基础架构设计原则
文章目录
一、可用性(Availability)
系统应该保持高可用性,以确保用户能够始终访问和使用系统。这可以通过设计冗余和容错机制来实现,如负载均衡、故障转移、备份和恢复策略等。
1.1、引入冗余
通过冗余架构设计,如使用多个服务器节点、多个数据中心或云区域,确保系统在一个节点或区域故障时仍然可用。
-
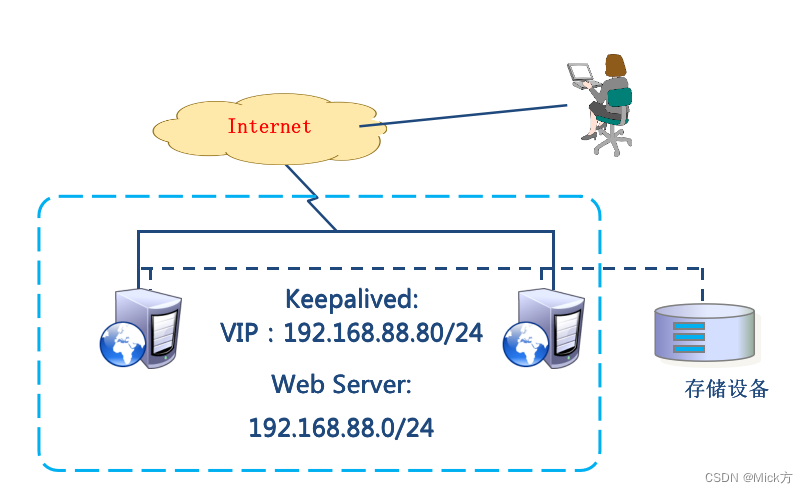
服务器冗余:通过在系统中引入多台服务器,将负载分散到多个服务器上,以提高系统的可用性。常见的服务器冗余方法包括主备(Active-Standby)模式和负载均衡。在主备模式中,一台服务器作为主服务器处理请求,而其他服务器作为备份服务器,当主服务器发生故障时,备份服务器可以接管服务。负载均衡则通过分发请求到多个服务器来平衡负载,当某台服务器发生故障时,其他服务器可以接管请求。
-
数据库冗余:使用数据库冗余来提高数据的可用性和容错能力。数据库冗余可以通过数据库复制(replication)来实现,即将数据复制到多个数据库实例中。这样,当一个数据库实例发生故障时,其他实例仍可以提供服务。常见的数据库复制方法包括主从复制和多主复制。
-
磁盘冗余:使用磁盘冗余来提高数据的可靠性和容错能力。常见的磁盘冗余技术包括磁盘阵列(RAID)和磁盘镜像。RAID技术将多个磁盘组合成一个逻辑卷,通过数据分布和冗余校验等技术提供数据的冗余和容错能力。磁盘镜像则是将数据同时写入两个磁盘,以保证数据的备份和可用性。
-
网络冗余:通过引入冗余的网络设备和网络路径来提高网络的可用性。常见的网络冗余技术包括冗余网络设备(如交换机和路由器)和冗余网络连接(如多个网络链路和多个ISP供应商)。
除了以上冗余的条件,还可以考虑数据库、地区等方面的冗余,提高服务的可用性,本质上是以时间换空间的策略。
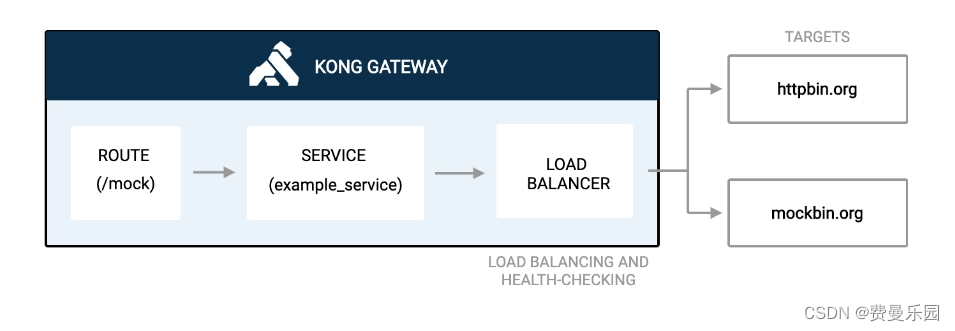
1.2、负载均衡
将流量分布到多个服务器上,以平衡负载,提高系统的性能和容量。
负载均衡场景:
- 硬件负载均衡器(Hardware Load Balancer):这是一种专用的物理设备,通常是一台独立的硬件设备,用于分发和平衡网络流量。硬件负载均衡器具有高性能和可靠性,并能处理大量的请求流量。
- 软件负载均衡器(Software Load Balancer):这是在服务器端运行的软件,用于分发和平衡网络流量。软件负载均衡器可以部署在物理服务器、虚拟机或容器中。常见的软件负载均衡器包括Nginx、HAProxy和Apache HTTP Server的负载均衡模块等。
- DNS负载均衡(DNS Load Balancing):通过在DNS服务器中配置多个IP地址,将域名解析请求分发到不同的服务器上,实现负载均衡。DNS负载均衡可以根据不同的策略(如轮询、加权轮询、最少连接数等)选择合适的服务器。
- 防火墙负载均衡(Firewall Load Balancing):防火墙负载均衡是通过在防火墙中配置多个服务器的IP地址和端口,将流量分发到不同的服务器上。这种负载均衡通常用于应对大规模的网络流量和DDoS攻击。
- 内容分发网络(Content Delivery Network, CDN):CDN是一种分布式网络架构,通过将内容缓存到全球各地的边缘节点,将内容从最近的节点提供给用户,以提高内容的可用性和传输效率。CDN能够分发静态内容、动态内容和流媒体等。
负载均衡常用框架:
- Nginx:Nginx是一个高性能的开源Web服务器和反向代理服务器,具有负载均衡功能。它可以通过配置反向代理和负载均衡模块来实现请求的分发和负载均衡。
- HAProxy:HAProxy是一种高性能的开源负载均衡器和代理服务器。它支持多种负载均衡算法,并提供TCP和HTTP的负载均衡功能。
- Apache HTTP Server:Apache HTTP Server是广泛使用的开源Web服务器,它具有负载均衡模块(如mod_proxy_balancer)用于分发请求和实现负载均衡。
- Spring Cloud Gateway:Spring Cloud Gateway是一个基于Spring Framework构建的开源API网关,它提供了负载均衡的功能。它可以与Spring Cloud中的服务注册与发现组件(如Eureka、Consul)集成,实现服务的动态路由和负载均衡。
- Netflix Ribbon:Netflix Ribbon是一个客户端负载均衡库,它可以与Spring Cloud等框架集成,提供在服务间进行负载均衡的能力。
- Envoy:Envoy是一个开源的边缘和服务代理,具有负载均衡、服务发现和流量管理等功能。它被广泛应用于容器、微服务和云原生架构中。
- Kubernetes:Kubernetes是一个流行的容器编排和管理平台,它提供负载均衡的功能。Kubernetes可以通过Ingress资源和Service资源来实现负载均衡和流量管理。
常用框架选型:
- 性能需求:根据负载的规模和性能要求,选择具有足够性能的负载均衡器。
- 功能需求:确定所需的功能,如负载均衡算法、健康检查、故障转移、SSL终止等。
- 可扩展性:考虑负载均衡器的可扩展性,以满足未来的增长需求。
- 集成和兼容性:确保所选框架与现有技术栈和环境的集成和兼容性。
- 社区支持和文档:评估框架的社区活跃度和文档资源,以便获取支持和解决问题。
-
选型建议:Nginx适用于需要高性能和灵活配置的场景,特别是作为反向代理和负载均衡器。它在Web服务器和应用服务器之间分发请求效果良好。
-
HAProxy:
-
选型建议:Apache HTTP Server适合于传统的Web服务器场景,但在高并发和大规模负载的情况下,可能需要额外的负载均衡器。
-
选型建议:如果您正在构建基于Spring Boot和Spring Cloud的微服务架构,Spring Cloud Gateway是一个良好的选择,可与服务注册与发现组件集成实现负载均衡。
-
选型建议:如果您正在使用Spring Cloud框架构建微服务应用,并且需要在客户端实现负载均衡,Netflix Ribbon是一个不错的选择。
1.3、故障转移
通过使用故障转移技术,如热备份、冷备份或故障切换,将流量从故障节点转移到备用节点,以确保系统的连续性。
常用故障转移的策略:
- 负载均衡器故障转移:使用负载均衡器作为前端,将流量分发到多个后端服务器。如果一个后端服务器发生故障,负载均衡器可以自动将流量重定向到其他可用服务器上,确保服务的连续性。
- 服务健康检查:负载均衡器或其他监控组件可以定期对服务器进行健康检查,以检测故障和异常。如果服务器被标记为不可用,负载均衡器将停止将流量发送到该服务器,直到其恢复正常。
- 故障自动恢复:通过自动化脚本或监控系统,实现故障自动恢复。例如,当检测到服务器故障时,自动将其从负载均衡器中移除,并启动备用服务器来接管流量。
- 冗余备份:使用冗余备份的架构,将服务复制到多个独立的服务器上。如果一个服务器发生故障,其他备份服务器可以接管流量并提供服务。
- 数据复制和同步:对于具有数据存储的应用程序,使用数据复制和同步机制确保数据的冗余和一致性。常见的方法包括主从复制、多主复制和分布式数据库等。
- 快速故障检测和切换:通过实时监控和故障检测机制,快速发现和响应故障。一旦故障被检测到,系统可以自动或手动进行切换,将流量转移到备用服务器或其他可用节点上。
- 热备份和冷备份:热备份指备用服务器处于活动状态,并随时准备接管流量。冷备份指备用服务器处于闲置状态,只在主服务器故障时才启动并接管流量。
- 容器编排和自动扩展:使用容器编排平台(如Kubernetes)和自动扩展策略,根据负载情况自动调整容器实例数量,并确保足够的资源来处理流量和故障。
1.4、备份和恢复策略
定期备份数据,并建立有效的恢复策略,以便在数据丢失或系统故障时能够快速恢复。
- 完全备份(Full Backup):将整个系统或应用程序的数据和配置进行完全备份。当发生故障时,可以使用完全备份来还原系统到正常状态。完全备份通常比较耗时和占用存储空间。
- 增量备份(Incremental Backup):只备份自上次备份以来发生变化的数据。增量备份通常比完全备份快速且占用较少的存储空间。在恢复时,需要先还原最近的完全备份,然后逐个应用增量备份。
- 差异备份(Differential Backup):备份自上次完全备份以来发生变化的数据。差异备份相对于增量备份来说,恢复时只需要应用最近一次的差异备份和最近一次完全备份。
- 冷备份(Cold Backup):备份系统或应用程序时,将其停机或下线,然后进行备份操作。冷备份对系统性能和用户体验有较小的影响,但在备份期间,系统是不可用的。
- 热备份(Hot Backup):在系统运行时进行备份操作,而不需要停机或下线。热备份可以持续提供服务,并减少对用户的影响,但可能会对系统性能产生一定的负载。
- 备份到远程位置:将备份数据存储在远程位置,以提供更高的可靠性和容灾能力。远程备份可以防止本地故障(如硬件故障、天灾等)导致数据丢失。
- 容灾备份(Disaster Recovery Backup):在备份过程中考虑整个系统的容灾和恢复能力。这包括备份数据、配置文件、镜像/快照、事务日志等,以确保在系统发生重大故障时可以尽快恢复。
- 自动化备份和恢复:使用自动化工具和脚本定期执行备份操作,并实施自动化的恢复流程。这可以减少人为错误和提高备份和恢复的效率。
# 数据库备份脚本
# 执行脚本(每天两点自动备份)
0 2 * * * /path/to/database_backup.sh
#脚本
#!/bin/bash
# 数据库配置
DB_HOST="localhost"
DB_USER="username"
DB_PASSWORD="password"
DB_NAME="database_name"
# 备份目录
BACKUP_DIR="/path/to/backup/directory"
# 备份文件名(带有日期和时间戳)
BACKUP_FILENAME="${DB_NAME}_$(date +'%Y%m%d_%H%M%S').sql"
# 执行备份命令
mysqldump -h $DB_HOST -u $DB_USER -p$DB_PASSWORD $DB_NAME > $BACKUP_DIR/$BACKUP_FILENAME
# 检查备份是否成功
if [ $? -eq 0 ]; then
echo "数据库备份成功: $BACKUP_DIR/$BACKUP_FILENAME"
else
echo "数据库备份失败"
fi
二、可扩展性(Scalability)
可扩展性是指系统能够有效地处理增加的负载和流量,而不影响性能和用户体验。
2.1 水平扩展
通过添加更多的服务器节点来增加系统的处理能力,以平衡负载和提高性能。
2.2 垂直扩展
通过增加单个节点的资源能力,如CPU、内存或存储容量,来增加系统的处理能力。
2.3 弹性扩展
利用云计算平台的弹性能力,根据负载需求自动调整资源的规模,以满足变化的需求。
- 自动化扩展:
- 负载均衡:
- 微服务架构:
- 容器化和容器编排:
- 数据库水平分片:
- 缓存策略:
- 多地域和多数据中心部署:
- 容错设计:
- 采用容错设计,使系统在组件或节点故障时仍能正常运行。
- 使用冗余组件、自动故障转移和备份系统来提高系统的可用性。
- 监控和自愈:
- 灰度发布和蓝绿部署:
三、可靠性(Reliability)
3.1 容错机制
采用冗余设计和容错技术,如使用主备模式、复制和故障切换,以确保系统在部分故障情况下仍然可用。
-
冗余备份:
备份 MySQL 脚本
#!/bin/bash # MySQL数据库连接信息 DB_USER="your_username" DB_PASSWORD="your_password" DB_NAME="your_database_name" # 备份文件路径 BACKUP_DIR="/path/to/backup" # 备份文件名(以当前日期和时间命名) BACKUP_FILE="$BACKUP_DIR/db_backup_$(date +%Y%m%d_%H%M%S).sql" # 使用 mysqldump 命令备份数据库 mysqldump -u $DB_USER -p$DB_PASSWORD $DB_NAME > $BACKUP_FILE # 打印备份完成信息 echo "Backup completed successfully. Backup file: $BACKUP_FILE"备份 Docker 脚本
#!/bin/bash # 容器名称或ID CONTAINER_NAME_OR_ID="your_container_name_or_id" # 备份目录 BACKUP_DIR="/path/to/backup" # 备份文件名(以当前日期和时间命名) BACKUP_FILE="$BACKUP_DIR/container_backup_$(date +%Y%m%d_%H%M%S).tar.gz" # 备份容器状态和数据卷 docker export $CONTAINER_NAME_OR_ID | gzip > $BACKUP_FILE docker container stop $CONTAINER_NAME_OR_ID # 打印备份完成信息 echo "Container backup completed successfully. Backup file: $BACKUP_FILE"在上面的脚本中,替换
your_container_name_or_id为实际的容器名称或ID,将备份文件保存在指定的目录中。该脚本使用docker export命令导出容器状态,然后使用docker container stop命令停止容器。# 还原容器 zcat $BACKUP_FILE | docker import - your_image_name # 创建并运行容器 docker run -d --name restored_container your_image_name请注意,这个备份脚本只备份了容器的状态和数据卷,并没有包括Docker镜像。如果需要备份镜像,可以使用
docker save命令,将镜像导出为tar文件,例如:docker save -o image_backup.tar your_image_namedocker load -i image_backup.tar -
自动故障转移:
自动故障转移的实现通常涉及监测系统组件的健康状态,当检测到故障时自动触发流量切换到备用系统。下面是一个简单的示例,演示如何使用 Shell 脚本和 Cron 任务实现自动故障转移。
假设场景: 假设有两台服务器,一台是主服务器,一台是备用服务器。我们希望在主服务器故障时自动将流量切换到备用服务器。
-
#!/bin/bash # 主服务器的IP地址或主机名 MAIN_SERVER="main_server_ip_or_hostname" # 备用服务器的IP地址或主机名 BACKUP_SERVER="backup_server_ip_or_hostname" # 检测主服务器是否存活 if ping -c 1 $MAIN_SERVER &> /dev/null; then echo "Main server is healthy." else echo "Main server is down. Triggering failover." # 在这里可以添加其他故障转移逻辑,例如更新负载均衡器配置、DNS切换等 # 以下示例通过修改本地 /etc/hosts 文件实现简单的故障转移 echo "$BACKUP_SERVER main_server_ip_or_hostname" | sudo tee -a /etc/hosts echo "Failover complete." fi -
# 编辑Cron任务,定期执行故障检测脚本 crontab -e* * * * * /path/to/health_check.sh
-
-
负载均衡:
负载均衡是一种将网络或应用程序流量分发到多个服务器或资源的技术,以确保这些服务器能够共同处理请求,提高系统的性能、可用性和可伸缩性。不同的负载均衡策略适用于不同的场景。以下是一些常见的负载均衡策略:
这些策略可以单独使用,也可以结合使用,以满足特定系统的需求。选择适当的负载均衡策略通常取决于系统的特性、性能要求以及预期的用户体验。在实际应用中,可能会根据实际情况动态调整负载均衡策略。
-
**事务回滚和重试是处理系统中发生错误或异常的两种常见策略。**它们分别用于确保系统在遇到问题时能够恢复到一致的状态,或者尝试重新执行某个操作。以下是事务回滚和重试的一些常见策略:
事务回滚策略:
-
数据库事务回滚:
-
应用级事务回滚:
重试策略:
这些策略可以根据具体的系统需求和场景进行组合使用。在设计时,需要考虑到操作的性质、可重试性、系统的稳定性,以及对于一致性和可用性的权衡。
-
-
微服务架构:
常见的微服务架构:
-
幂等性设计:
3.2 错误处理和恢复策略
实施有效的错误处理机制,包括错误检测、错误报告、错误日志记录和错误恢复策略,以减少系统故障对用户的影响。
MySQL 备份与恢复
MySQL备份的恢复通常涉及将备份文件还原到MySQL服务器,并确保数据库引擎正常处理备份的数据。下面是一般的MySQL备份恢复步骤:
备份数据:
-
使用 mysqldump 进行备份:
mysqldump -u [username] -p[password] [database_name] > backup.sql -
使用 MySQL 命令行工具进行备份:
mysql -u [username] -p[password] [database_name] > backup.sql
恢复数据:
-
使用 mysqldump 进行恢复:
mysql -u [username] -p[password] [database_name] < backup.sql -
使用 MySQL 命令行工具进行恢复:
mysql -u [username] -p[password] [database_name] < backup.sql -
使用物理备份工具进行恢复:
注意事项:
-
在进行恢复之前,请确保已经创建了要恢复到的数据库。可以使用以下命令创建数据库:
mysql -u [username] -p[password] -e "CREATE DATABASE [database_name];"
请注意,MySQL的版本和配置可能会影响备份和恢复的确切步骤,因此建议查阅相应版本的MySQL文档以获取详细信息。
3.3 监控和自动化运维
建立监控系统来实时监测系统的状态和性能,并采取自动化运维措施,如自动报警、自动扩展和自动修复,以提高故障检测和响应的效率。
监控策略和方法:
自动化运维策略和方法:
-
自动化部署:
-
持续集成/持续交付(CI/CD):
-
自动化配置管理:
-
自动化扩展:
- 利用云服务提供商的自动扩展功能,根据负载的变化自动调整系统规模,确保性能和可用性。
-
自动化备份和恢复:
- 定期自动备份系统数据,并建立自动化的恢复机制,以应对意外故障和数据丢失。
-
自动化监控告警响应:
-
自动化任务调度:
-
自动化测试:
-
自动化容器编排:
这些监控和自动化运维的策略和方法有助于降低系统维护成本、提高运维效率,并提供更高的系统可靠性和可用性。
四、 安全性(Security)
安全性是指系统能够保护数据和资源免受未经授权的访问、恶意攻击和数据泄露等威胁。
4.1 身份验证和授权
实施强大的身份验证和授权机制,确保只有经过身份验证且授权的用户能够访问系统的敏感资源。
4.2 加密和数据保护
使用加密算法对敏感数据进行加密,保护数据的机密性和完整性。同时,采取数据备份和灾难恢复措施,以保护数据免受丢失或损坏的风险。
4.3 安全审计和监控
建立安全审计机制,记录用户的操作、系统事件和安全事件,以便进行安全审计和监控。此外,采用实时监控系统来检测潜在的安全漏洞和异常活动,并及时采取措施进行响应和应对。
身份验证框架:
授权框架:
五、可维护性(Maintainability)
可维护性是指系统易于维护和管理,以降低变更和修复的成本。以下是提高系统可维护性的一些实践:
5.1 模块化设计
将系统划分为模块化的组件,使每个组件都具有清晰的职责和接口,便于理解、修改和测试。
模块化设计是一种软件设计方法,将系统划分为相互独立、可重用的模块,以提高代码的可维护性、可扩展性和可重用性。以下是模块化设计的主要思想、策略和实现方式:
主要思想:
策略和实现方式:
5.2 清晰的代码结构
采用良好的编码规范和设计模式,使代码结构清晰易读,降低代码的复杂性和耦合度。
5.3 文档化
编写清晰、详细的文档,包括系统架构、设计原理、接口说明和操作手册,以便开发人员和运维人员理解和管理系统。
5.4 自动化测试和部署
建立自动化测试框架,包括单元测试、集成测试和端到端测试,以确保系统的正确性和稳定性。同时,采用自动化部署工具,简化部署过程,提高发布的效率和一致性。
自动化测试和部署是现代软件开发中关键的实践,它们有助于提高软件质量、加速交付过程并降低错误率。以下是一些常见的自动化测试和部署方法、框架以及它们的优缺点:
自动化测试方法和框架:
1. 单元测试:
-
框架:
-
优缺点:
2. 集成测试:
3. 端到端测试(E2E):
-
框架:
-
优缺点:
4. 性能测试:
-
方法: 评估应用程序在不同负载下的性能和稳定性。
-
框架:
-
优缺点:
自动化部署方法和框架:
1. 脚本化部署:
-
方法: 使用脚本(Shell、PowerShell等)定义应用程序的部署过程。
-
框架:
- Bash 脚本
- PowerShell 脚本
-
优缺点:
- 优点: 灵活性高,适用于各种环境。
- 缺点: 可读性较差,维护成本较高。
2. 配置管理工具:
-
框架:
-
优缺点:
3. 容器化部署:
4. 持续集成/持续交付(CI/CD):
-
框架:
-
优缺点:
- 优点: 提供快速反馈,支持自动化测试和部署。
- 缺点: 配置复杂,需要谨慎管理构建流水线。
六、性能(Performance)
性能是指系统的响应时间和吞吐量,以满足用户的需求。以下是一些提高系统性能的关键策略:
6.1 性能调优
通过对系统进行性能分析和优化,找出性能瓶颈并进行相应的调整,以提高系统的响应时间和吞吐量。
性能调优是为了优化软件系统的性能,提高其运行效率和响应速度。在进行性能调优时,需要注意一些关键点,并采取相应的措施。以下是一些常见的性能调优方面和相应的优化方法:
1. 代码优化:
2. 数据库优化:
3. 缓存优化:
4. 网络优化:
5. 并发和多线程优化:
6. 硬件资源优化:
7. 监控和性能测试:
8. 日志记录和分析:
9. 页面加载优化:
6.2 缓存策略
利用缓存技术,将频繁访问的数据缓存起来,减少对后端资源的访问,提高系统的响应速度。
缓存策略是在应用程序中使用缓存时采取的一系列规则和方法,以决定何时更新、何时过期、何时存储新数据等。选择适当的缓存策略对于提高系统性能和用户体验至关重要。以下是一些常见的缓存策略:
1. 时间失效策略(Time-Based Expiration):
2. LRU(Least Recently Used):
3. LFU(Least Frequently Used):
-
思想:
-
优点:
- 考虑了数据的访问频率,适用于某些特定场景。
- 对于长时间内访问模式相对稳定的场景较为合适。
-
缺点:
4. Write-Through 和 Write-Behind:
-
思想:
-
优点:
-
缺点:
5. 无效策略(Cache-Aside):
-
思想:
-
优点:
- 灵活,适用于各种场景。
- 可以根据实际需求选择合适的缓存更新时机。
-
缺点:
- 需要手动管理缓存,容易出现不一致。
- 缓存与存储一致性的维护需要谨慎操作。
6. 自适应缓存策略:
-
思想:
- 根据实际使用情况,自动调整缓存策略,如根据数据的访问模式、数据的时效性等。
-
优点:
-
缺点:
- 实现相对较复杂。
- 需要维护一定的策略配置和监控机制。
6.3 异步处理
将一些耗时的操作设计为异步任务,以避免阻塞主线程或请求处理流程,提高系统的并发能力和响应性能。
6.4 负载均衡
通过负载均衡技术,将流量分发到多个服务器上,以平衡负载,提高系统的吞吐量和容量。
常见的有 Ng,在前面已经讲过。
七、可管理性(Manageability)
可管理性是指系统易于管理和监控,以便及时发现和解决问题。
7.1 日志和监控系统
建立强大的日志和监控系统,记录系统的运行状态、性能指标和异常事件,以便及时发现问题并进行分析和修复。
7.2 自动化运维和部署
采用自动化工具和脚本,简化运维任务和部署过程,减少人工操作的错误和时间成本。
7.3 可视化管理界面
设计直观和易用的管理界面,使管理员能够方便地监控系统状态、配置参数和执行管理操作。
八、可伸缩性(Elasticity)
可伸缩性是指系统能够根据负载需求的变化自动调整资源的规模。
8.1 云计算和弹性扩展
利用云计算平台提供的弹性扩展能力,根据负载需求自动调整资源的规模,以满足变化的需求,避免资源浪费和性能瓶颈。
8.2 容器化
采用容器化技术,如Docker。
8.3 容器编排
使用容器编排工具,如Kubernetes,对容器进行自动化部署、管理和伸缩,以实现高度可伸缩的系统架构。
8.4 弹性存储
采用可伸缩的存储解决方案,如对象存储或分布式文件系统,以满足不断增长的数据存储需求。
8.5 自动化监测和扩展
建立自动化监测系统,实时监测系统的负载和性能指标,并根据预设的阈值自动进行资源扩展,以保持系统的高可伸缩性。
原文地址:https://blog.csdn.net/weiyi_1/article/details/134613943
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_35410.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!