c)...)
}
}
return
}函数遍历html.Node节点,并利用MatchAll函数筛选出想要的数据
type Matcher interface {
Match(*html.Node) bool
MatchAll(*html.Node) []*html.Node
Filter([]*html.Node) []*html.Node
}
func compileMatcher(s string) Matcher {
cs, err := cascadia.Compile(s)
if err != nil {
return invalidMatcher{}
}
return cs
}MatchAll函数由Matcher接口定义,而compileMatcher(s string)恰好通过利用cascadia库返回一个Matcher实现类,其参数s就是我们上文提到的匹配规则,比如dom.Find("div")
图解源码
使用Find函数时,goquery 做了什么:
总结
本文主要介绍了 goquery 最核心的Find函数的用法及其源码实现,其实除了Find函数,goquery 还提供了大量的函数帮助我们过滤数据,因为函数众多且没那么重要,本人就没有继续研究,以后有机会再深入研究下。
原文地址:https://blog.csdn.net/qq_38334677/article/details/129225231
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34208.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!