本文介绍: DialoGPT是一个对话模型,由微软基于GPT-2训练。由于DialoGPT在对话数据上进行了预训练,所以它比原始的GPT-2更擅长生成类似对话的文本。DialoGPT的主要目标是生成自然且连贯的对话,而不是在所有情况下都提供事实上的正确答案。此外,由于模型的预训练数据主要是英文,因此它可能无法很好地处理中文输入。在运行代码之前,请确保已经安装了Hugging Face的Transformers库。
简介:DialoGPT是一个对话模型,由微软基于GPT-2训练。由于DialoGPT在对话数据上进行了预训练,所以它比原始的GPT-2更擅长生成类似对话的文本。DialoGPT的主要目标是生成自然且连贯的对话,而不是在所有情况下都提供事实上的正确答案。此外,由于模型的预训练数据主要是英文,因此它可能无法很好地处理中文输入。在运行代码之前,请确保已经安装了Hugging Face的Transformers库。
历史攻略:
flask+opencv+实时滤镜(原图、黑白、怀旧、素描)
安装:
pip install transformers
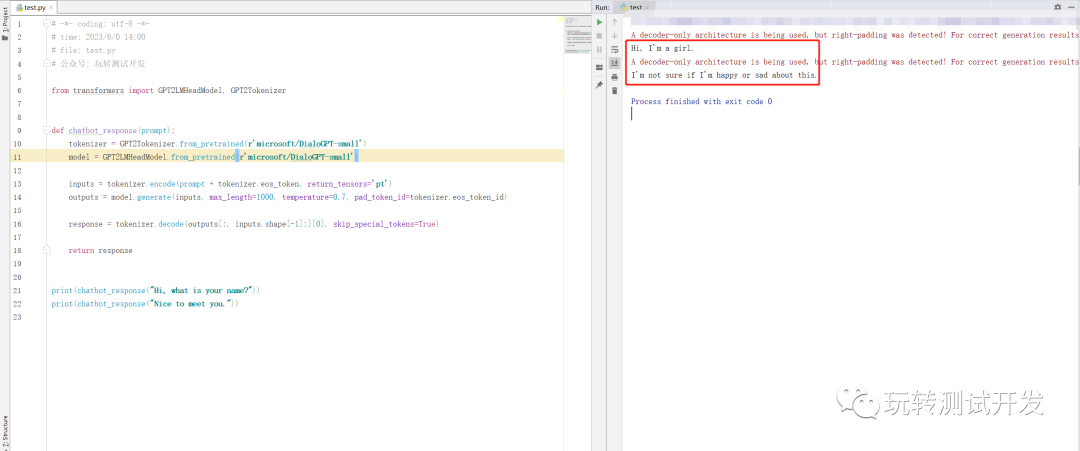
# -*- coding: utf-8 -*-
# time: 2023/6/9 14:00
# file: test.py
# 公众号: 玩转测试开发
from transformers import GPT2LMHeadModel, GPT2Tokenizer
def chatbot_response(prompt):
tokenizer = GPT2Tokenizer.from_pretrained('microsoft/DialoGPT-small')
model = GPT2LMHeadModel.from_pretrained('microsoft/DialoGPT-small')
inputs = tokenizer.encode(prompt + tokenizer.eos_token, return_tensors='pt')
outputs = model.generate(inputs, max_length=1000, temperature=0.7, pad_token_id=tokenizer.eos_token_id)
response = tokenizer.decode(outputs[:, inputs.shape[-1]:][0], skip_special_tokens=True)
return response
print(chatbot_response("Hi, what is your name?"))
print(chatbot_response("Nice to meet you."))
原文地址:https://blog.csdn.net/hzblucky1314/article/details/134763253
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36082.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。