本文介绍: bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。字符串类型:体现在单个value值很大,一般认为超过10KB就是bigkey,但这个值和具体的OPS相关。非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。bigkey无论是空间复杂度和时间复杂度都不太友好,下面我们将介绍它的危害。
BigKey
1.什么是bigkey
bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。
如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。
字符串类型:体现在单个value值很大,一般认为超过10KB就是bigkey,但这个值和具体的OPS相关。
非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。
bigkey无论是空间复杂度和时间复杂度都不太友好,下面我们将介绍它的危害。
2.bigkey的危害
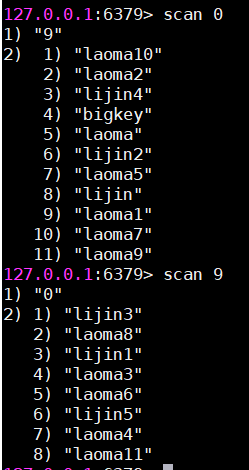
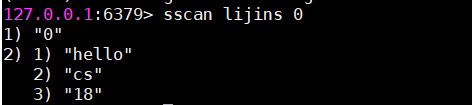
3.发现bigkey
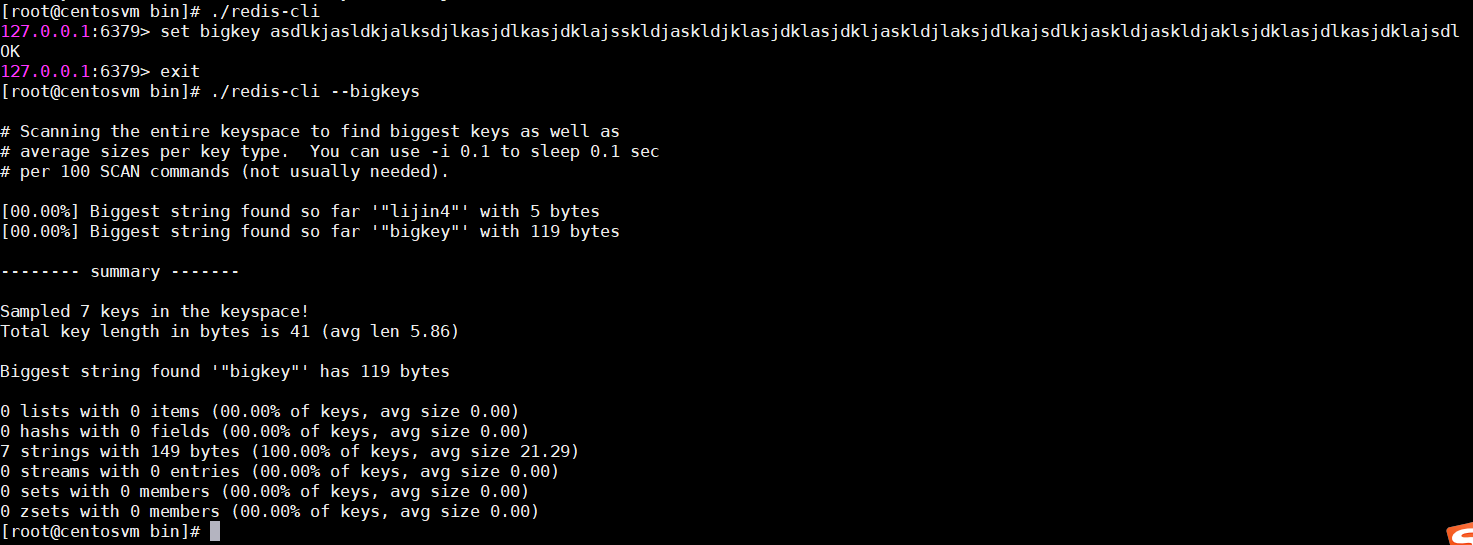

scan
4.解决bigkey
什么是热点Key?该如何解决
1. 产生原因和危害
原因
危害
2.发现热点key
预估发现
客户端发现
Redis发现
monitor命令

hotkeys



抓取TCP包发现
3. 解决热点key
使用二级缓存
key分散
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。