本文介绍: numpy实现神经网络搭建1. 参数的随机初始化2. 利用正向传播方法计算所有的结果3. 编写计算代价函数 的代码4. 利用反向传播方法计算所有偏导数5. 利用数值检验方法检验这些偏导数6. 使用优化算法来最小化代价函数
numpy实现神经网络
随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
训练神经网络一般步骤
- 参数的随机初始化
- 利用正向传播方法计算所有的
θ
(
)
hθ(x) - 编写计算代价函数
J
J
J 的代码 - 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数
激活函数和参数初始化
import numpy as np
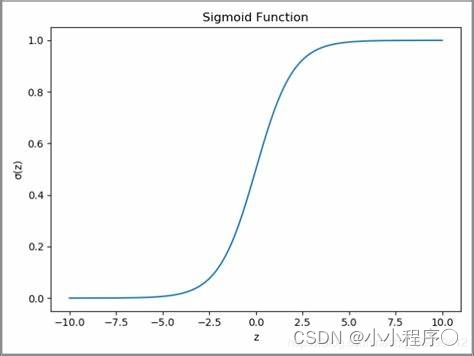
# sigmoid激活函数
def sigmoid(x):
return 1/(1+np.exp(-x))
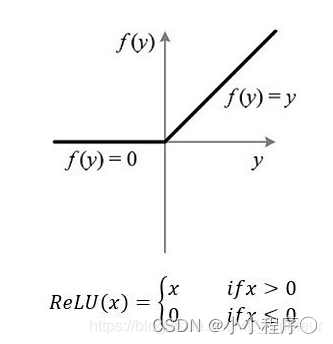
# relu激活函数
def relu(x):
return np.maximum(0, x)
# sigmoid反向传播函数
def sigmoid_back(x):
return x*(1-x)
# relu反向传播函数
def relu_back(x):
return np.where(x > 0, 1, 0)
#初始化参数
def initialize(input_size,hidden_size,output_size):
'''
input_size 输入层列数
hidden_size 隐藏层列数
output_size 输出层列数
'''
np.random.seed(42)
input_hidden_weights=np.random.randn(input_size,hidden_size)
input_hidden_bias=np.zeros((1,hidden_size))
hidden_out_weights=np.random.randn(hidden_size,output_size)
hidden_out_bias=np.zeros((1,output_size))
return input_hidden_weights,input_hidden_bias,hidden_out_weights,hidden_out_bias
前向传播和反向传播函数
# 前向传播
def forward(inputs,input_hidden_weights,input_hidden_bias,hidden_out_weights,hidden_out_bias):
hidden_input=np.dot(inputs,input_hidden_weights)+input_hidden_bias
hidden_output=relu(hidden_input)
final_input=np.dot(hidden_output,hidden_out_weights)+hidden_out_bias
final_output=sigmoid(final_input)
return hidden_output,final_output
# 后向传播
def backward(inputs,hidden_output,final_output,target,hidden_out_weights):
output_error = target - final_output
output_delta = output_error * sigmoid_back(final_output)
hidden_error = output_delta.dot(hidden_out_weights.T)
hidden_delta = hidden_error * relu_back(hidden_output)
return output_delta,hidden_delta
更新参数
# 更新参数
def update(inputs, hidden_output, output_delta, hidden_delta, input_hidden_weights, input_hidden_bias,
hidden_output_weights, hidden_output_bias, learning_rate):
hidden_output_weights =hidden_output_weights+ hidden_output.T.dot(output_delta) * learning_rate
hidden_output_bias = hidden_output_bias+ np.sum(output_delta, axis=0, keepdims=True) * learning_rate
input_hidden_weights = input_hidden_weights+ inputs.T.dot(hidden_delta) * learning_rate
input_hidden_bias = input_hidden_bias+ np.sum(hidden_delta, axis=0, keepdims=True) * learning_rate
return input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias
训练及预测模型
#训练模型
def train(inputs, target, input_size, hidden_size, output_size, learning_rate, epochs):
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias=initialize(input_size,hidden_size,output_size)
# 梯度下降优化模型
for epoch in range(epochs):
hidden_output,final_output=forward(inputs,input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias)
output_delta,hidden_delta=backward(inputs,hidden_output,final_output,target,hidden_output_weights)
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias=update(inputs,hidden_output,output_delta,hidden_delta,
input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias,learning_rate)
# 计算损失
loss = np.mean(np.square(targets - final_output))
if epoch % 100 == 0:
print(f"Epoch {epoch}: Loss {loss}")
return input_hidden_weights,input_hidden_bias,hidden_output_weights,hidden_output_bias
# 预测模型
def predict(inputs, input_hidden_weights, input_hidden_bias, hidden_output_weights,hidden_output_bias):
_, result = forward(
inputs, input_hidden_weights, input_hidden_bias, hidden_output_weights, hidden_output_bias)
return [1 if y_hat>0.5 else 0 for y_hat in result]
检验模型
# 定义训练数据和目标
inputs = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
target = np.array([[0], [1], [1], [0]])
# 定义神经网络参数
input_size = 2
hidden_size = 4
output_size = 1
learning_rate = 0.1
epochs = 1000
# 训练神经网络
parameters = train(inputs, target, input_size, hidden_size, output_size, learning_rate, epochs)
# 预测
predictions = predict(inputs, *parameters)
print("预测结果:")
print(predictions)
最终结果

原文地址:https://blog.csdn.net/2201_75381449/article/details/134761722
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36226.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。