本文介绍: 在 Spoon 主界面的左侧项目栏的“核心对象”中,选择“Big Data”→“Hadoop File Output”, 拖拽该控件到右侧的设计区域,并与“剪切字符串”控件进行连接,连接时会出现两个选项,即“主输入步骤”和“错误处理步骤”,这里需要选择“主输入步骤”。双击鼠标打开“剪切字符串”控件属性设置对话框,将“输入流字段”设置为“Field1”, “输出流字段”不用改变,“起始位置”设置为 0,“结束位置”设置为10,单击“确定”按钮。如果转换过程成功执行,所有控件右上角都会显示“勾号”。
使用 Kettle 完成数据 ETL
现在我们有一份网站的日志数据集,准备使用Kettle进行数据ETL。先将数据集加载到Hadoop集群中,然后对数据进行清洗,最后加载到Hive中。
在本地新建一个数据集文件weblogdata.txt,文件内容如下所示:
在之前创建的作业中,点击“核心对象”标签,选择“通用”下面的“START”,拖曳1个“START”控件到右侧的设计区域。
在左侧项目栏的核心对象中,选择“Big Data”下面的“Hadoop Copy Files”控件,拖曳1个“Hadoop Copy Files”控件到右侧的设计区域。然后,单击“START”控件,在弹出的下拉选项中,选择最右侧的按钮,将箭头拖拽至“Hadoop Copy Files”控件,使得“Hadoop Copy Files”与“START”控件之间建立连接。
数据清洗
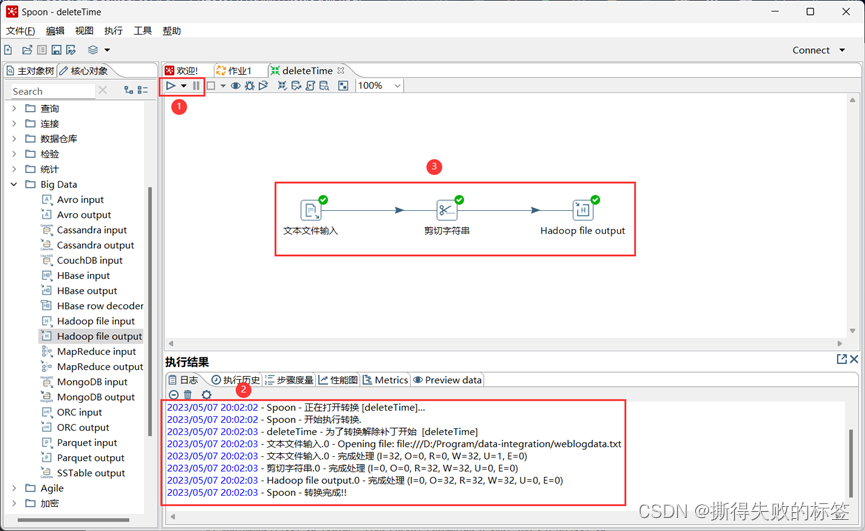
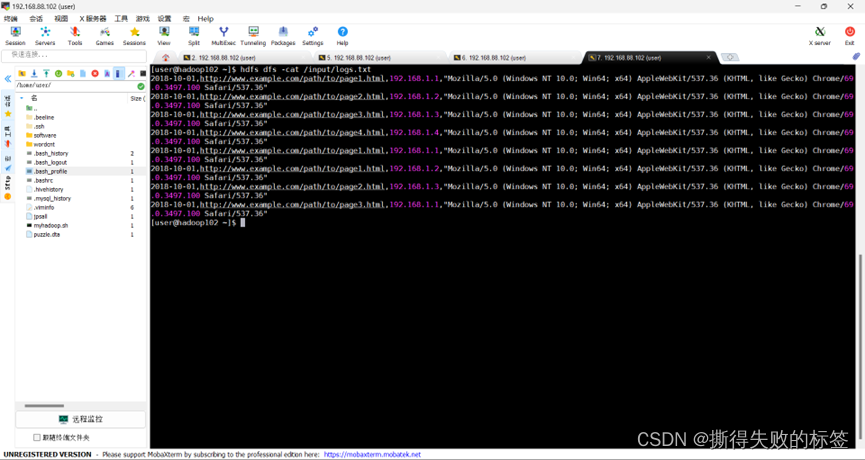
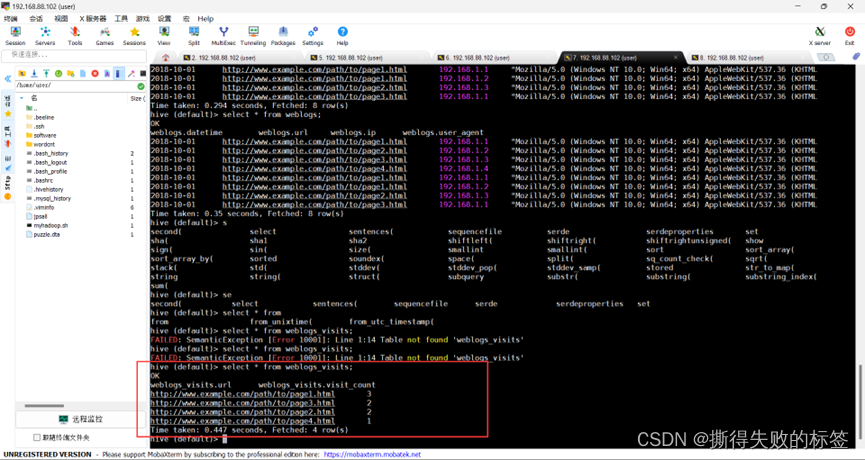
数据处理

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。