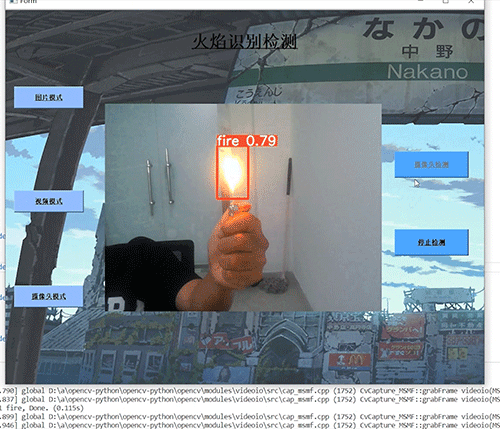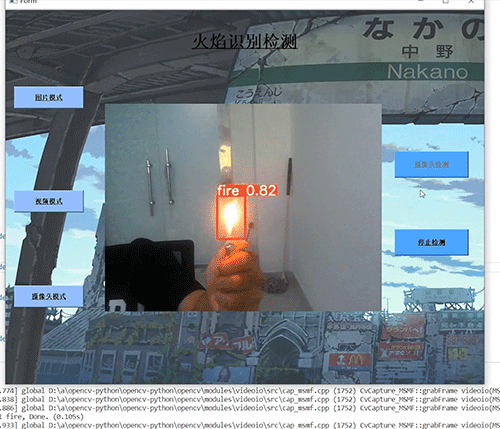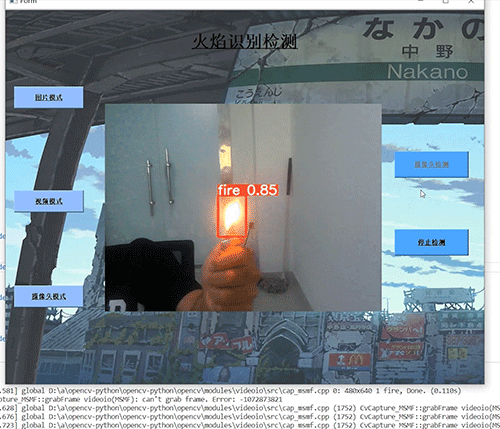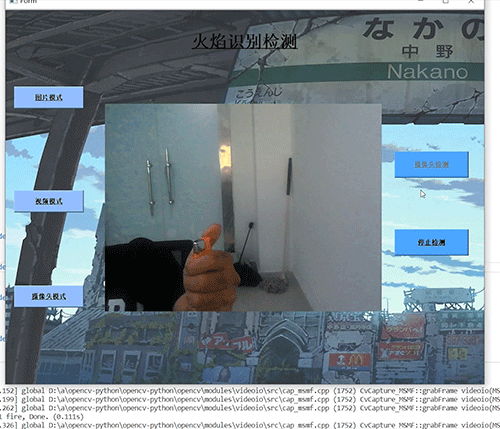
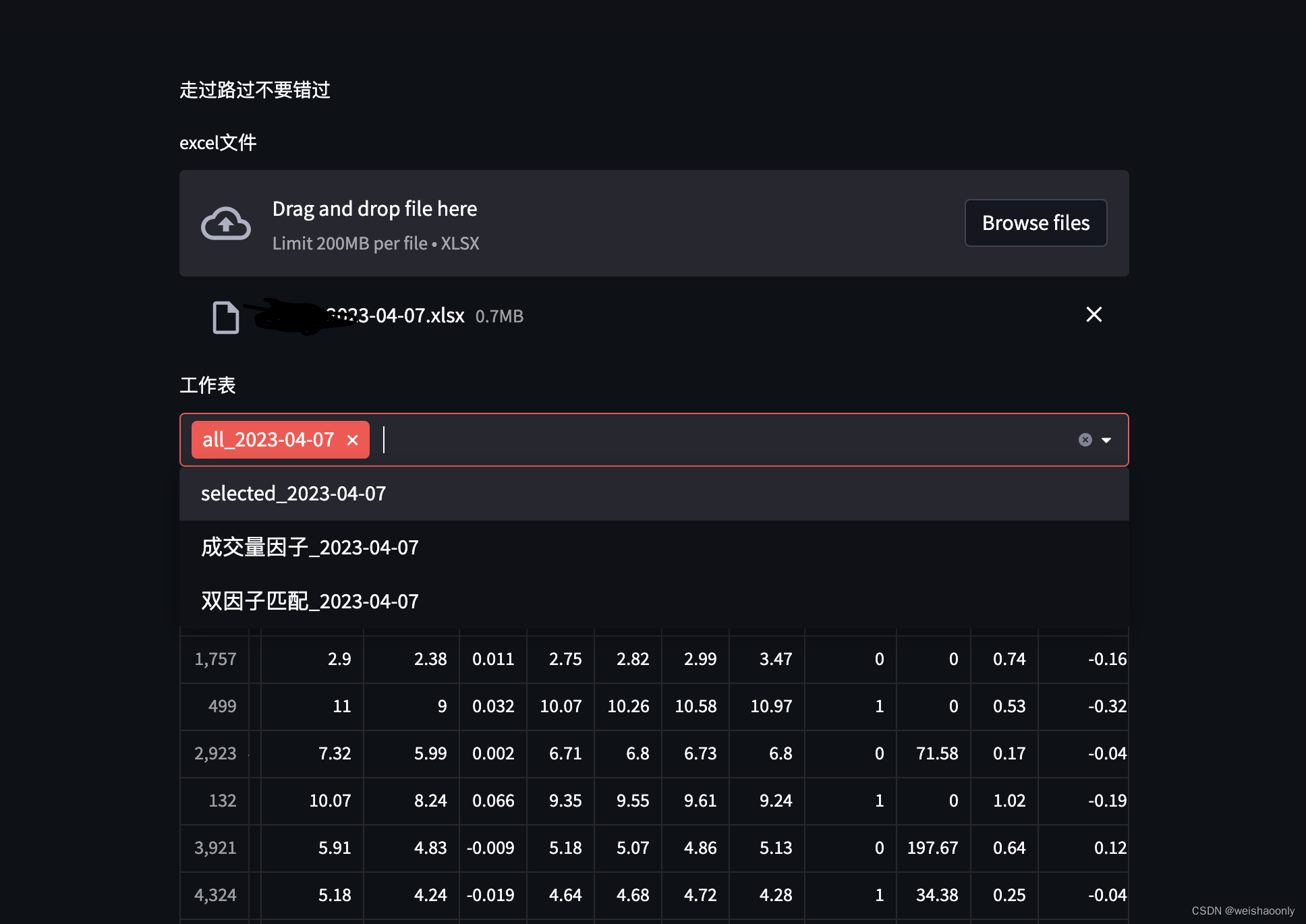
本文介绍: 在页面上点击组件,选择了一个文件,页面上的上传文件组件数据有了变化,于是页面通知后台重新执行一遍代码,同时页面把上传文件组件的文件数据返回给后台,代码开始重新执行第一句代码时,函数返回了页面给的文件数据,因此函数有了返回值,不再是None。千万别忘了,如果没有选择任何工作表,要提前跳出执行看看,效果,很不错。方法很简单,独定义一个函数,接收文件对象,函数里面就是 Pandas 加载数据的代码,然后在函数上方打上装饰器,表明这是一个缓存函数,为了证明其缓存函数生效,我们在函数里面打印内容,到控制台。
保存文件,此时页面右上角出现了一些选项按钮,选择总是返回,回到代码修改内容,现在页面可以自动刷新了。
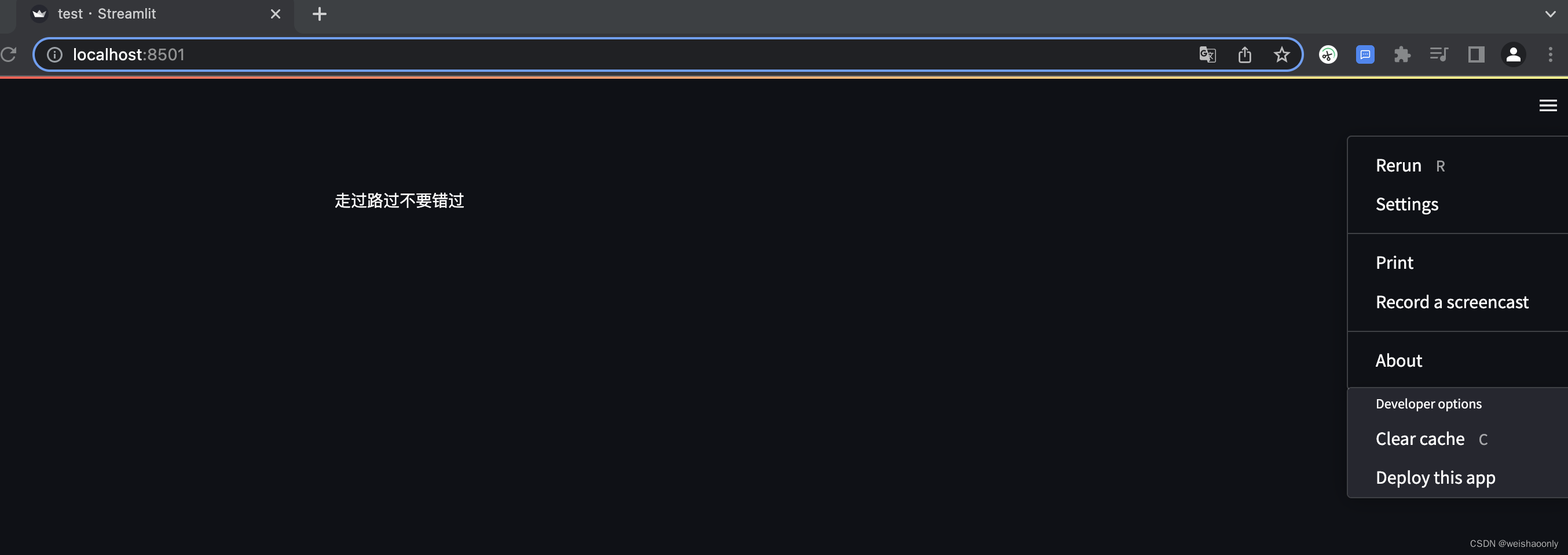
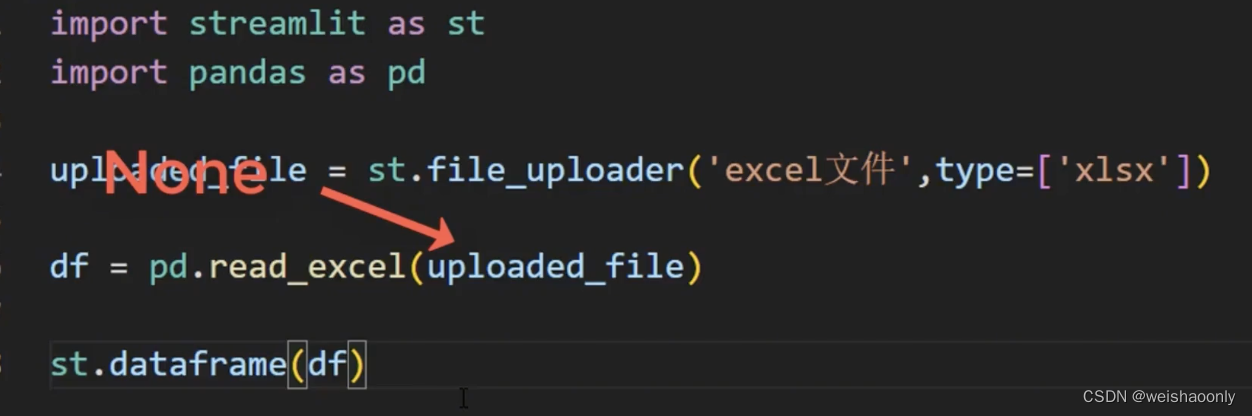
接下来添加一个文件上传的组件参数type,指定接受的文件后缀名可以指定多种文件类型,所以是一个列表函数返回的是一个文件对象。我们可以直接使用 Pandas 读取数据,然后试试输出到界面上,这里有一个快捷方式,直接把变量 df写在这里,就会在界面上显示成一个表格。不过保存文件后发现页面出现报错信息。
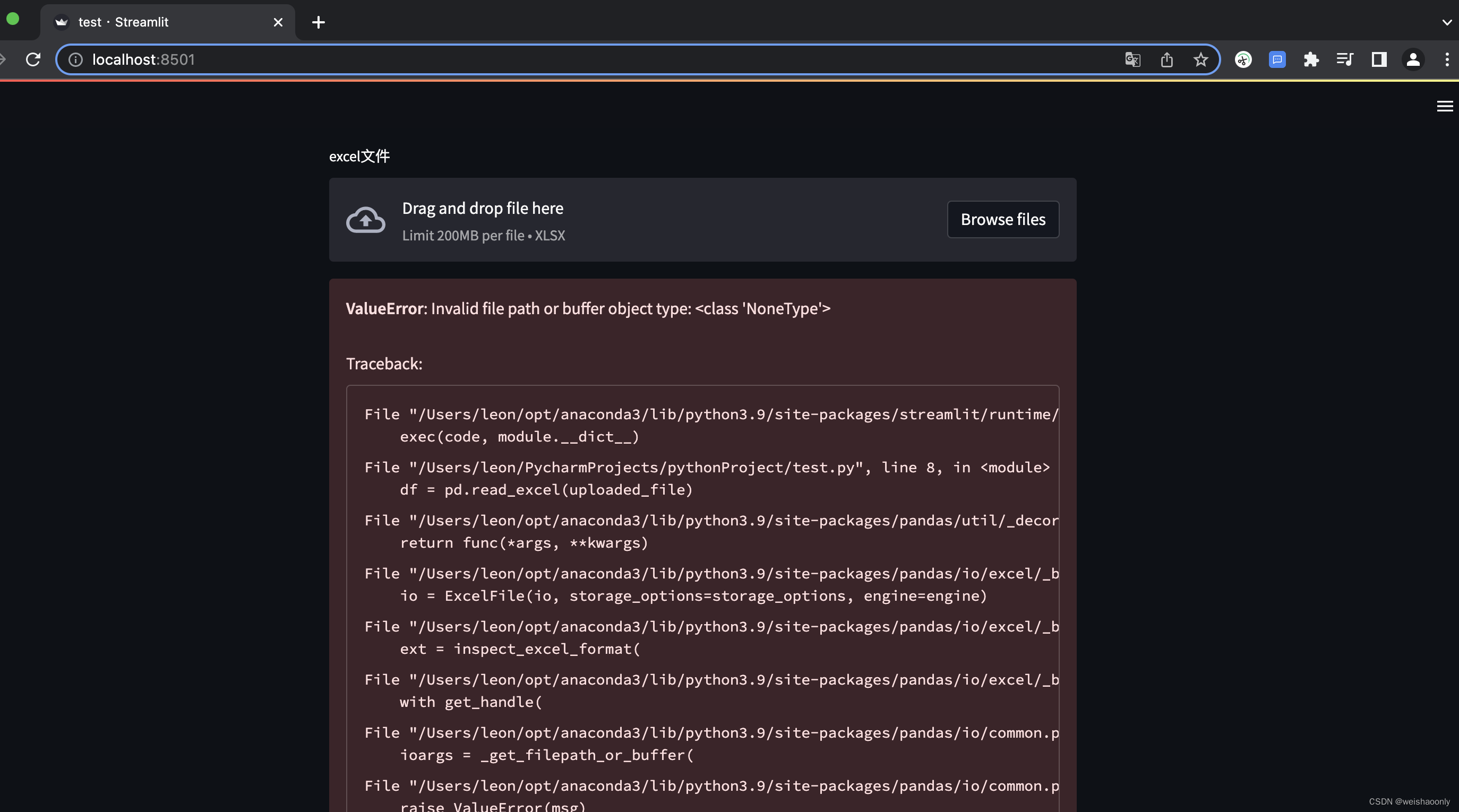
streamlit每次页面更新都会执行一遍代码,我们还没有选择任何文件,所以文件上传组件的函数返回了一个None,到了 Pandas 加载数据就会报错。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。