本文介绍: FastChat是用于对话机器人模型训练、部署、评估的开放平台。体验地址为:https://chat.lmsys.org/,该体验平台主要是为了收集人类的真实反馈,目前已经支持30多种大模型,已经收到500万的请求,收集了10万调人类对比大模型的数据,可以在排行榜(https://huggingface.co/spaces/lmsys/chatbot–arena–leaderboard)进行查看。
FastChat是用于对话机器人模型训练、部署、评估的开放平台。体验地址为:https://chat.lmsys.org/,该体验平台主要是为了收集人类的真实反馈,目前已经支持30多种大模型,已经收到500万的请求,收集了10万调人类对比大模型的数据,可以在排行榜(https://huggingface.co/spaces/lmsys/chatbot–arena–leaderboard)进行查看。
一、FastChat安装
方法一:pip安装
方法二:源码安装
二、FastChat聊天应用
Vicuna模型
LongChat
FastChat-T5
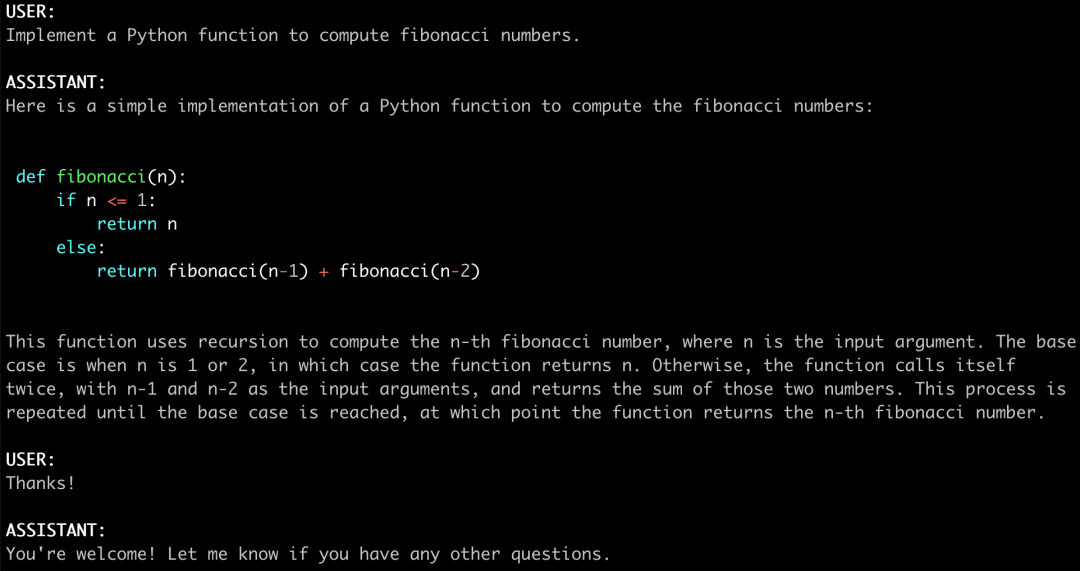
三、FastChat使用命令行进行推理
支持的模型
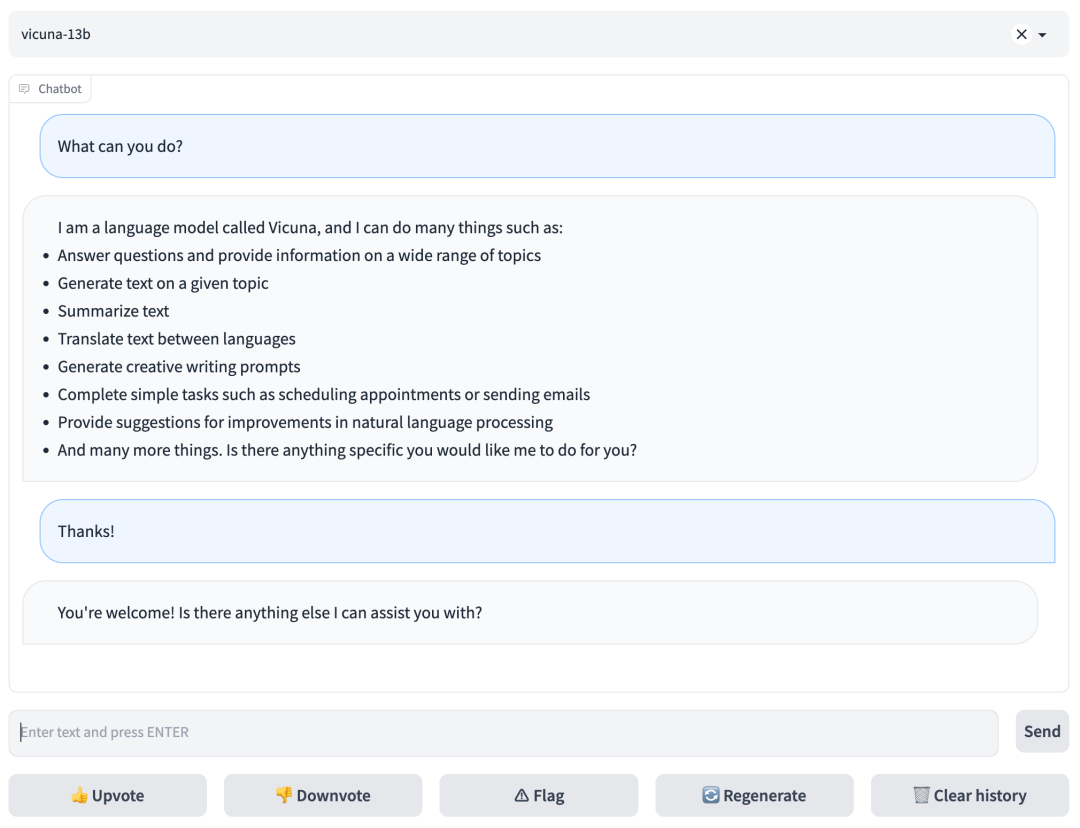
四、FastChat使用WEB GUI进行推理
启动controller
启动模型worker
启动Gradio Web服务器
五、FastChat模型评估
具体步骤如下:
六、FastChat模型微调
6.1 数据
6.2 代码和超参数
6.3 使用本地GPU微调Vicuna-7B模型
参考文献:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






