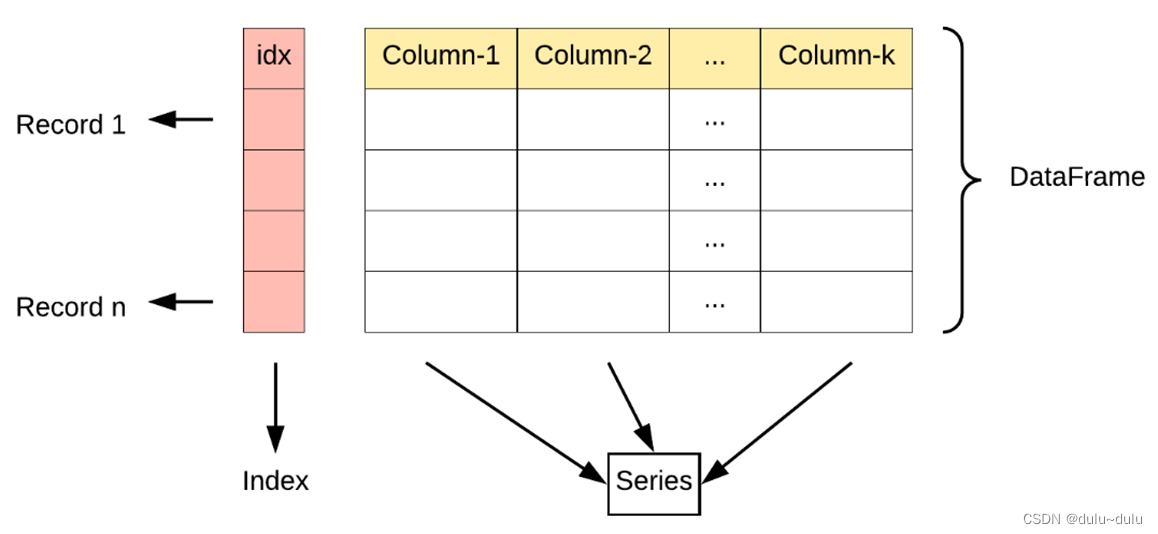
Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据)
Series属性
| 属性 | 描述 |
| pandas.Series(data,index,dtype,name,copy) | Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。 |
| data: 一组数据(ndarray 类型) | |
| index: 数据索引标签,如果不指定,默认从 0 开始。 | |
| dtype: 数据类型,默认会自己判断。 | |
| name: 设置名称。 | |
| copy: 拷贝数据,默认为 False。 |
示例1:
>>> import pandas as pd
>>> a = [1,2,3]
>>> sa = pd.Series(a)
>>> print(sa)
0 1
1 2
2 3
dtype: int64
>>> sa[1]
2
>>> a = ['Google','baidu','wiki']
>>> sa = pd.Series(a,index=['x','y','z'])
>>> print(sa)
x Google
y baidu
z wiki
dtype: object
示例2:
•float浮点型
•bool布尔型
>>> import numpy as np
>>> import pandas as pd
>>> s = pd.Series(np.random.randn(4),index=['a','b','c','d'])
>>> print(sa)
a -1.226694
b 0.157971
c 0.022525
d 2.606825
dtype: float64
>>> s[:2] #选取前两条数据
a -1.226694
b 0.157971
dtype: float64
>>> s[[1,3]] # 选取第2和第4条数据
b 0.157971
d 2.606825
dtype: float64
>>> s[s<s.mean()] #x小于平均值
a -1.226694
b 0.157971
c 0.022525
dtype: float64
>>> s['a'] #通过索引值选取元素
-1.2266936531191652
>>> s[['c','d']] # 多个索引值,注意括号
c 0.022525
d 2.606825
dtype: float64
>>> s = pd.Series(data=['1.2','1.5','2.7','2.3'])
>>> b = s.astype('float32') # 转换类型
>>> print(b)
0 1.2
1 1.5
2 2.7
3 2.3
dtype: float32
DataFrame的属性
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
示例:
# 使用列表创建
>>> import pandas as pd
>>> data = [['Google',10],['Baidu',12],['Wiki',13]] #二维列表
>>> df = pd.DataFrame(data, columns=['site','Age'])
>>> print(df)
site Age
0 Google 10
1 Baidu 12
2 Wiki 13
# 使用字典创建,其中字典的key为列名
>>> data = {'Site':['Google', 'Baidu','Wiki'],'Age':[10,12,13]}
>>> pf = pd.DataFrame(data)
>>> print(pd)
Site Age
0 Google 10
1 Baidu 12
2 Wiki 13
•Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[0]) # 返回第一行
calories 420
duration 50
Name: 0, dtype: int64
注意:返回结果其实就是一个 Pandas Series数据。
•可以返回多行数据,使用[[…]]格式,其中…为各行的索引,逗号隔开:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[[0,1]]) # 返回第一行和第二行
calories duration
0 420 50
1 380 40
注意:返回结果其实就是一个 Pandas DataFrame 数据。
# 查看指定列
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df['calories']) #一列访问
0 420
1 380
2 390
Name: calories, dtype: int64
>>> print(df[['calories','duration']]) # 多列访问
calories duration
0 420 50
1 380 40
2 390 45
# 查看指定行和列
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data)
>>> print(df.loc[0,'calories']) #第0行,calories数值
420
# 可以指定索引值index:
>>> data = {'calories':[420, 380, 390],'duration':[50,40,45]}
>>> df = pd.DataFrame(data, index=['day1','day2','day3'])
>>> print(df)
calories duration
day1 420 50
day2 380 40
day3 390 45
# 可以使用loc属性返回指定索引对应到的某一行
>>> print(df.loc['day1'])
calories 420
duration 50
Name: day1, dtype: int64
Pandas的CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
# to_string()用于返回DataFrame类型的数据,如果不使用该函数,则输出结果
# 为数据的前面5行和末尾5行,中间部分以...代替
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Baidu", "Taobao", "Wiki"]
st = ["www.google.com", "www.baidu.com", "www.taobao.com",
"www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
Pandas数据处理
•使用 head(n) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
输出:
Name Team Number ... Weight College Salary
0 Avery Bradley Boston Celtics 0.0 ... 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 ... 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 ... 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 ... 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 ... 231.0 NaN 5000000.0
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
输出:
Name Team Number ... Weight College Salary
0 Avery Bradley Boston Celtics 0.0 ... 180.0 Texas 7730337.0
1 Jae Crowder Boston Celtics 99.0 ... 235.0 Marquette 6796117.0
2 John Holland Boston Celtics 30.0 ... 205.0 Boston University NaN
3 R.J. Hunter Boston Celtics 28.0 ... 185.0 Georgia State 1148640.0
4 Jonas Jerebko Boston Celtics 8.0 ... 231.0 NaN 5000000.0
5 Amir Johnson Boston Celtics 90.0 ... 240.0 NaN 12000000.0
6 Jordan Mickey Boston Celtics 55.0 ... 235.0 LSU 1170960.0
7 Kelly Olynyk Boston Celtics 41.0 ... 238.0 Gonzaga 2165160.0
8 Terry Rozier Boston Celtics 12.0 ... 190.0 Louisville 1824360.0
9 Marcus Smart Boston Celtics 36.0 ... 220.0 Oklahoma State 3431040.0
•使用 tail(n) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
输出:
Name Team Number Position ... Height Weight College Salary
453 Shelvin Mack Utah Jazz 8.0 PG ... 6-3 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 PG ... 6-1 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 C ... 7-3 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 C ... 7-0 231.0 Kansas 947276.0
457 NaN NaN NaN NaN ... NaN NaN NaN NaN
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
输出:
Name Team Number ... Weight College Salary
448 Gordon Hayward Utah Jazz 20.0 ... 226.0 Butler 15409570.0
449 Rodney Hood Utah Jazz 5.0 ... 206.0 Duke 1348440.0
450 Joe Ingles Utah Jazz 2.0 ... 226.0 NaN 2050000.0
451 Chris Johnson Utah Jazz 23.0 ... 206.0 Dayton 981348.0
452 Trey Lyles Utah Jazz 41.0 ... 234.0 Kentucky 2239800.0
453 Shelvin Mack Utah Jazz 8.0 ... 203.0 Butler 2433333.0
454 Raul Neto Utah Jazz 25.0 ... 179.0 NaN 900000.0
455 Tibor Pleiss Utah Jazz 21.0 ... 256.0 NaN 2900000.0
456 Jeff Withey Utah Jazz 24.0 ... 231.0 Kansas 947276.0
457 NaN NaN NaN ... NaN NaN NaN
•info() 方法返回表格的一些基本信息(索引、数据类型和内存信息)
示例1:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 458 entries, 0 to 457 #行数,458,行,第一行编号为0
Data columns (total 9 columns): #列数,9列
# Column Non-Null Count Dtype #各列的数据类型
— —— ————– —–
0 Name 457 non–null object #non-null,意思是非空的数
3 Position 457 non-null object
7 College 373 non-null object #college的空值最多
memory usage: 32.3+ KB
示例2:
import pandas as pd
df = pd.read_csv('nba.csv')
a = df.sort_values(by='Weight') # 按Weight列数据升序排列
print(a.head().to_string())
输出:
Name Team Number Position Age Height Weight College Salary
152 Aaron Brooks Chicago Bulls 0.0 PG 31.0 6-0 161.0 Oregon 2250000.0
350 Briante Weber Miami Heat 12.0 PG 23.0 6-2 165.0 Virginia Commonwealth NaN
263 Bryce Cotton Memphis Grizzlies 8.0 PG 23.0 6-1 165.0 Providence 700902.0
359 Brandon Jennings Orlando Magic 55.0 PG 26.0 6-1 169.0 NaN 8344497.0
286 Tim Frazier New Orleans Pelicans 2.0 PG 25.0 6-1 170.0 Penn State 845059.0
print(a[a.Weight > 200].head().to_string()) # Weight列大于200的
输出:
Name Team Number Position Age Height Weight College Salary
47 Isaiah Canaan Philadelphia 76ers 0.0 PG 25.0 6-0 201.0 Murray State 947276.0
309 Kent Bazemore Atlanta Hawks 24.0 SF 26.0 6-5 201.0 Old Dominion 2000000.0
226 Rashad Vaughn Milwaukee Bucks 20.0 SG 19.0 6-6 202.0 UNLV 1733040.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
282 Bryce Dejean-Jones New Orleans Pelicans 31.0 SG 23.0 6-6 203.0 Iowa State 169883.0
示例3:
import pandas as pd
df = pd.read_csv('nba.csv')
df['one'] = 1 #增加一个固定值的列
print(df.head().to_string())
输出:
Name Team Number Position Age Height Weight College Salary one
0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0 1
1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0 1
2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN 1
3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0 1
4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0 1
print(a[a.Weight > 200].head().to_string()) # Weight列大于200的
输出:
Name Team Number Position Age Height Weight College Salary
47 Isaiah Canaan Philadelphia 76ers 0.0 PG 25.0 6-0 201.0 Murray State 947276.0
309 Kent Bazemore Atlanta Hawks 24.0 SF 26.0 6-5 201.0 Old Dominion 2000000.0
226 Rashad Vaughn Milwaukee Bucks 20.0 SG 19.0 6-6 202.0 UNLV 1733040.0
453 Shelvin Mack Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0
282 Bryce Dejean-Jones New Orleans Pelicans 31.0 SG 23.0 6-6 203.0 Iowa State 169883.0
•drop()方法:通过指定标签名称和响应的轴,或者直接指定索引或列名称,删除行或列
| 属性 | 描述 |
|
pandas.DataFrame.drop(labels=None, axis=0,index=None,columns=None, |
通过指定标签名称和相应的轴,或直接指定索引或列名称,删除行或列。 |
| labels 单个标签或者标签列表 | |
| axis=0 默认 删除index; axis=1 指定删除列 | |
| inplace=True 修改原数据 | |
| level 针对多重索引 指定级别 | |
| index 指定索引 | |
| columns 指定列名 |
示例:
>>>import pandas as pd
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
输出:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
#删除行
>>> df.drop(2)
a b c d
0 0 1 2 3
1 4 5 6 7
>>> df.drop([0,1])
a b c d
2 8 9 10 11
>>>import pandas as pd
>>> import numpy as np
>>> df = pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
输出:
# 删除列
>>> df.drop('a', axis=1)
b c d
0 1 2 3
1 5 6 7
2 9 10 11
>>> df.drop(['b','c'], axis=1)
a d
0 0 3
1 4 7
2 8 11
>>> df.drop(columns=['b','c']) # 同上
a d
0 0 3
1 4 7
2 8 11
原文地址:https://blog.csdn.net/weixin_69884785/article/details/134631520
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_35816.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!