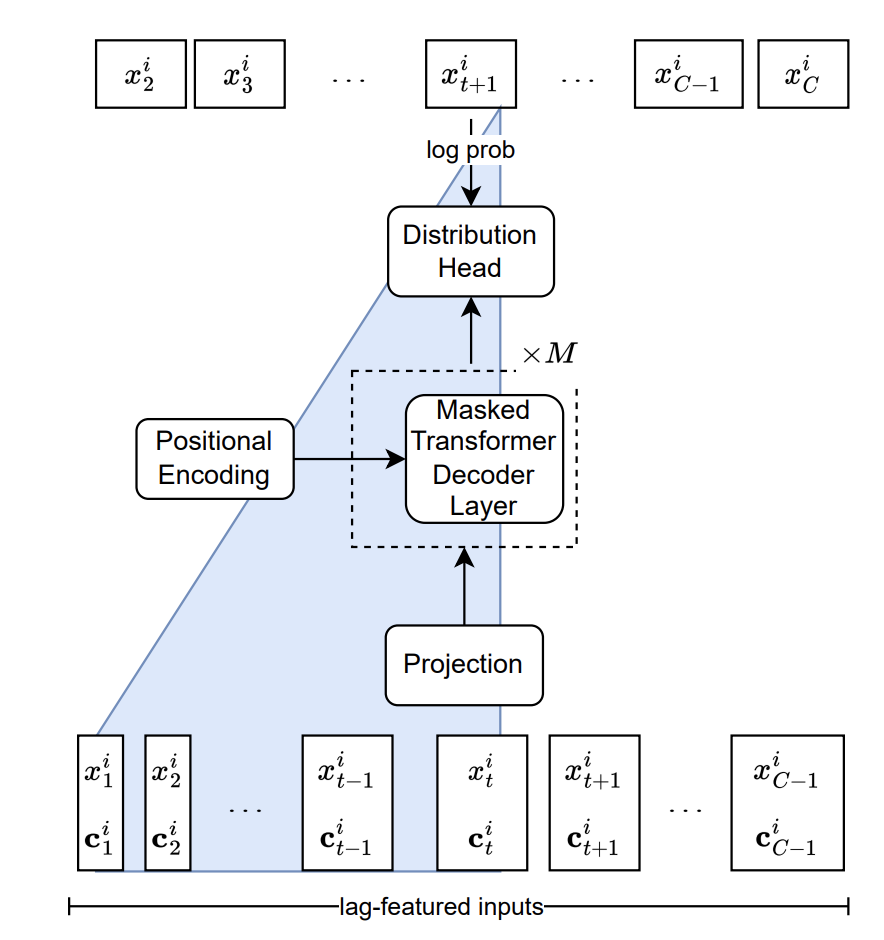
本文介绍: 注意到上面概率预测的定义中考虑了协变量C,Lag-Llama考虑的并不是像Nbeadts或TSMixer中的外部变量,而是来自序列本身的值。通常考虑一定的时间滞后,例如季度、月度、周度、日度、小时和秒级等,选取序列值,以匹配时间序列数据的周期性变化。当然作者指出也可以将单序列分成存在重叠的多个patch作为协变量,但这些patch中的数据点可能不再遵循时间上的因果性,因此作者更推荐第一种。
文章构建了一个通用单变量概率时间预测模型 Lag-Llama,在来自Monash Time Series库中的大量时序数据上进行了训练,并表现出良好的零样本预测能力。在介绍Lag-Llama之前,这里简单说明什么是概率时间预测模型。概率预测问题是指基于历史窗口内的序列值以及相关的一些协bianliang去预测一定窗口内未来值的联合分布
文章地址:https://arxiv.org/pdf/2310.08278v1.pdf
代码地址:https://github.com/kashif/pytorch–transformer–ts

技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
本文源代码已梳理完毕,建了技术交流群&星球!想要进交流群或者资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司,即可。然后就可以拉你进群了。
方案介绍
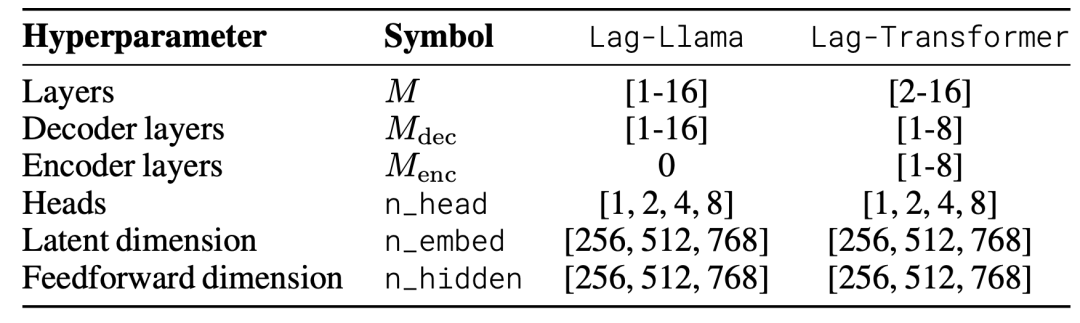
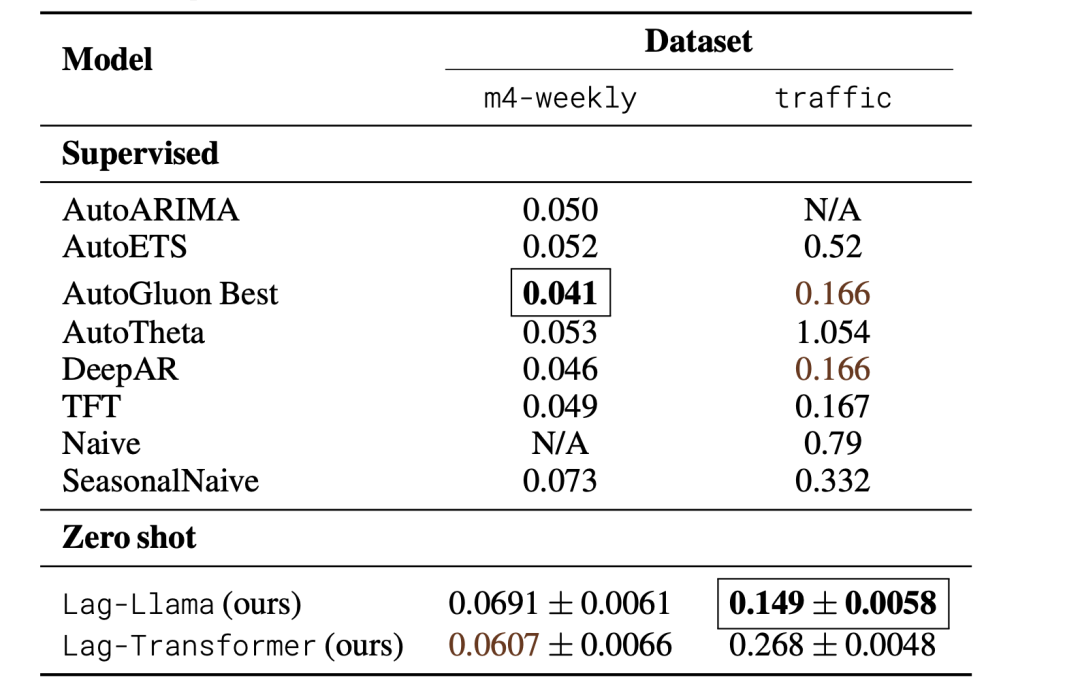
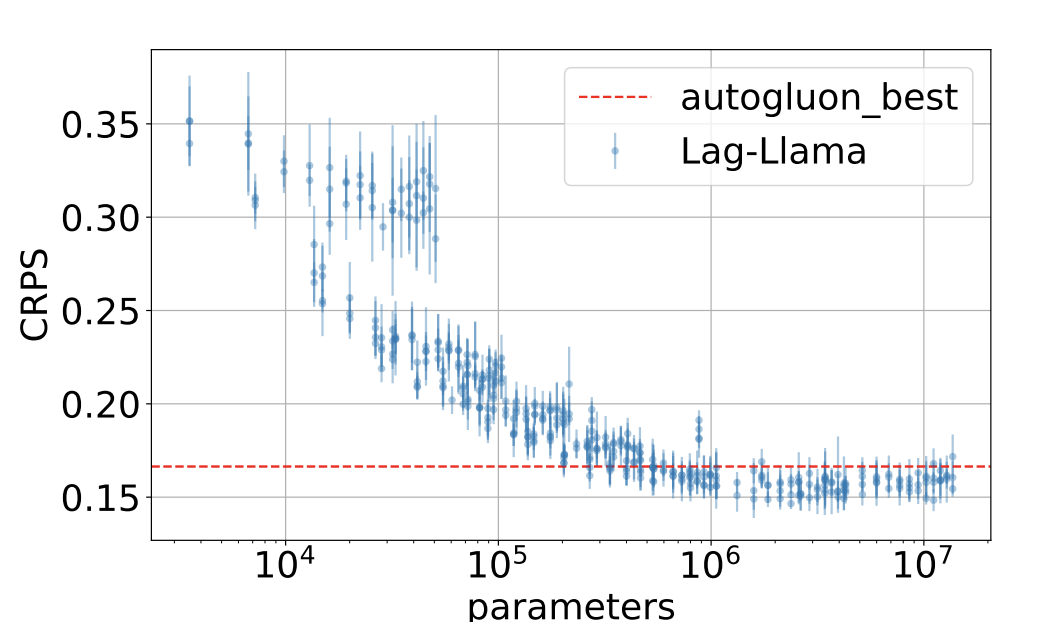
实验
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。