slurm介绍就不再赘述了,这里看官网链接,其他的自己搜索吧。
Slurm Workload Manager – Quick Start User Guide
这里主要将slurm集群配置的一般步骤,重点是slurmd的conf文件的配置;官网的内容比较全但不太好选择哪些是必须的,所以这里主要配置大家常用的东西,方便大家尽快上手。
另外,这里写了slurm的版本,大家要注意一下尽量使用相同的版本,跨版本的服务容易引起莫名其妙的错误。
1、环境准备
主机准备情况:
| 主机名及地址 | 配置服务 | 角色 | |
|---|---|---|---|
| host1 192.168.1.101 |
slurmctl slurmdbd |
控制节点, |
同时也为登陆节点 |
| host1 192.168.1.102 |
slurmctl slurmdbd slurmd |
控制节点, 计算节点 |
同时也为登陆备份节点,同时也作为计算节点 |
| host1 192.168.1.103 |
slurmd |
计算节点 | |
| host1 192.168.1.104 |
slurmd |
计算节点 |
建议所有节点的基础环境配置操作
1、使用nfs或者ceph的方式在集群所有节点全局共享用户/home目录,数据计算的工作/work目录,程序安装配置目录/nfs/sopt
ceph配置和使用:分布式存储ceph第17.2.6-quincy版本-全手动搭建完整方案(centos 9 stream)_小果运维的博客-CSDN博客
分布式存储ceph采用CephFS方式共享文件和挂载_ceph-fuse挂载-CSDN博客
分布式存储ceph rbd 常用操作_ceph rbd 命令_小果运维的博客-CSDN博客
分布式存储ceph osd 常用操作_ceph查看osd对应硬盘_小果运维的博客-CSDN博客
1、NFS共享配置:
2、配置各节点免密登陆
3、配置统一登陆认证nis服务或ldap服务
服务器集群配置LDAP统一认证高可用集群(配置tsl安全链接)-centos9stream-openldap2.6.2-CSDN博客
OpenLDAP配置web管理界面PhpLDAPAdmin服务-centos9stream-CSDN博客
4、节点间时间同步服务,建议chrony,时间同步很重要,不然节点之间有较大时间差时会报通信错误。建议使用控制节点作为时间服务器,其他节点同步控制节点时间。
2、SLURM服务安装
安装准备工作:
###先查看可安装的slurm包,
yum list | grep slurm
slurm.x86_64 22.05.9-1.el9 @epel
slurm-devel.x86_64 22.05.9-1.el9 @epel
slurm-libs.x86_64 22.05.9-1.el9 @epel
slurm-slurmctld.x86_64 22.05.9-1.el9 @epel
slurm-slurmd.x86_64 22.05.9-1.el9 @epel
slurm-slurmdbd.x86_64 22.05.9-1.el9 @epel
globus-gram-job-manager-slurm.noarch 3.0-10.el9 epel
pcp-pmda-slurm.x86_64 6.0.5-4.el9 appstream
slurm-contribs.x86_64 22.05.9-1.el9 epel
slurm-doc.x86_64 22.05.9-1.el9 epel
slurm-gui.x86_64 22.05.9-1.el9 epel
slurm-nss_slurm.x86_64 22.05.9-1.el9 epel
slurm-openlava.x86_64 22.05.9-1.el9 epel
slurm-pam_slurm.x86_64 22.05.9-1.el9 epel
slurm-perlapi.x86_64 22.05.9-1.el9 epel
slurm-rrdtool.x86_64 22.05.9-1.el9 epel
slurm-slurmrestd.x86_64 22.05.9-1.el9 epel
slurm-torque.x86_64 22.05.9-1.el9 epel
#############slurm的安装包比较全的话都在epel源,所以新系统最好安装epel源,否则可能存在依赖缺失问题。
yum install epel-release安装slurm服务包
###建议所有节点都安装这里指定的几个服务吧,不用分控制节点还是数据库存储节点。
yum install slurm slurm-devel slurm-libs slurm-slurmctld slurmd slurmdbd -y
###为配置节点之间的安全认证,建议配置munge服务,所有节点安装
yum install munge munge-libs munge-devel -y
安装mariadb或mysql数据库
如果想配置slurm服务的数据存储,建议安装mariadb,配置mariadb主主集群配置后续再补上,这里写单mariadb服务节点安装配置,大意如此,基本能用
###需要配置mariadb的repo源
yum -y install mariadb mariadb-server mariadb-devel
systemctl start mariadb && systemctl enable mariadb
###创建数据库
create database slurm_acct_db;
grant all privileges on slurm_acct_db.* to 'slurm'@'%' identified by '122213233';
flush privileges;
配置服务账户id
建议各节点slurm和munge两个系统账号的id在各节点之间配置相同
这个建议各个节点单独配置吧,多节点采用for语句也听方便。这里写单个节点的操作方式。
###查看各节点slurm和munge用户的uid和gid
###这里统一将所有没电的munge用户uid和gid均设置为1899,将slurm用户的uid和gid均设置为1898
###修改是注意先停止相应服务,更改完uid和gid后,在将对应服务和数据目录权限修改为新的账户
systemctl stop munge
usermod -u 1899 munge
groupmod -g 1899 munge
usermod -g 1899 munge
id munge
chown -R munge:munge /var/log/munge
chown -R munge:munge /etc/munge
chown -R munge:munge /var/run/munge
chown -R munge:munge /var/lib/munge
updatedb
locate munge
usermod -u 1898 slurm
groupmod -g 1898 slurm
usermod -g 1898 slurm
id slurm
chown -R slurm:slurm /var/log/slurm
chown -R slurm:slurm /etc/slurm
chown -R slurm:slurm /var/run/slurm
chown -R slurm:slurm /var/spool/slurm
同样这里要注意munge.key在各节点之间要一致,设置完后重启munge服务,下面是生成munge.key的命令
#在第一个节点执行后,拷贝到其他节点的/etc/munge/目录下,并修改权限为munge用户
/usr/sbin/create-munge-key -r更改账户uid和gid详细方法见:
linux系统创建用户、调整权限及用户和用户组id(centos 9 stream)_linux修改用户组id与用户id-CSDN博客
防火墙配置
如果集群对外,集群各节点对外没有统一的安全网关时建议配置好firewalld和selinux,firewalld要开放6818,6817等几个默认端口。
特别提示一下,系统slurm服务默认端口6718,6819等端口,如配置ceph集群也使用默认端口则可能导致6800这个端口段引发slurm和ceph服务的冲突,这里一定要注意避开,最好的建议就是ceph集群单独配置,否则注意修改slurm的端口或者修改ceph的服务端口,如果没有配置ceph或者使用6800这个端口段的服务的可以忽略。
如果集群为内部集群或有统一的对外网关这里可以直接将firewalld和selinux服务关闭
3、配置slurm.key
建议配置统一的slurm.cert和slurm.key用户集群之间信息的安全交互。
建议在/etc/slurm目录下新建pki或key或者certs作为证书文件存储目录,并将配置好的slurm.cert和slurm.key文件放入证书文件夹,所有节点保持一致
4、配置slurmdbd.conf
不想使用slurmdbd服务来存储slurm系统服务的账户等信息的,可以忽略此项配置,但需要在slurm.conf配置文件中指定存储方式为文件存储或者sqlite3,并配置。
这个在slurmdbd服务节点配置就行,建议配置两个,且使用haproxy配置为高可用,然后使用高可用虚拟ip进行配置。(后续再补,大家先执行探索)
###进入mariadb数据库创建slurm用户并设置密码并授权slurm_acct_db数据库的读写权限
create database slurm_acct_db //这里的命令是个形式哈,大家自己参考正式的数据库创建命令,反正这里使用名字为slurm_acc_db
###授权slurm用户对slurm_acc_db的读写权限,注意这里设置的密码要记住并与slurmdbd.conf中一致
grant all privileges on slurm_acct_db.* to 'slurm'@'%' identified by '123234h34343423' with grant option;
flush privileges;
####这里是slurmdbd服务配置的详细情况,这里使用的是haproxy代理的mariadb主主数据库集群
cat slurmdbd.conf
#
# See the slurmdbd.conf man page for more information.
#
# Archive info
#ArchiveJobs=yes
#ArchiveDir="/tmp"
#ArchiveSteps=yes
#ArchiveScript=
#JobPurge=12
#StepPurge=1
#
# Authentication info
AuthType=auth/munge
AuthInfo=/var/run/munge/munge.socket.2
#
# slurmdbd info
DebugLevel=4
DefaultQOS=normal,standby //统一写为standby,后面slurmdbd会自己根据情况是否设置为backup状态还是primary状态。
DbdAddr=192.168.1.101 //本机ip
DbdHost=host1 //本机机器名
DbdPort=26819 //默认为6819,如配置有ceph等服务建议修改
DbdBackupHost=host2 //这里是指定备份slurmdbd服务的主机名,根据实际情况修改。
LogFile=/var/log/slurm/slurmdbd.log
#MessageTimeout=300
PidFile=/var/run/slurm/slurmdbd.pid
#PluginDir=
PrivateData=accounts,users,usage,jobs
PurgeEventAfter=12month //这些就自己修改吧,影响不大。
PurgeJobAfter=12month
PurgeResvAfter=12month
PurgeStepAfter=12month
PurgeSuspendAfter=12month
PurgeTXNAfter=12month
PurgeUsageAfter=12month
SlurmUser=slurm //有的直接使用root,权限可能有点大,建议建立slurm用户并授权slurm对slurm服务目录的访问权限
#TrackWCKey=yes
#
# Database info
####下面是使用haproxy代理的mariadb主主集群,主要是为了高可用,如果只有一个mariadb的单机服务的话直接填写单机ip和对应的服务端口在下方就行。
StorageType=accounting_storage/mysql
StorageHost=192.168.1.151 //haproxy代理的mariadb主主服务集群vip服务ip
StoragePort=10206 //haproxy代理mariadb开放端口
StoragePass=123234h34343423 //与mariadb数据库授权时设置密码一致
StorageUser=slurm //数据库中的slurm用户
StorageLoc=slurm_acct_db //创建的数据库名称
################################################################
###在host2上配置slurmdbd时与上方配置文件基本一致,只是Dbdhost和DbdBackupHost要注意设置,而且备份数据库启动时默认需要先将Dbdhost修改为本主机名host2,启动后再将Dbdhost修改为实际主slurmdbd服务的主机名,从启动信息中可以看到slurmdbd是否处于backup状态。配置完成后,启动slurmdbd服务
###启动并将slurmdbd加入自动启动服务
systemctl enable slurmdbd --now多个slurmdbd的好处就是当一个slurmdbd服务出问题的时候另外一个会从back状态进入primary状态,如下面的信息,

重启后如发现已经有slurmdbd服务正常运行,则会自动进入backup状态
![]()
5、配置slurm.conf(核心)
如果配置slurmdbd服务的话就必须先配置步骤4,如果不使用slurmdbd服务的话可以将conf中的参数取消。这里只修改主要配置信息,其他配置信息大家可以根据需求修改,默认配置应该可以满足大部分的需求。
###这里是slurm的主要配置,所有slurm节点都要保持一致,否则会报警告信息
cat slurm.conf
# slurm.conf file generated by configurator.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ClusterName=biodiv_dhpc //集群名称,自己按喜好取
SlurmctldHost=host1(192.168.1.101) //主控制节点
SlurmctldHost=host2(192.168.1.102) //备份控制节点,多控制节点主要为高可用。
#SlurmctldHost=
#
AuthType=auth/munge //选用munge认证服务
JobCredentialPrivateKey=/etc/slurm/certs/slurm.key //配置slurm证书服务key
JobCredentialPublicCertificate=/etc/slurm/certs/slurm.cert //配置slurm证书服务cert
DisableRootJobs=YES //禁止root用户运行作业,安全考虑建议
#EnforcePartLimits=NO
#Epilog=
#EpilogSlurmctld=
#FirstJobId=1
#MaxJobId=67043328
#GresTypes=
#GroupUpdateForce=0
#GroupUpdateTime=600
#JobFileAppend=0
#JobRequeue=1
#JobSubmitPlugins=lua
#KillOnBadExit=0
LaunchType=launch/slurm
#Licenses=foo*4,bar
#MailProg=/bin/mail
#MaxJobCount=10000
#MaxStepCount=40000
#MaxTasksPerNode=512
MpiDefault=pmix
#MpiParams=ports=#-#
#PluginDir=
#PlugStackConfig=
#PrivateData=jobs
ProctrackType=proctrack/cgroup
#Prolog=
#PrologFlags=
#PrologSlurmctld=
#PropagatePrioProcess=0
#PropagateResourceLimits=
#PropagateResourceLimitsExcept=
#RebootProgram=
ReturnToService=1
SlurmctldPidFile=/var/run/slurm/slurmctld.pid
SlurmctldPort=26817
SlurmdPidFile=/var/run/slurm/slurmd.pid
SlurmdPort=26818
SlurmdSpoolDir=/var/spool/slurm/d
SlurmUser=slurm //建议使用slurm用户
#SlurmdUser=root
#SrunEpilog=
#SrunProlog=
StateSaveLocation=/var/spool/slurm/ctld
SwitchType=switch/none
#TaskEpilog=
TaskPlugin=task/affinity
#TaskProlog=
#TopologyPlugin=topology/tree
#TmpFS=/tmp
#TrackWCKey=no
#TreeWidth=
#UnkillableStepProgram=
#UsePAM=0
#
#
# TIMERS
#BatchStartTimeout=10
CompleteWait=1
#EpilogMsgTime=2000
#GetEnvTimeout=2
#HealthCheckInterval=0
#HealthCheckProgram=
InactiveLimit=0
KillWait=30
#MessageTimeout=10
#ResvOverRun=0
MinJobAge=300
#OverTimeLimit=0
SlurmctldTimeout=120
SlurmdTimeout=300
#UnkillableStepTimeout=60
#VSizeFactor=0
Waittime=0
#
#
# SCHEDULING
#DefMemPerCPU=0
#MaxMemPerCPU=0
#SchedulerTimeSlice=30
SchedulerType=sched/backfill
SelectType=select/linear
#
#
# JOB PRIORITY
#PriorityFlags=
#PriorityType=priority/basic
#PriorityDecayHalfLife=
#PriorityCalcPeriod=
#PriorityFavorSmall=
#PriorityMaxAge=
#PriorityUsageResetPeriod=
#PriorityWeightAge=
#PriorityWeightFairshare=
#PriorityWeightJobSize=
#PriorityWeightPartition=
#PriorityWeightQOS=
#
#
# LOGGING AND ACCOUNTING
###这里配置账户保存信息的方式,如果不想配置mysql数据库的话可以选文件或者sqlite的方式
AccountingStorageEnforce=associations,qos,limits
AccountingStorageHost=host1 //这里指定slurmdbd的主服务主机
AccountingStoragePass=/var/run/munge/munge.socket.2
AccountingStoragePort=26819 //这里端口修改后所有6819的storageport端口地方都要修改成这个。
AccountingStorageType=accounting_storage/slurmdbd //这里就是存储方式选择,其他方式去看官网吧。
AccountingStorageUser=slurm //数据库用户
AccountingStoreFlags=job_comment
JobCompHost=192.168.1.151 //数据库ip
JobCompLoc=slurm_acct_db //数据库名称
JobCompPass= 121244 //这个是密码,要与slurmdbd保持一致
JobCompPort=10306 //端口与slurmdbd.conf保持一致
JobCompType=jobcomp/none
JobCompUser=slurm
JobContainerType=job_container/none
JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/cgroup
SlurmctldDebug=info
SlurmctldLogFile=/var/log/slurm/slurmctld.log
SlurmdDebug=info
SlurmdLogFile=/var/log/slurm/slurmd.log
SlurmSchedLogFile=/var/log/slurm/slurmcschd.log
SlurmSchedLogLevel=3
#DebugFlags=
#
#
# POWER SAVE SUPPORT FOR IDLE NODES (optional)
#SuspendProgram=
#ResumeProgram=
#SuspendTimeout=
#ResumeTimeout=
#ResumeRate=
#SuspendExcNodes=
#SuspendExcParts=
#SuspendRate=
#SuspendTime=
#
#
# COMPUTE NODES
##计算节点配置信息,这里仅作参考,相同类型的主机可以如第三条配置信息这样合并配置写法。
##初始state都为UNKNOWN,当节点与控制节点通信后会更新状态为up或者down
##Weight表示节点使用优先级,值越小越优先使用
NodeName=host1 NodeAddr=192.168.1.101 CPUs=32 Boards=1 SocketsPerBoard=2 CoresPerSocket=8 ThreadsPerCore=2 RealMemory=266240 Weight=2 State=UNKNOWN
NodeName=host2 NodeAddr=192.168.1.102 CPUs=32 Boards=1 SocketsPerBoard=2 CoresPerSocket=8 ThreadsPerCore=2 RealMemory=28672 Weight=2 State=UNKNOWN
NodeName=host[3-4] NodeAddr=192.168.1.[103,104] CPUs=96 Boards=1 SocketsPerBoard=4 CoresPerSocket=12 ThreadsPerCore=2 RealMemory=245760 Weight=1 State=UNKNOWN
# PARTITIONS,
#给主机分区,这个后面运行的时候可以给用户配置可使用分区,用户提交时可指定使用分期。
#同一个节点可以属于多个分区,slurm运行权限和运行时间设定可根据分区指定
#MaxTime指定计算任务最长运行时间,默认为INFINITE
PartitionName=Common Nodes=host1,host2 Default=YES MaxTime=168:00:00 State=UP
PartitionName=high Nodes=host3,host4 MaxTime=INFINITE State=UP
节点实际资源信息查看可使用以下命令,为防止超算任务占用节点的全部资源,如控制节点也做计算节点,这样要注意将实际的cpus和memory可用资源调小一些,比如32个核的节点在配置文件中只写28个,保证4个核用户支撑数据库等服务。
###查看本机实际配置
slurmd -C
NodeName=host1 CPUs=32 Boards=1 SocketsPerBoard=2 CoresPerSocket=8 ThreadsPerCore=2 RealMemory=322148
UpTime=61-17:54:26
###这里表示有32个核或虚拟核(多线程), 实际物理内存有320G,注意RealMemory为MB单位。
###如果当前节点还运行有数据库等其他服务,为保证其他服务正常运行,在前面slurm.conf文件中建议CPUs设置为28或更小,RealMemory设置为286,720(280GB)或更小。6、配置cgroup.conf
vim /etc/slurm/cgroup.conf
CgroupAutomount=yes
ConstrainCores=no
ConstrainRAMSpace=no
除非有不同,否则默认就可以了
7、启动slurmctld控制节点服务
主节点和备份的slurmd服务节点顺序启动。
###启动slurmd服务并将其加入自动启动服务
systemctl enable slurmd --now
systemctl status slurmctld
● slurmctld.service - Slurm controller daemon
Loaded: loaded (/usr/lib/systemd/system/slurmctld.service; enabled; preset: disabled)
Active: active (running) since Thu 2023-09-28 16:38:36 CST; 1 month 29 days ago
Main PID: 1375480 (slurmctld)
Tasks: 18
Memory: 13.5M
CPU: 1h 42min 59.003s
CGroup: /system.slice/slurmctld.service
├─1375480 /usr/sbin/slurmctld -D -s
└─1375482 "slurmctld: slurmscriptd"
8、启动slurmd计算节点服务
####将/etc/slurm/slurm.conf文件复制到所有节点
scp或rsync都行
###启动slurmd服务,并加入自动启动
systemctl enable slurmd --now
###查看集群计算节点状态
sinfo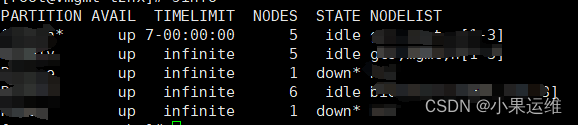
9、常用命令介绍
最开始要测试一下服务:
###三个服务一次运行,查看是否有报错信息。实际上就是相应服务的debug测试。
##slurdbd数据库存储节点测试
slurmdbd -vvvvDDDD
##slurmctld 控制节点测试
slurmctld -vvvvDDDD
##计算节点测试
slurmd -vvvvDDDDsacctmgr:显示和设置账户关联的QOS等信息
###要使用slurm系统,我们禁用root提交作业后,就必须创建slurm的普通用户
###注意这个创建账号并不是linux系统的账户,创建后需要与linux系统账户关联
###增加slurm账号
sacctmgr add account useraccount1
###一般默认srun及sbatch提交系统任务时,会以系统登陆账户作为slurm用户账号,如果当前登陆用户不是slurm使用用户则需要关联系统账号,或在运行脚本中指定运行用户和用户组
###所以一般建议大家创建与slurm账号相同的系统账户,或创建与系统账户对应的slurm账户,方便记忆,
###当然这两个账户不一样也没关系,只要等关联上就行,关联命令如下:
sacctmgr add user useraccount1 defaultAccount=useraccount1
###账号管理的其他命令,来自官方
#先创建tux集群
sacctmgr create cluster tux
#添加账户science,设定faireshare即优先级,值越小优先级越高
sacctmgr create account name=science fairshare=50
#创建chemistry,设定父级分组为science
sacctmgr create account name=chemistry parent=science fairshare=30
#同样创建physics账户,父级分组也为science
sacctmgr create account name=physics parent=science fairshare=20
#在集群tux上创建用户adam,指定属于physics
sacctmgr create user name=adam cluster=tux account=physics fairshare=10
#删除账户
sacctmgr delete user name=adam cluster=tux account=physics
sacctmgr delete account name=physics cluster=tux
#修改账户最大工作数和最大运行时间
sacctmgr modify user where name=adam cluster=tux account=physics set maxjobs=2 maxwall=30:00
#向chemistry组田间用户brian
sacctmgr add user brian account=chemistry
sacctmgr list associations cluster=tux format=Account,Cluster,User,Fairshare tree withd
sacctmgr list transactions Action="Add Users" Start=11/03-10:30:00 format=Where,Time
sacctmgr dump cluster=tux file=tux_data_file
sacctmgr load tux_data_file
###修改用户属性,包括可使用集群,账户类型,最多提交工作数量,每个工作最长运行时间等,参考如下
sacctmgr modify user where name=adam cluster=tux account=physics set maxjobs=2 maxwall=30:00
#其他的就不说了,默认直接使用创建的account就可以开始运行jobsbatch: 提交作业脚本。此脚本一般会包含一个或多个srun命令启动并行任务
###先填写slurm作业脚本
###典型的脚本头内容:
vim slurmbatch.sh
#!/bin/bash
#SBATCH -J jobname //超算的工作名
#SBATCH -N 1 //配置多少个节点,多个节点需要自己配置跨节点运行脚本,一般要在说有计算节点配置mpi
#SBATCH -n 40 //配置多少个核心
#SBATCH -p High //使用主机分区
#SBATCH -t 3-00:00:00 //最长运行时间
#SBATCH --comment="any comment"
##这里要注意,一定要在所有计算节点共享/work目录,否则会报错
export PATH=/work/bin:$PATH
###这里能写任何sh或程序运行脚本,与shell里编写脚本一致
###要运行python等脚本同样只需要指定python程序和python运行命令即可执行。
#######################################参数参考,前面都加#SBATCH即可
-J,--job-name 指定作业名称
-N,--nodes 节点数量
-n,--ntasks 使用的CPU核数
--mem 指定每个节点上使用的物理内存
-t,--time 运行时间,超出时间限制的作业将被终止
-p,--partition 指定分区
--reservation 执行资源预留名称
-w,--nodelist 指定特定的节点
-x,--exclude 分配给作业的节点中不要包含指定节点
--ntasks-per-node 指定每个节点使用几个CPU核心
--begin 指定作业开始时间
-D,--chdir 指定脚本/命令的工作目录
--export-file= 通过文件filename设定环境变量。文件中的环境变量格式为
NAME=value,变量之间通过空格分隔。
-o,--output= 采用--output可以将其重定向到同一文件中
--gpus 运行程序所需GPU的数量
sbatch运行脚本
sbatch slurmbatch.sh运行后会产生当前运行任务的jobid。
sinfo: 显示分区或节点状态,可以通过参数选项进行过滤、和排序
默认运行结果如下:
使用参数-l 内容如下

参数含义
PARRITION:节点所在分区。
AVAIL:分区状态,up标识可用,down标识不可用。
TIMELIMIT: 程序运行最大时长,infinite表示不限制,限制格式为days-houres:minutes:seconds。
NODES:节点数。
NODELIST:节点名列表。
STATE:节点状态,可能的状态包括
1 allocated、alloc :已分配
2 completing、comp:完成中
3 down:宕机
4 drained、drain:已失去活力
5 fail:失效
6 idle:空闲
7 mixed:混合,节点在运行作业,但有些空闲CPU核,可接受新作业
8 reserved、resv:资源预留
9 unknown、unk:未知原因
注意:如果状态带有后缀*,表示节点没有响应
当发现节点状态为down时,首先确认对应节点的配置文件、端口配置以及slurmd服务是否已经运行,如确认无误可以使用SCTRL UPDATE一下:
scontrol update NodeName=nodename State=RESUMEsqueue:显示队列的作业及作业状态
#直接运行即可查看在时间有效期内的工作运行排队情况
squeue
##结果表头含义
JOBID:作业号
PARITION:分区名
NAME:作业名
USER:用户名
ST:状态,常见的状态包括
NODELIST(REASON):分配给的节点名列表(原因)
#结果表头ST字段含义
PD、Q:排队中 ,PENDING
R:运行中 ,RUNNING
CA:已取消,CANCELLED
CG:完成中,COMPLETIONG
F:已失败,FAILED
TO:超时,TIMEOUT
NF:节点失效,NODE FAILURE
CD:已完成,COMPLETED
###NODELIST参数含义
AssociationJobLimit:作业达到其最大允许的作业数限制
AssociationResourceLimit:作业达到其最大允许的资源限制
AssociationTimeLimit作业:作业达到时间限制
Resource:作业等待期所需资源可用
QOSJobLimit:作业的QOS达到其最大的作业数限制
QOSResourceLimit:作业的QOS达到其最大资源限制
QOSTimeLimit:作业的QOS达到其最大时间限制
PartitionNodeLimit:作业所需的节点超过所用分区当前限制
PartitionTimeLimit:作业所需的分区达到时间限制
Priority :作业所需的分区存在高等级作业或预留
NodeDown:作业所需的节点宕机
JobHeldUser:作业被用户自己挂起
InvalidQOS:作业的QOS无效
##全部帮助命令:
squeue --help
Usage: squeue [OPTIONS]
-A, --account=account(s) comma separated list of accounts
to view, default is all accounts
-a, --all display jobs in hidden partitions
--array-unique display one unique pending job array
element per line
--federation Report federated information if a member
of one
-h, --noheader no headers on output
--hide do not display jobs in hidden partitions
-i, --iterate=seconds specify an interation period
-j, --job=job(s) comma separated list of jobs IDs
to view, default is all
--json Produce JSON output
--local Report information only about jobs on the
local cluster. Overrides --federation.
-l, --long long report
-L, --licenses=(license names) comma separated list of license names to view
-M, --clusters=cluster_name cluster to issue commands to. Default is
current cluster. cluster with no name will
reset to default. Implies --local.
-n, --name=job_name(s) comma separated list of job names to view
--noconvert don't convert units from their original type
(e.g. 2048M won't be converted to 2G).
-o, --format=format format specification
-O, --Format=format format specification
-p, --partition=partition(s) comma separated list of partitions
to view, default is all partitions
-q, --qos=qos(s) comma separated list of qos's
to view, default is all qos's
-R, --reservation=name reservation to view, default is all
-r, --array display one job array element per line
--sibling Report information about all sibling jobs
on a federated cluster. Implies --federation.
-s, --step=step(s) comma separated list of job steps
to view, default is all
-S, --sort=fields comma separated list of fields to sort on
--start print expected start times of pending jobs
-t, --states=states comma separated list of states to view,
default is pending and running,
'--states=all' reports all states
-u, --user=user_name(s) comma separated list of users to view
--name=job_name(s) comma separated list of job names to view
-v, --verbose verbosity level
-V, --version output version information and exit
-w, --nodelist=hostlist list of nodes to view, default is
all nodes
--yaml Produce YAML output
Help options:
--help show this help message
--usage display a brief summary of squeue options
scancel:取消排队或运行中的作业
#直接接jobid,一般提交任务时会显示生成的job号
scancel 2345scontrol:显示或设定slurm作业、分区、节点等状态
#查看指定节点信息
scontrol show nodes host1
#查看指定工作任务的运行详情
scontrol show job 941
#查看分区信息
scontrol show partition
PartitionName=batch
AllowGroups=ALL AllowAccounts=ALL AllowQos=ALL
AllocNodes=ALL Default=YES QoS=N/A
DefaultTime=NONE DisableRootJobs=NO ExclusiveUser=NO GraceTime=0 Hidden=NO
MaxNodes=UNLIMITED MaxTime=UNLIMITED MinNodes=1 LLN=NO MaxCPUsPerNode=UNLIMITED
Nodes=node4
PriorityJobFactor=1 PriorityTier=1 RootOnly=NO ReqResv=NO OverSubscribe=NO
OverTimeLimit=NONE PreemptMode=OFF
State=UP TotalCPUs=32 TotalNodes=1 SelectTypeParameters=NONE
DefMemPerNode=UNLIMITED MaxMemPerNode=UNLIMITED
DisableRootJobs:不允许root提交作业
Maxtime:最大运行时间
LLN:是否按最小负载节点调度
Maxnodes:最大节点数
Hidden:是否为隐藏分区
Default:是否为默认分区
OverSubscribe:是否允许超时
ExclusiveUser:排除的用户
sacct:显示历史作业信息
srun:运行并行作业,具有多个选项,如:最大和最小节点数、处理器数、是否指定和排除节点。
一般可能不用srun,更多时候是直接使用sbatch提交slurm的脚本。
差不多就这些了,后续再完善,敬请关注
原文地址:https://blog.csdn.net/zrc_xiaoguo/article/details/134634440
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_360.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!