库存模块缓存架构
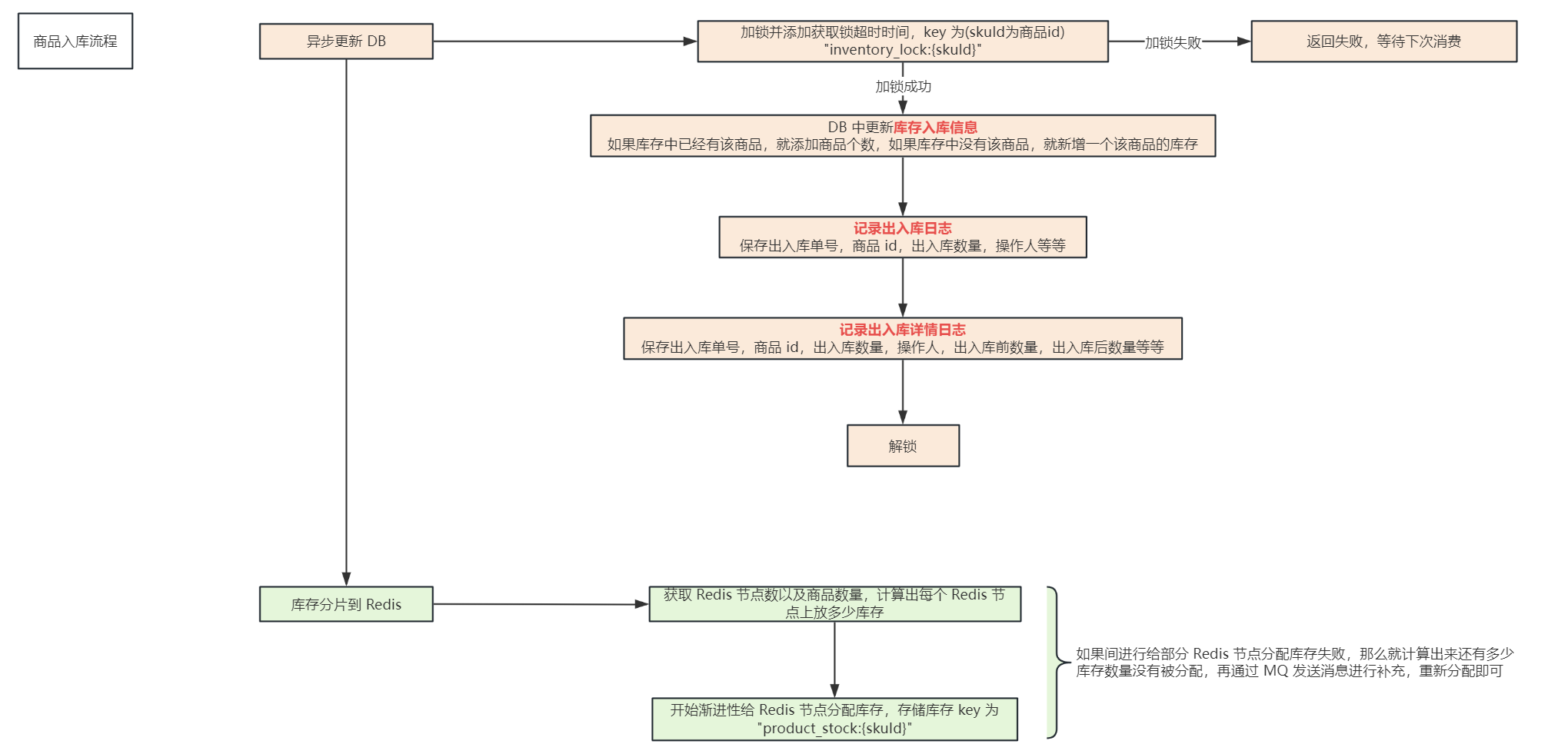
我们先来分析一下库存模块的业务场景,分为入库和出库,入库的话,在库存模块中需要添加库存,由于库存也是 写多读多 的场景,那么也是以 Redis 作为主存储,MySQL 作为辅助存储
出库的话,是在用户下单时,需要去库存中进行减库存的操作,并且用户退款时,需要增加库存
那么库存模块是存在高并发写的情况的,通过对商品库存进行分片存储,存储在多台 Redis 节点上,就可以将高并发的请求分散在各个 Redis 节点中,并且提供了单台 Redis 节点库存不足时的合并库存的功能
先来说一下如何对商品库存进行缓存分片,比如说有 100 个商品,Redis 集群有 5 个节点,先将 100 个商品拆分为 5个分片,再将 5 个分片分散到 Redis 集群的各个节点中,每个节点 1 个分片,那么也就是每个 Redis 节点存储 20 个商品库存
那么对于该商品的瞬间高并发的操作,会分散的打到多个 Redis 节点中,库存分片的数量一般和 Redis 的节点数差不多
这里分片库存的话,我们是在对商品进行入库的时候实现的,商品在入库的时候,先去 DB 中异步落库,然后再将库存分片写入各个 Redis 节点中,这里写入的时候采用渐进性写入,比如说新入库一个商品有 300 个,有 3 个 Redis 节点,那么我们分成 3 个分片的话,1 个 Redis 节点放 1 个分片,1 个分片存储 100 个商品,那么如果我们直接写入缓存,先写入第一个 Redis 节点 100 个库存,再写入第二个 Redis 节点 100 个库存,如果这时写入第三个 Redis 节点 100 个库存的时候失败了,那么就导致操作库存的请求压力全部在前两个 Redis 节点中,采用 渐进性写入 的话,流程为:我们已经直到每个 Redis 节点放 100 个库存了,那么我们定义一个轮次的变量,为 10,表示我们去将库存写入缓存中需要写入 10 轮,那么每轮就写入 10 个库存即可,这样写入 10 轮之后,每个 Redis 节点中也就有 100 个库存了,这样的好处在于,即使有部分库存写入失败的话,对于请求的压力也不会全部在其他节点上,因为写入失败的库存很小,很快时间就可以消耗完毕