pandas
1 Series(序列)
1.1 基本概念

1.1.1 索引 ser[‘a’]、ser.a、ser[0]、ser.get(‘a’)



1.1.2 切片
1.1.2.1 基于标签切片的时候,切片区间全闭

1.1.2.2 基于位置的切片语法 切片区间左闭右开

1.1.3 选择和过滤
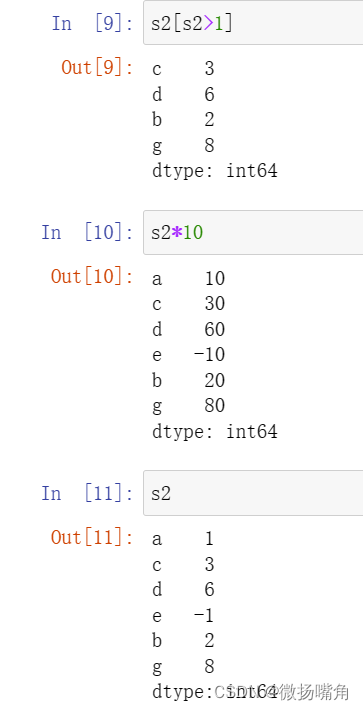
1.1.3.1 直接通过Series进行比较

1.1.3.2 通过Series.index 或者 Series.values进行比较

1.2 序列创建
1.2.1 列表,元组(一维)

1.2.2 标量

1.2.3 数组

1.2.4 字典

1.3 序列、索引名字及属性
1.3.1 序列的名字和索引名字

1.3.2 序列的属性

1.4 序列的运算
1.4.1 序列运算保留索引

1.4.2 序列运算,索引自动对齐


2 DataFrame
2.1 构建DataFrame
2.1.1 二维列表创建
通过二维列表,二维元组直接创建,默认行列索引

创建dataframe后添加行索引和列索引

创建dataframe的时候加上行索引和列索引

2.1.2 二维数组创建
创建dataframe时,默认行列索引

创建dataframe时,添加行列索引名
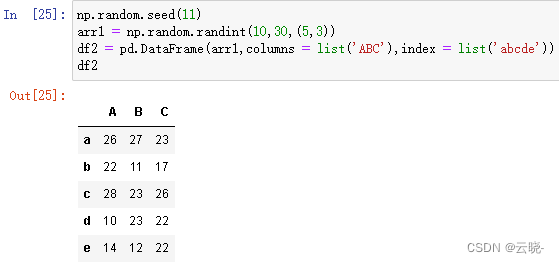
2.1.3 等长列表、 元组、 数组、 序列组成的字典创建
等长列表组成的字典

等长元组组成的字典

等长数组组成的字典

等长序列组成的字典

2.1.4 字典组成的字典创建

2.1.5 字典的列表创建

2.1.6 Series 创建DataFrame

2.2 二维结构数据转换
2.2.1 二维列表转其他

2.2.2 二维数组转其他

2.2.3 矩阵转其他

2.2.4 dataframe转其他

2.3 数据的读写
2.3.1 读写csv文件
2.3.2 读写excel文件
2.3.3 读html文件
2.3.4 读粘贴板数据
2.4 数据的查看
df.head() #默认前5行,想查看前几行,括号中写几
df.tail() #默认尾部5行,想查看尾部几行,括号中写几
df.sample(n = 4) #随机的抽取,n = 4随机抽取4行
df.shape #形状
df.dtypes #查看数据类型
df.isnull() #缺失值
df.info() #详细信息
df.index 行索引
df.columns 列名
2.5 索引和切片
2.5.1 行的选择
隐式索引,默认的索引选择行


显示索引,选取索引名


2.5.2 列的选择


2.5.3 行,列的选择:loc方式 显式
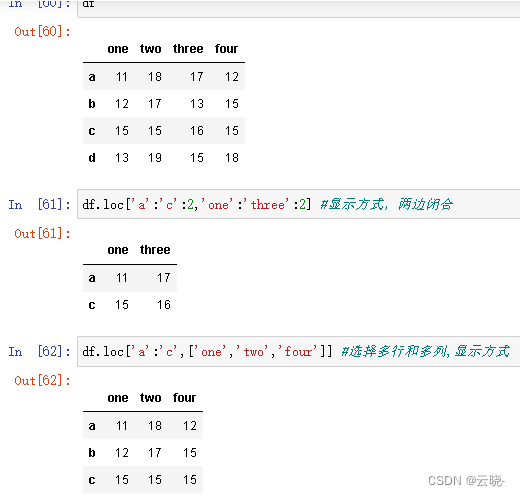

2.5.4 行,列的选择:iloc方式 隐式


2.5.5 过滤
选择满足条件的行

选择满足条件的列

选择满足条件的行和列

2.5.6 索引设置
将某列设置为索引:set_index

恢复默认索引:reset_index

创建一个适应新索引的新对象:reindex
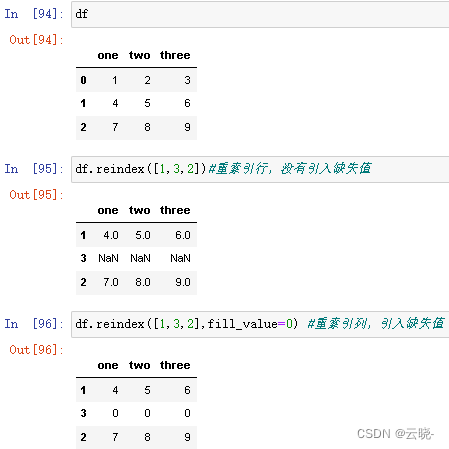
2.5.7 修改索引/列名

2.6 dataframe的增加和删除
2.6.1 新增行

2.6.2 新增列


2.6.3 删除行或列

 df.d
df.d


2.7 算术运算和对齐
2.7.1 dataframe之间相加


2.7.2 dataframe和数相加,每一个元素都进行操作

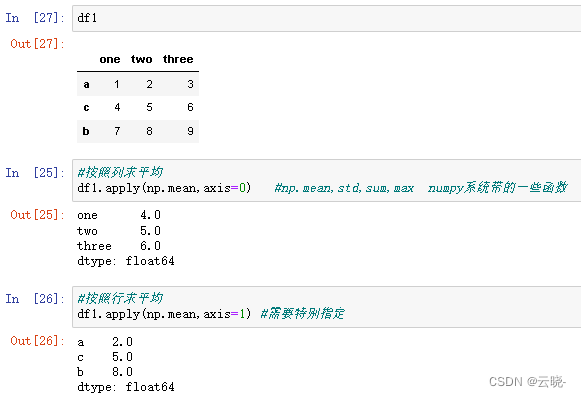
2.7.3 映射:apply,map,applymap
2.7.3.1 apply:针对行和列操作,可以对dataframe,可以对序列


2.7.3.2 map:对序列中的单个元素进行操作

2.7.3.3 applymap:对dataframe中的单个元素进行操作

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[面试题~]Golang](http://www.7code.cn/wp-content/uploads/2023/11/ee6748cbc735e6105405f8a984d954c804b93f34bc916-Z0IqTf_fw1200.png)