姿势检测是更多地了解视频和图像中人体的重要一步。 我们现有的模型支持 2D 姿态估计已经有一段时间了,你们中的许多人可能已经尝试过。
今天,我们在 TF.js 姿势检测 API 中推出第一个 3D 模型。 3D 姿态估计为健身、医疗、动作捕捉等应用开辟了新的设计机会 – 在其中许多领域,我们看到 TensorFlow.js 社区越来越感兴趣。 一个很好的例子是在浏览器中驱动角色动画的 3D 动作捕捉:

NSDT工具推荐: Three.js AI纹理开发包 – YOLO合成数据生成器 – GLTF/GLB在线编辑 – 3D模型格式在线转换 – 可编程3D场景编辑器 – REVIT导出3D模型插件 – 3D模型语义搜索引擎
上述社区演示使用由 MediaPipe 和 TensorFlow.js 支持的多个模型(即 FaceMesh、BlazePose 和 HandPose)。 更好的是,无需安装应用程序,你只需访问网页即可享受体验。 因此,考虑到这一点,让我们了解更多信息并看看这个新模型的实际应用!

1、安装
姿势检测 API 为 BlazePose GHUM 提供了两个运行时,即 MediaPipe 运行时和 TensorFlow.js 运行时。
要安装 API 和运行时库,你可以在 html 文件中使用:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script>
<!-- Include below scripts if you want to use TF.js runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script>
<!-- Optional: Include below scripts if you want to use MediaPipe runtime. -->
<script src="https://cdn.jsdelivr.net/npm/@mediapipe/pose"></script>yarn add @tensorflow-models/pose-detection
# Run below commands if you want to use TF.js runtime.
yarn add @tensorflow/tfjs-core @tensorflow/tfjs-converter
yarn add @tensorflow/tfjs-backend-webgl
# Run below commands if you want to use MediaPipe runtime.
yarn add @mediapipe/pose如果通过脚本标签安装,则可以通过全局命名空间poseDetection引用该库。
import * as poseDetection from '@tensorflow-models/pose-detection';
// Uncomment the line below if you want to use TF.js runtime.
// import '@tensorflow/tfjs-backend-webgl';
// Uncomment the line below if you want to use MediaPipe runtime.
// import '@mediapipe/pose';2、快速上手
const model = poseDetection.SupportedModels.BlazePose;
const detectorConfig = {
runtime: 'mediapipe', // or 'tfjs'
modelType: 'full'
};
detector = await poseDetection.createDetector(model, detectorConfig);选择适合你应用需求的型号,共有三种选项供你选择:精简型、完整型和重型。 从轻量级到重量级,精度提高,但推理速度降低。 请尝试我们的现场演示来比较不同的配置。
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);如何使用输出? 姿势表示图像帧中检测到的姿势预测的数组。 对于每个姿势,它包含关键点和关键点3D。 关键点与我们之前推出的2D模型相同,它是一个由33个关键点对象组成的数组,每个对象都有以像素为单位的x,y。
keypoints3D 是一个附加数组,包含 33 个关键点对象,每个对象都有 x、y、z。 单位为米。 对人进行建模,就好像他们处于 2m x 2m x 2m 的立方空间中。 每个轴的范围从 -1 到 1(因此总增量为 2m)。 该 3D 空间的原点是臀部中心 (0, 0, 0)。 从原点开始,如果靠近相机,则 z 为正值;如果远离相机,则 z 为负值。 例如,请参见下面的输出片段:
[
{
score: 0.8,
keypoints: [
{x: 230, y: 220, score: 0.9, name: "nose"},
{x: 212, y: 190, score: 0.8, name: "left_eye"},
...
],
keypoints3D: [
{x: 0.5, y: 0.9, z: 0.06 score: 0.9, name: "nose"},
...
]
}
]你可以参阅我们的自述文件以获取有关 API 的更多详细信息。
3、模型探讨
构建姿势模型 3D 部分的关键挑战是获取真实的野外 3D 数据。 与可以通过人工标注获得的 2D 相比,准确的手动 3D 标注成为一项独特的挑战性任务。 它需要实验室设置或带有用于 3D 扫描的深度传感器的专用硬件,这给在数据集中保持良好水平的人类和环境多样性带来了额外的挑战。 许多研究人员选择的另一种选择是构建一个完全合成的数据集,这引入了对现实世界图片进行域适应的另一个挑战。
我们的方法基于称为 GHUM 的统计 3D 人体模型,该模型是使用大量人体形状和动作语料库构建的。 为了获得 3D 人体姿势地面实况,我们将 GHUM 模型拟合到现有的 2D 姿势数据集,并使用度量空间中的真实世界 3D 关键点坐标对其进行扩展。 在拟合过程中,GHUM 的形状和姿态变量得到优化,使得重建模型与图像证据保持一致。 这包括 2D 关键点和轮廓语义分割对齐以及形状和姿势正则化术语。 有关更多详细信息,请参阅 3D 姿势和形状推断(HUND、THUNDR)的相关工作。

输入图像的 GHUM 拟合示例。 从左到右:原始图像、3D GHUM 重建(不同视点)和投影在原始图像顶部的混合结果。
由于 3D 到 2D 投影的性质,3D 中的多个点可以在 2D 中具有相同的投影(即具有相同的 X 和 Y 但不同的 Z)。 因此,对于给定的 2D 标注,拟合可以产生多个真实的 3D 身体姿势。 为了最大限度地减少这种模糊性,除了 2D 身体姿势之外,我们还要求标注者在确定的姿势骨架边缘之间提供深度顺序(检查下图)。 事实证明,这项任务是一项简单的任务(与真实深度标注相比),显示标注者之间的高度一致性(交叉验证为 98%),并有助于将拟合 GHUM 重建的深度排序误差从 25% 减少到 3%。

“深度顺序”标注:较宽的边缘角表示更靠近相机的角(例如,在两个示例中,人的右肩比左肩更靠近相机)
BlazePose GHUM 采用两步检测器跟踪器方法,跟踪器对裁剪后的人体图像进行操作。 因此,模型经过训练,可以预测以受试者臀部中心为原点的度量空间相对坐标中的 3D 身体姿势。
4、MediaPipe运行时 vs. TF.js 运行时
使用每个运行时都有一些优点和缺点。 如下性能表所示,MediaPipe 运行时在台式机、笔记本电脑和 Android 手机上提供更快的推理速度。 TF.js 运行时在 iPhone 和 iPad 上提供更快的推理速度。 TF.js 运行时也比 MediaPipe 运行时小约 1 MB。
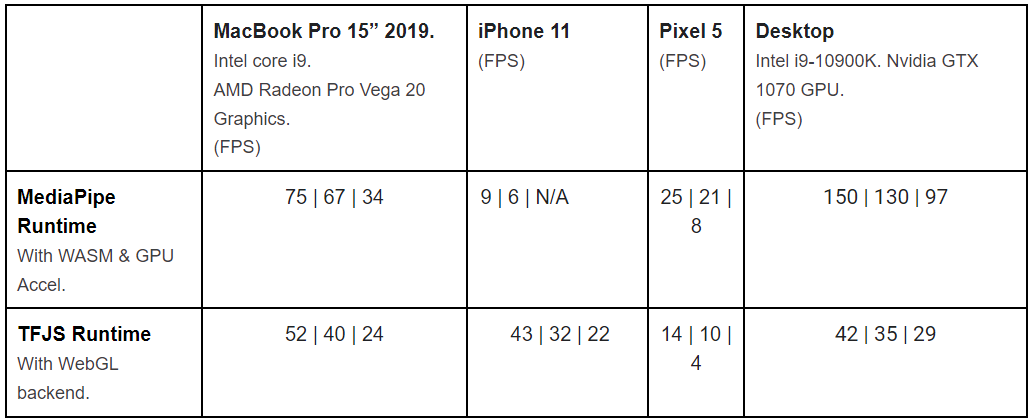
BlazePose GHUM 在不同设备和运行时的推理速度。 每个单元格中的第一个数字适用于精简模型,第二个数字适用于完整模型,第三个数字适用于重量级模型。
原文链接:MediaPipe 3D姿态估计 – BimAnt
原文地址:https://blog.csdn.net/shebao3333/article/details/134760927
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36112.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!