本文介绍: 在页的内部建立分组(包括最大和最小记录,但不包括被删除了的记录)。按照从小到大顺序排列,每组的最大的记录的头信息(file_header)存储着本组记录的数量(见粉红色字段)。页目录存储的是最后一条记录的地址偏移量(槽、slot,相当于页目录有个指针,指向每个组的最后一条记录)。那页中有很多行数据,是怎么执行查询的呢,首先我们肯定,是以单向列表形式存储的,提高了增删的效率,但是查询效率低。其实B+树的每个节点都是一页,只不过非叶子节点的数据是指针。二级索引就是建立的索引,叶子节点存放的是主键值,
innoDB是按照页为单位读写的
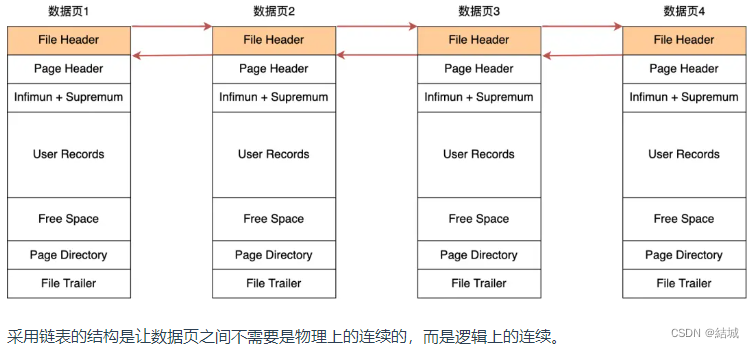
那页中有很多行数据,是怎么执行查询的呢,首先我们肯定,是以单向列表形式存储的,提高了增删的效率,但是查询效率低。所以实际上对页中的行数据进行了优化,能以二分的方式进行查询,执行这一操作的机制叫做页目录,在页的内部建立分组(包括最大和最小记录,但不包括被删除了的记录)。按照从小到大顺序排列,每组的最大的记录的头信息(file_header)存储着本组记录的数量(见粉红色字段)。页目录存储的是最后一条记录的地址偏移量(槽、slot,相当于页目录有个指针,指向每个组的最后一条记录)。所以二分就能根据每个slot的最大值判定当前查询应该去哪个分组。
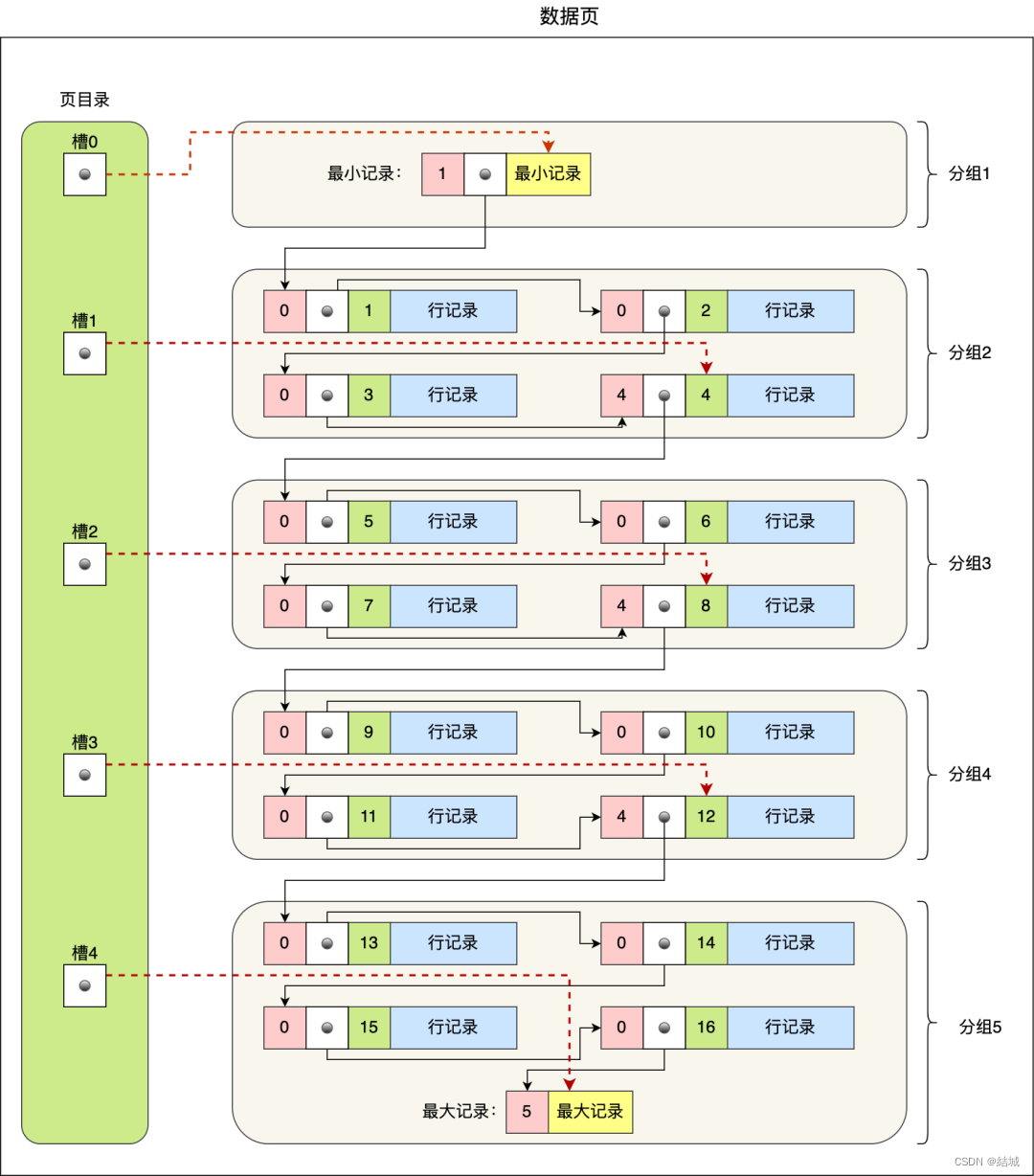
然后我们抽象到更高层次,页如何被查询的?其实B+树的每个节点都是一页,只不过非叶子节点的数据是指针。叶子节点才是真的数据。
然后索引又分为聚簇索引和二级索引。
聚簇索引一般是主键索引,如果没有主键就选不包含NULL值得唯一列,如果还没有MySQL会创建一个隐藏的自增id列当作聚簇索引。聚簇索引叶子节点存的是真实数据。
二级索引就是建立的索引,叶子节点存放的是主键值,也就是说用了二级索引,查到后,还要用查到的主键值再查一遍聚簇索引才能获取数据结果,这个过程叫做回表。但假如你要查的就是主键,那就只查一次即可。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。