map是一种几乎每一门编程语言都有的数据结构,他是一组key–value组成的数据结构。Go语言的map和python中的dict的作用类似,它是一种数据结构用来维护一个集合的数据,并且可以对这个集合进行增删查改的操作。Go语言的map采用的数据结构:
哈希表(hash table)。在很多场景下哈希表性能很高,哈希查找表最坏的时间复杂度是O(n),平均查找效率是O(1),如果哈希函数设置得合理最坏得情况不会出现。
1.map的底层数据结构及查询机制
1.1 底层结果
map的底层是一个hmap结构体,该结构体包含的字段如下图所示:
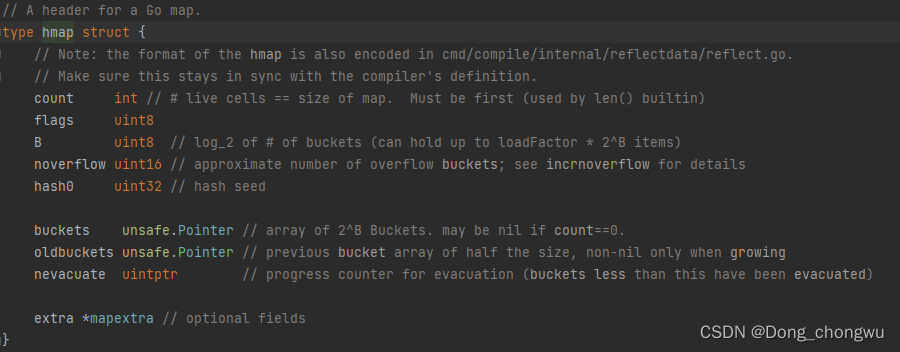
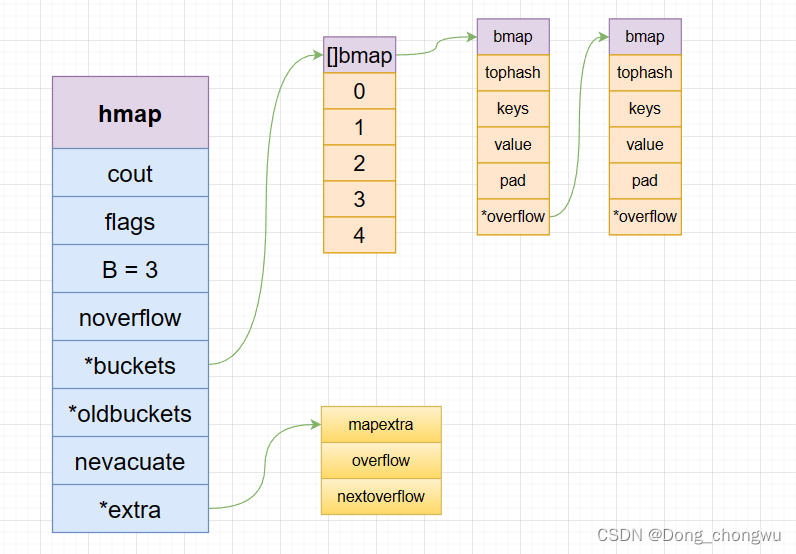
该结构体中一些关键的字段为,count为现在map中装入的键值对数量,buckets是一个指向桶数组的指针,B表示桶的数量的对数,例如B=3,则普通桶的数量则有8个,但是在对map进行初始化的时候会设几个溢出桶。
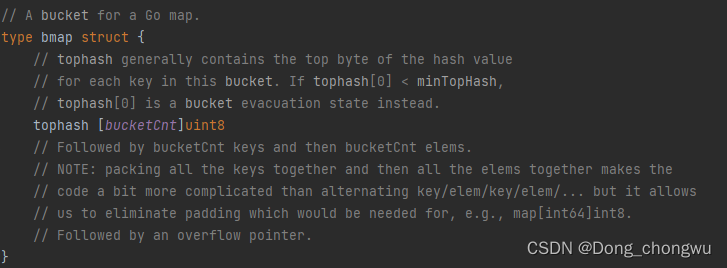
每个桶是一个bamp结构体。 bamap中含有hash值的高8位(tophash),含有key和value的数组,还有一个overflow指针,指向的是溢出桶。每个桶中可以存储8个k–v的数据,如果桶装满了,则超出的数据装入溢出桶中。
key和value分开存储的原因,主要是出于内存对齐的考虑,分开存储可以节省内存空间。
例如:map[int64]int8,这样的map如果采用的是key/value/key/value这样的结构存储的话,则每对key/value后面都要额外的填充7个字节,为了进行内存对齐,这样无疑是对内存空间的巨大浪费。如果采用的是key和value分开存储的话,则不用考虑内存对齐的问题。
1.2map的创建和key的删除
注意,这样方式创建的map是nil,如果往这个map中添加元素会panic
1.3 map底层如何定位到某个key值
1.4遍历的无序性
2.Go语言解决哈希碰撞的方法
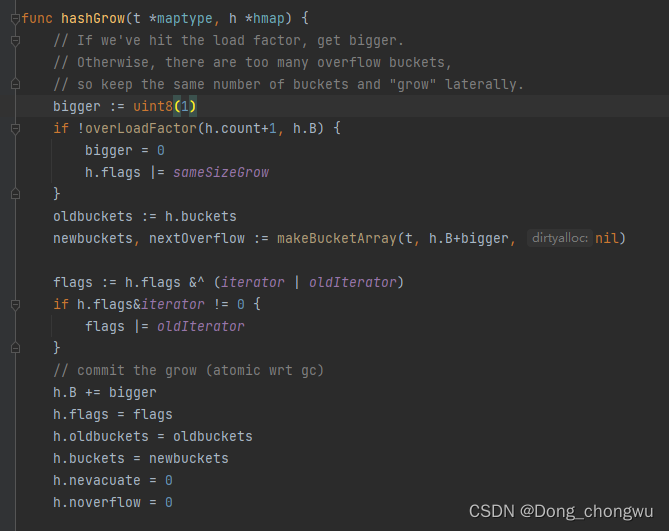
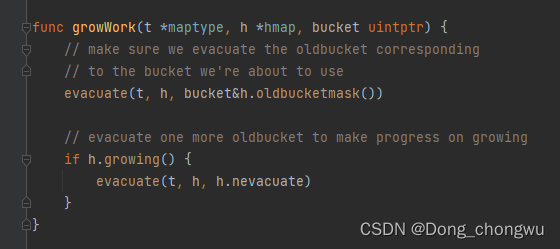
3.map的扩容机制
3.1. map跨容的条件
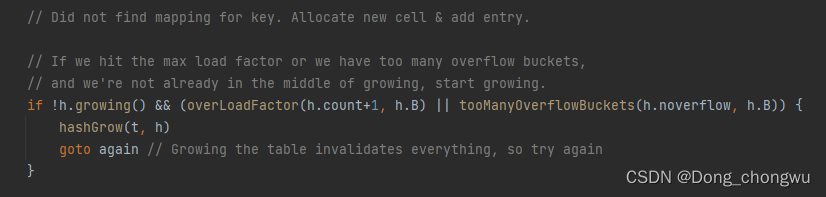
3.2. map的扩容方式:
3.3 map的扩容机制:
4.Go语言的map是线程安全的嘛?
5.如何比较两个map是否相等
6.为什么map数据结构的查询效率高
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。