伴随着突发流量、系统变更或代码腐化等因素,性能退化随时会发生。如在周年庆大促期间由于访问量暴涨导致请求超时无法下单;应用发布变更后,页面频繁卡顿导致客诉上升;线上系统运行一段时间后,突然发生OOM或连接打满拒绝访问。
性能退化最直观的影响就是用户体验,比如打开一个商品详情页面的耗时从0.5s上升至3s,那么用户继续浏览的意愿度就会大幅下降。当性能进一步退化至超时阈值(比如5s),就会导致无法正常提供服务,影响服务可用性,进而带来巨额的业务损失或口碑崩坏。因此,性能退化不仅会损害用户体验或服务可用性,还可能决定着业务的成与败。
防治性能退化的最佳实践是“预防为主、防治结合”。由于性能退化一旦发生,就会不可避免的影响用户体验或业务数据,因此,应该尽可能在架构设计、代码编写、测试验证等阶段,提前完成性能优化,规避常见的性能问题。此外,在性能退化发生期间,能够及时识别性能风险,快速定位性能瓶颈,及时修复解决。
无论是提前预发,还是事后治理,都需要一套精准、实时的性能监控体系,帮助业务团队准确、快速的识别性能瓶颈点与影响面,针对性地采取下一步措施。越是复杂、庞大的IT系统,越需要建立完备、好用的性能监控体系,尽早介入,快速定位,降低危害。
性能监控是指在软件、硬件或系统运行期间对其性能指标进行监测和记录,以便分析和优化系统性能。通过收集和分析性能数据,可以识别系统瓶颈、优化资源分配、提高系统可靠性和稳定性等。性能监控通常包括对系统资源的监控,如CPU、内存、磁盘、网络等,以及对应用程序的监控,如响应时间、吞吐量、并发数等。
性能监控对象
性能监控的对象包括计算机系统、网络、应用程序等,主要分为以下几类:
- 服务器:包括物理服务器和虚拟服务器,监控服务器的CPU、内存、磁盘、网络等资源使用情况。
- 操作系统:监控操作系统的运行状态、进程、服务、文件系统等。
- 数据库:监控数据库的连接数、查询响应时间、事务处理等。
- 应用程序:包括Web应用、移动端App、分布式微服务应用等,监控应用程序的响应时间、吞吐量、并发数等。
- 网络设备:包括路由器、交换机、防火墙等,监控其网络流量、带宽、延迟等指标。
- 云服务:包括云中间件、云数据库等,监控其资源使用情况、网络延迟等指标。
通过对这些对象进行性能监控,可以及时发现问题,提高系统的性能和可用性。
性能监控指标是用于衡量系统或应用程序性能的量化指标。这些指标可以帮助开发人员和系统管理员了解系统或应用程序的运行状况,以及识别潜在的性能问题。常见的性能监控指标包括CPU使用率、内存使用率、磁盘I/O、网络带宽、响应时间、并发连接数、错误率、日志记录、资源利用率和事务处理量等。通过监控这些指标,可以及时发现系统或应用程序的性能问题,并采取相应的措施来优化性能,提高用户体验。常见的性能监控指标有以下几种:
耗时
耗时(Latency)作为黄金三指标之一,是度量应用接口性能的最佳指标。不同于请求量或错误数,对耗时次数或总量的统计通常不具备实用价值,最常用的耗时统计方式是平均耗时。比如10000次调用的耗时可能各不相同,将这些耗时相加再除以10000就得到了单次请求的平均耗时,它可以直观地反映当前系统的响应速度或用户体验。
不过,平均耗时有一个致命的缺陷,就是容易被异常请求的离散值干扰,比如100次请求里有99次请求耗时都是 10ms,但是有一次异常请求的耗时长达1分钟,最终平均下来的耗时就变成 (60000 + 10*99)/100 = 609.9ms。这显然无法反映系统的真实表现。因此,除了平均耗时,我们还经常使用耗时分位数和耗时分桶(可以借助耗时直方图进行观测)这两种统计方式来表达系统的响应情况。
耗时分位数
分位数,也叫做分位点,是指将一个随机变量的概率分布范围划分为几个等份的数值点,例如中位数(即二分位数)可以将样本数据分为两个部分,一部分的数值都大于中位数,另一部分都小于中位数。相对于平均值,中位数可以有效的排除样本值的随机扰动。
分位数被广泛应用于日常生活的各个领域,比如教育领域的成绩排布就大量使用了分位数的概念,某大学在A省招收100人,而该省有1万人报考该大学,那么该大学的录取分数线就是所有报考学生成绩的P99分位数,也就是排名前1%的同学可以被录取。无论该省的高考试题是偏难还是偏简单,都能准确录取到预定的招生人数。
将分位数应用在IT领域的耗时指标上,可以准确的反映接口服务的响应速度,比如P99分位数可以反映耗时最高的前1%接口请求的处理时间。对于这部分请求来说服务的响应速度可能已经达到了一个无法忍受的程度(例如30秒),相对于平均耗时,耗时P99分位数额外反映了3个重要的信息:
- 有1%的服务请求可能正在忍受一个超长的响应速度,而它影响到的用户是远大于1%的比例。因为一次终端用户请求会直接或间接的调用多个节点服务,只要任意一次变慢,就会拖慢整体的终端体验。另外,一个用户可能会执行多次操作,只要有一次操作变慢,就会影响整体的产品体验。
- 耗时P99分位数是对应用性能瓶颈的提前预警。当P99分位数超出可用性阈值时,反映了系统服务能力已经达到了某种瓶颈,如果不加处理,当流量继续增长时,超时请求影响的用户比例将会不断扩大。虽然你现在处理的只是这1% 的慢请求,但实际上是提前优化了未来5%、10%,甚至更高比例的慢请求。
- 根据经验表明,往往是那些数据体量大,查询条件复杂的“高端”用户更容易触发慢查询。同时,这部分用户通常是影响产品营收和口碑的高价值用户,需要优先响应解决。
除了 P99分位数,常用的耗时分位数还包括 P99.9、P95、P90、P50分位数,可以根据应用接口的重要性和服务质量承诺(SLA)选择适当的分位数进行监控和预警。当一条时间序列上的分位数连在一起就形成了一条“分位线”,可用于观察耗时是否存在异常的变化趋势,如下图所示:

耗时直方图
耗时分位数和平均值将接口响应速度抽象成了有限的几个数值,比较适合监控和告警。但是,如果要做深度的分析,识别所有请求的耗时分布情况,直方图是最适合的统计方式。
直方图的横坐标代表请求耗时,纵坐标代表请求次数,并且横/纵坐标值通常都是非等分的,因为耗时与次数的分布通常是不均衡的,使用非等分坐标轴更容易观测重要且低频的慢请求分布,而等分坐标轴很容易将低频值忽略掉。如下图所示,可以直观的发现不同耗时范围内的请求次数分布:耗时在100ms左右的请求次数最多,超过了10000次;耗时在5-10s范围内次数也不少,接近1000次,而超过30s以上的请求也有接近10次。
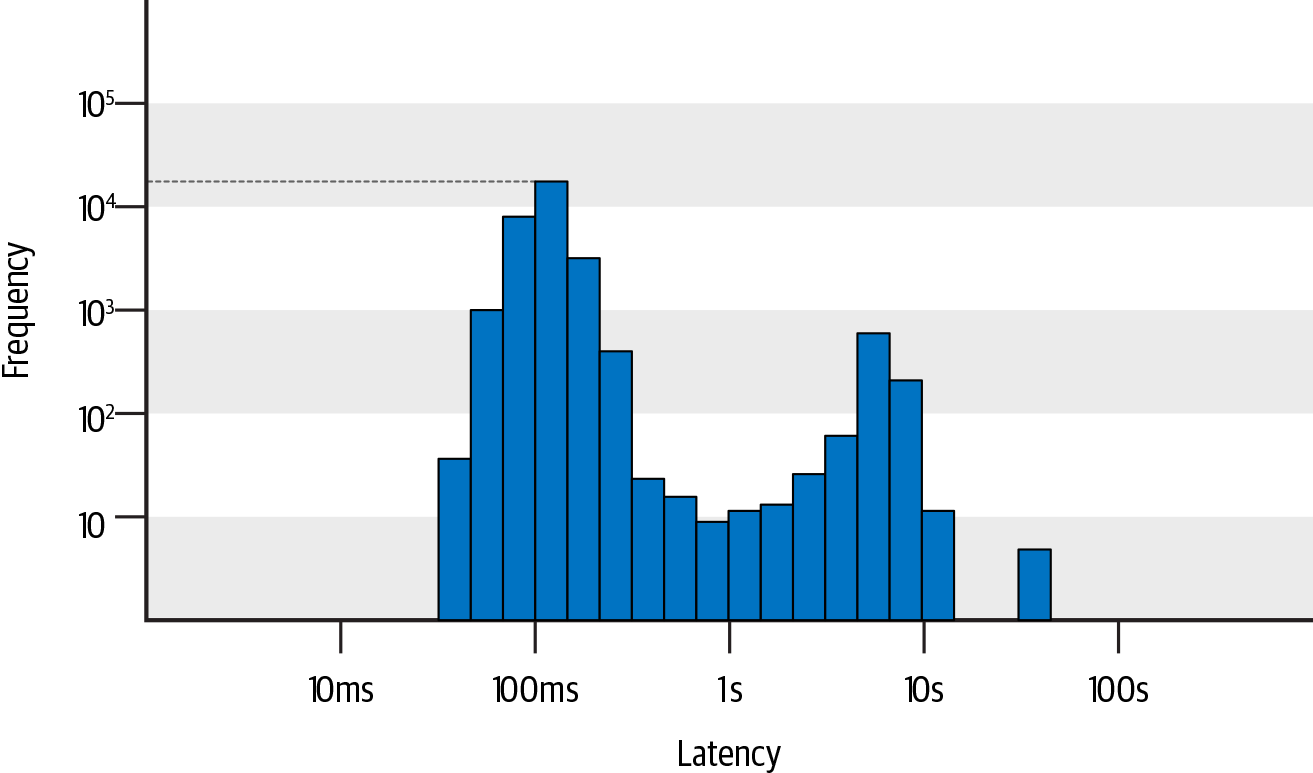
直方图可以与分位数结合使用,每一个耗时分位数都会落在直方图具体的某个区间内。这样,不仅能够快速发现最慢的 1%请求耗时阈值是3s,还能进一步区分这1%最慢的请求在3-5s,5-7s,7-10s,10s以上的具体分布数量。同样的P99 分位数(3s),慢请求全部集中在3-5s区间,和全部集中在10s以上区间所反映的问题严重程度,以及问题背后的原因可能是完全不同的。
通过对比不同时段的直方图分布,可以精准发现每一个耗时区间的变化情况。如果业务是面向终端用户,每一个长尾请求都代表着一次糟糕的用户体验,那应该重点关注耗时区间最高的那部分变化,比如P99分位数所在的区间;如果该业务系统是负责图形图像处理,更加看重单位时间内的吞吐率,不那么在意长尾耗时,那应该优先关注大部分请求的耗时变化,比如P90或P50所在区间的分布变化。
缓存命中率
缓存可以有效提升高频重复请求的响应速度,比如订单中心可以将商品详情记录在Redis缓存中,只有查询缓存未命中时才去请求数据库。因此,在实际生产环境中,缓存命中率可以作为度量系统性能的一个重要指标。
举个例子,某订单中心每次促销活动刚开始的时候会出现访问量激增又下降再缓慢回升,伴随耗时大幅抖动的现象,而缓存和数据库的请求量也会相对应的抖动变化,如下图所示。

我们可以看到缓存请求量的变化是与创建订单接口大致相同的,而数据库的请求量有一个比较大幅的增长。可以初步判断是由于促销活动初期出现了大量缓存未命中,从而调用数据库导致的创建订单接口耗时异常,因为查询数据库的耗时开销要远大于缓存。缓存未命中的原因主要有两种,一种是查询了大量冷数据导致的缓存命中率下降,另一种是查询量激增导致缓存连接被打满,超过其服务提供能力。两种原因的具体表现可以结合缓存命中率指标进一步区分,如下图所示。
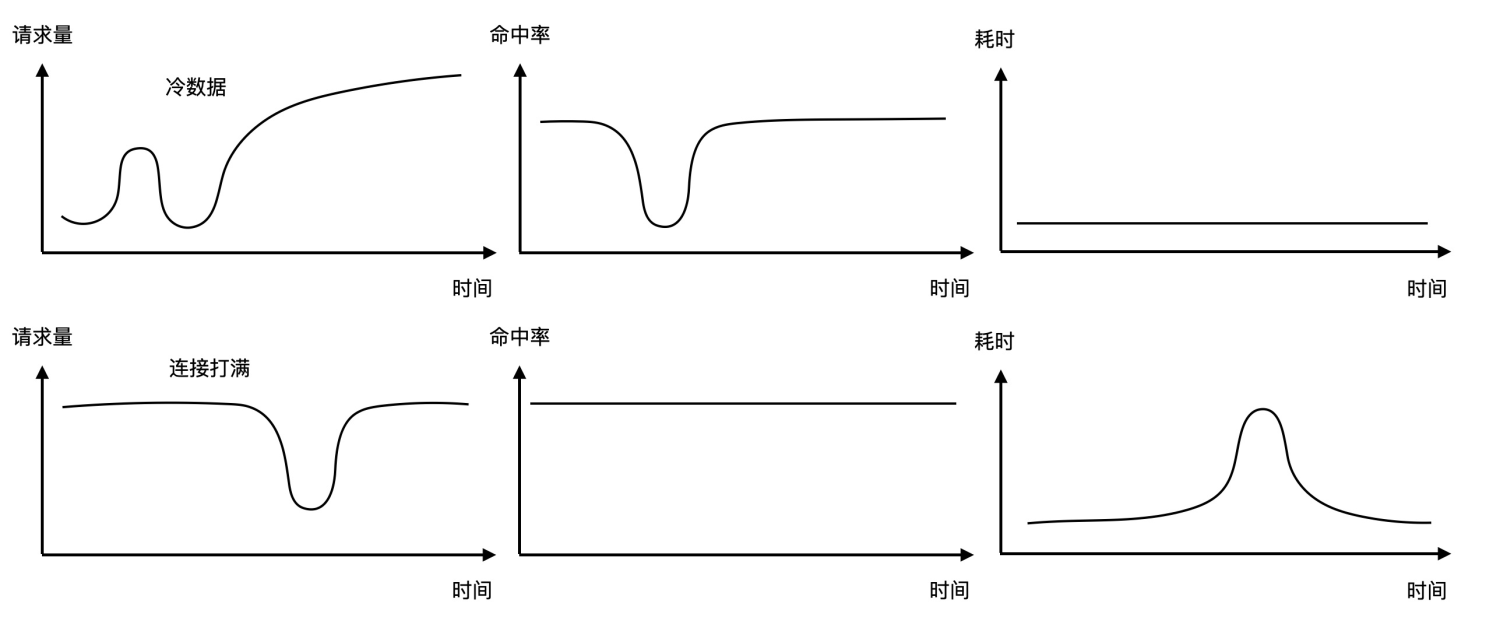
为了减少冷数据对促销活动体验的影响,可以提前进行缓存预热提高命中率;而连接打满的问题可以提前调整客户端或服务端的缓存连接池最大连接数限制,或者提前扩容。缓存命中率下降的严重后果会导致大量请求击穿数据库,最终导致整体服务不可用。因此,在生产环境中建议对缓存命中率设置告警,提前发现风险。
CPU 使用率和平均负载
CPU 使用率
CPU使用率就是CPU非空闲态运行的时间占比,它反映了CPU的繁忙程度。比如,单核CPU 1s内非空闲态运行时间为0.8s,那么它的CPU使用率就是80%;双核CPU 1s内非空闲态运行时间分别为0.4s和0.6s,那么,总体CPU使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%,其中2表示CPU核数,多核CPU同理。
在Linux系统下,使用top命令查看CPU使用情况,可以得到如下信息:
Cpu(s): 0.2%us, 0.1%sy, 0.0%ni, 77.5%id, 2.1%wa, 0.0%hi, 0.0%si, 20.0%st- us(user):表示CPU在用户态运行的时间百分比,通常用户态CPU高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。
- sy(sys):表示CPU在内核态运行的时间百分比(不包括中断),通常内核态CPU越低越好,否则表示系统存在某些瓶颈。
- ni(nice):表示用nice修正进程优先级的用户态进程执行的CPU时间。nice是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计CPU开销。
- id(idle):表示CPU处于空闲态的时间占比,此时,CPU会执行一个特定的虚拟进程,名为System Idle Process。
- wa(iowait):表示CPU在等待I/O操作完成所花费的时间,通常该指标越低越好,否则表示I/O存在瓶颈,可以用 iostat等命令做进一步分析。
- hi(hardirq):表示CPU处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。
- si(softirq):表示CPU处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。
- st(steal):表示CPU被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。
由于CPU有多种非空闲态,因此,CPU使用率计算公式可以总结为:CPU使用率 = (1 – 空闲态运行时间/总运行时间)* 100%。
根据经验法则, 生产系统的CPU总使用率建议不要超过70%。
平均负载
平均负载(Load Average)是指单位时间内,系统处于可运行状态(Running / Runnable)和不可中断态的平均进程数,也就是平均活跃进程数。
可运行态进程包括正在使用CPU或者等待CPU的进程;不可中断态进程是指处于内核态关键流程中的进程,并且该流程不可被打断。比如当进程向磁盘写数据时,如果被打断,就可能出现磁盘数据与进程数据不一致。不可中断态,本质上是系统对进程和硬件设备的一种保护机制。
在Linux系统下,使用top命令查看平均负载,可以得到如下信息:
load average: 1.09, 1.12, 1.52这3个数字分别表示1分钟、5分钟、15分钟内系统的平均负载。该值越小,表示系统工作量越少,负荷越低;反之负荷越高。
理想情况下,每个CPU应该满负荷工作,并且没有等待进程,此时,平均负载 = CPU逻辑核数。
但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 = 0.7 * CPU逻辑核数。
- 当平均负载持续大于 0.7 * CPU 逻辑核数,就需要开始调查原因,防止系统恶化;
- 当平均负载持续大于 1.0 * CPU 逻辑核数,必须寻找解决办法,降低平均负载;
- 当平均负载持续大于 5.0 * CPU 逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。
除了关注平均负载值本身,也应关注平均负载的变化趋势,这包含两层含义。一是 load1、load5、load15 之间的变化趋势;二是历史的变化趋势。
- 当 load1、load5、load15 三个值非常接近,表明短期内系统负载比较平稳。此时,应该将其与昨天或上周同时段的历史负载进行比对,观察是否有显著上升。
- 当 load1 远小于 load5 或 load15 时,表明系统最近 1 分钟的负载在降低,而过去 5 分钟或 15 分钟的平均负载却很高。
- 当 load1 远大于 load5 或 load15 时,表明系统负载在急剧升高,如果不是临时性抖动,而是持续升高,特别是当 load5 都已超过 0.7 * CPU 逻辑核数时,应调查原因,降低系统负载。
CPU 使用率与平均负载的关系
CPU 使用率是单位时间内 CPU 繁忙程度的统计。而平均负载不仅包括正在使用 CPU 的进程,还包括等待 CPU 或 I/O 的进程。因此,两者不能等同,有两种常见的场景如下所述:
原文地址:https://blog.csdn.net/csd11311/article/details/134768187
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_34868.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!