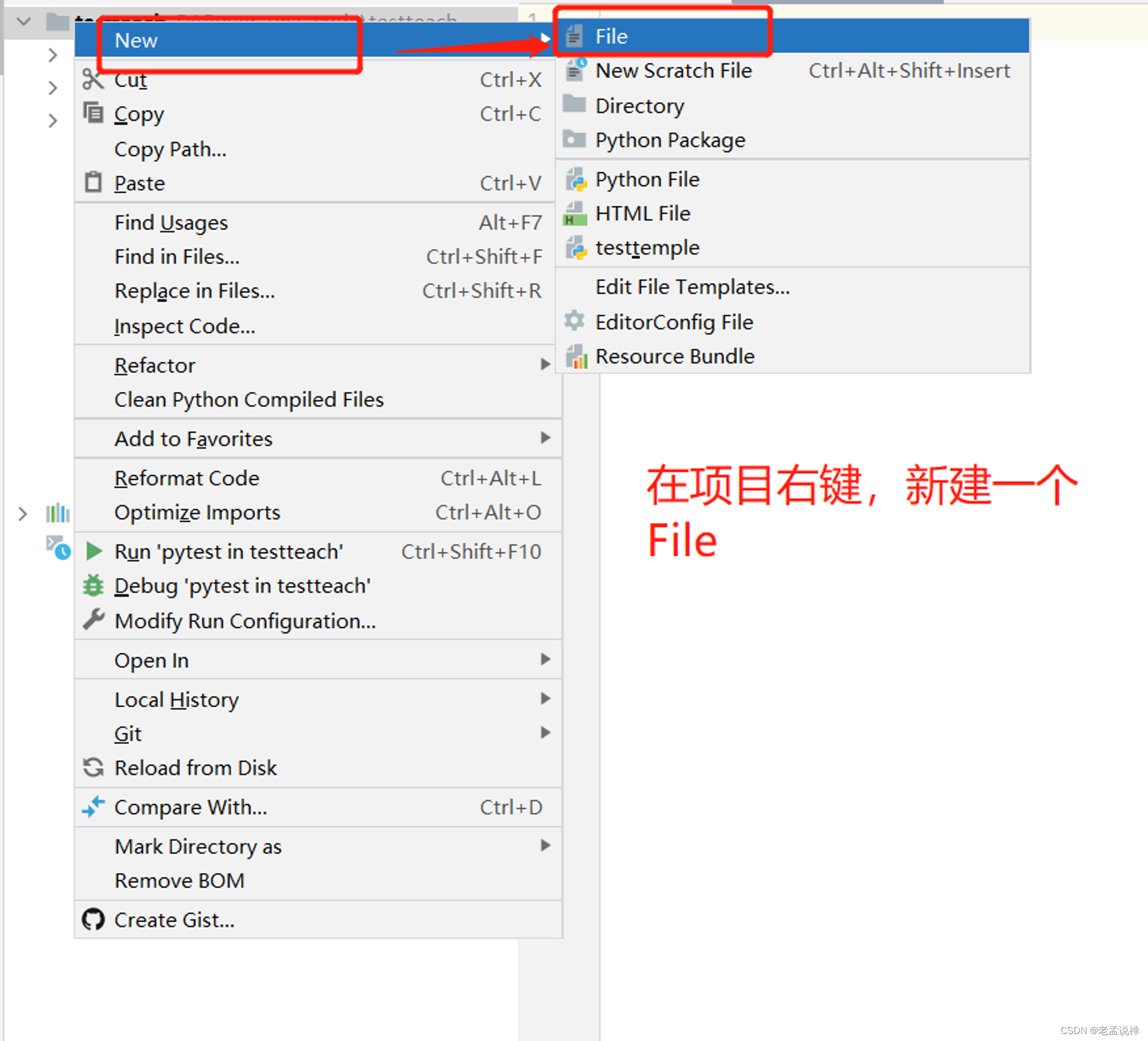
HDFS集群环境部署
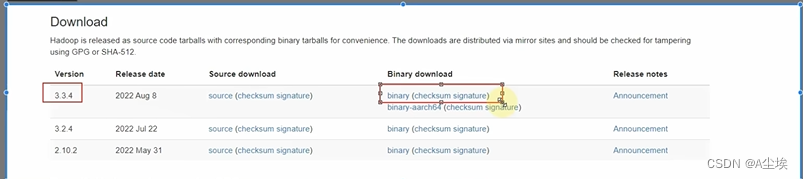
一、https://hadoop.apache.org中下载安装包
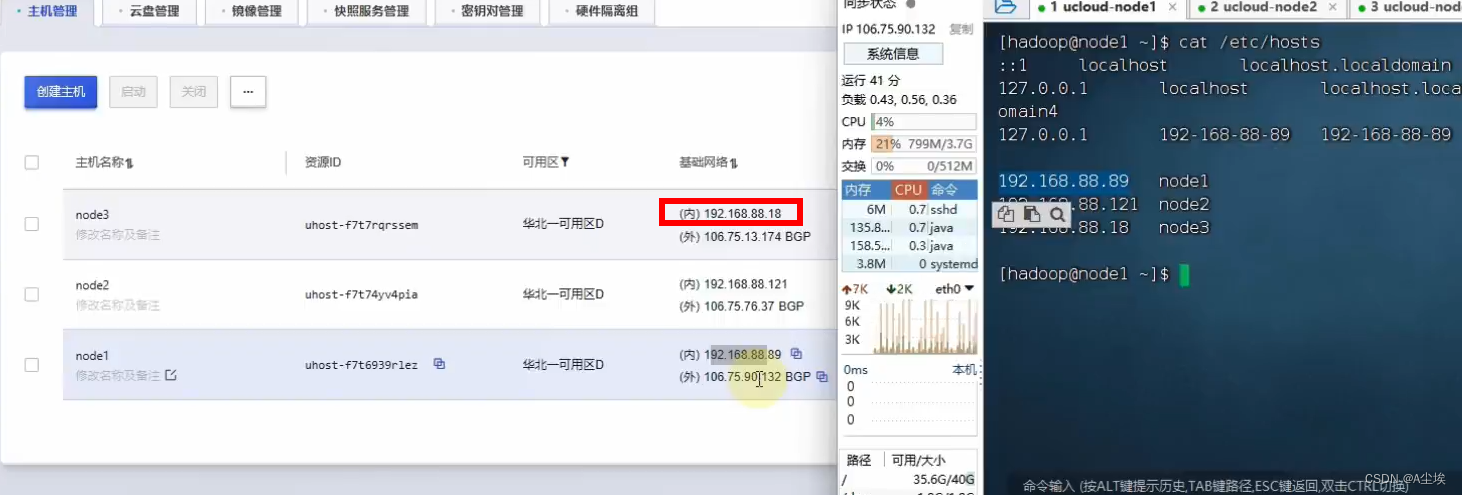
二、环境分配

三、上传、解压
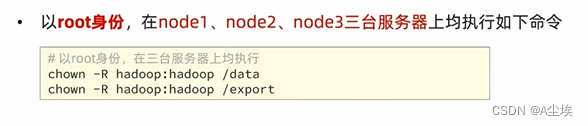
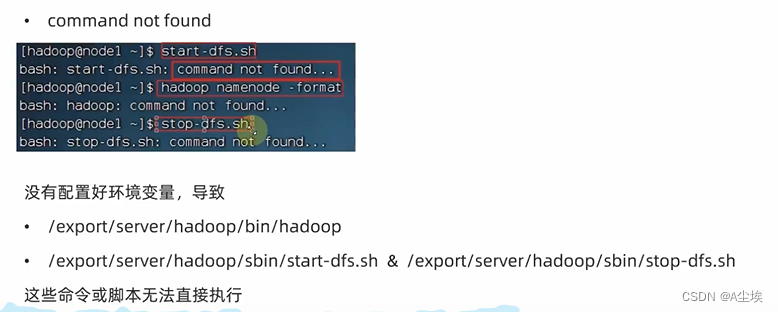
确认服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等

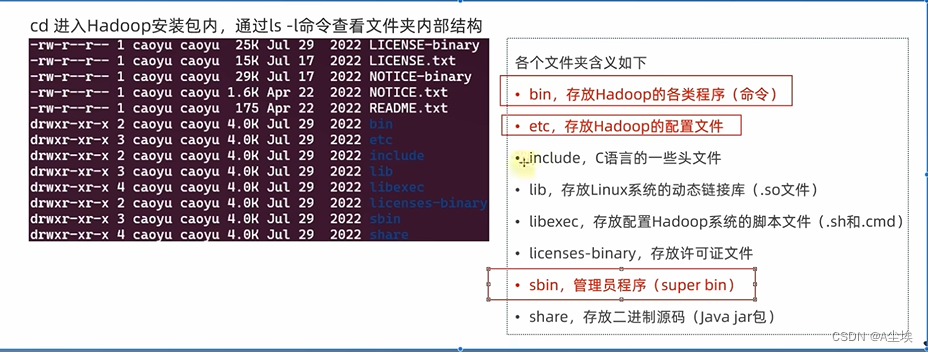



hdfs–site.xml
①、dfs.datanode.data.dir.perm 700
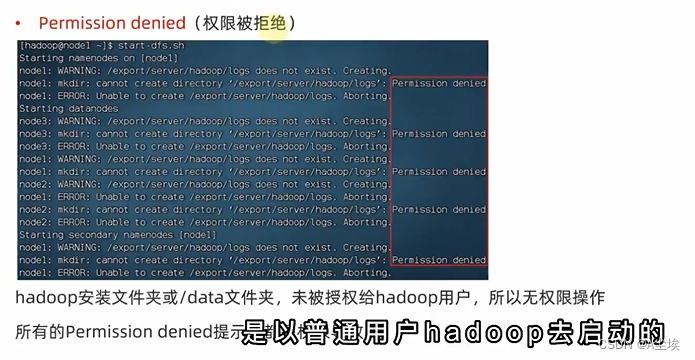
hdfs文件系统,默认权限700,rwx——
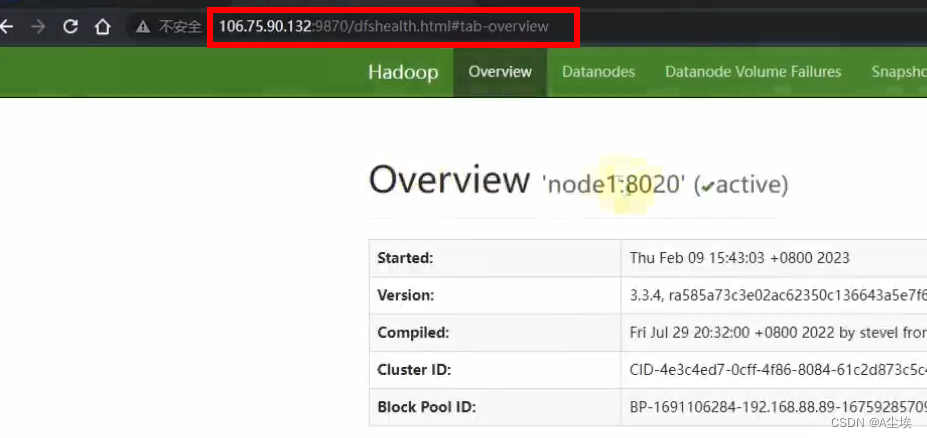
②、dfs.namenode.name.dir /data/nn
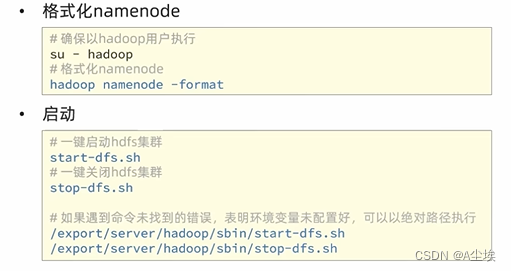
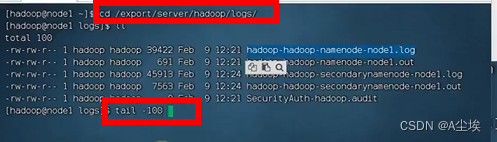
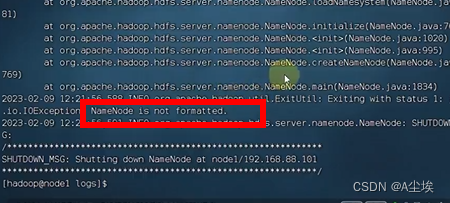
NameNode元数据的存储位置 在node1节点的/data/nn目录下
需要在node1节点:mkdir –p /data/nn mkdir data/dn 创建两个文件夹目录


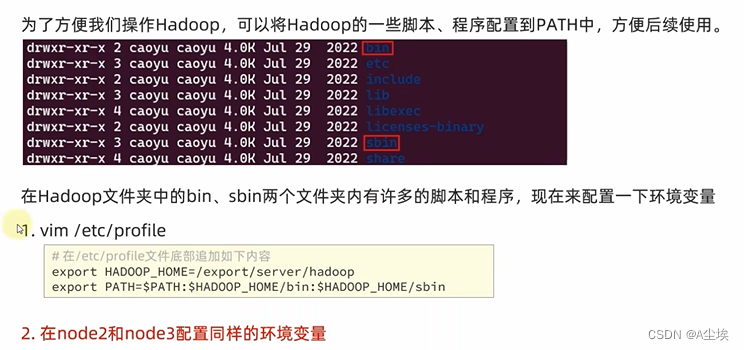
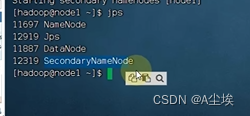
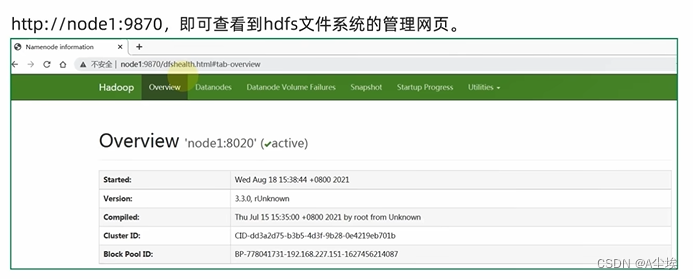






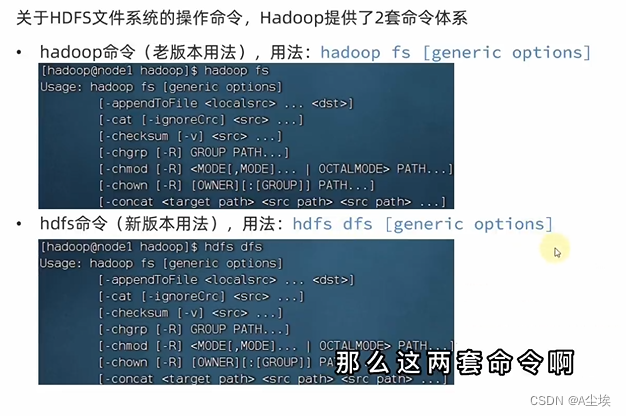
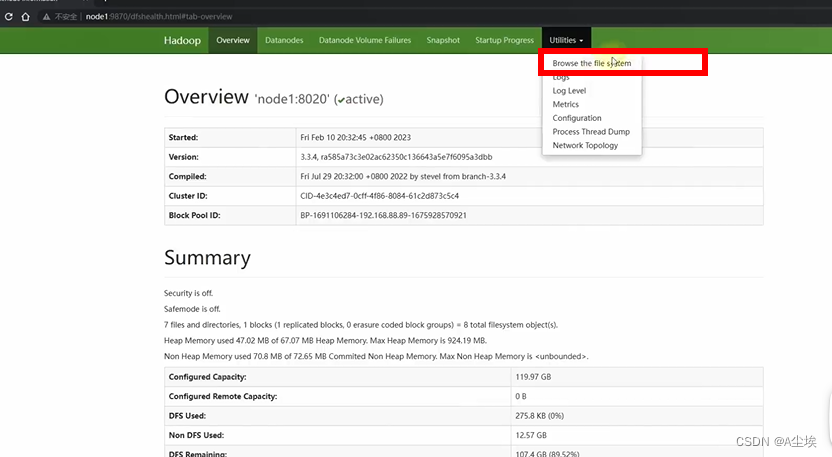
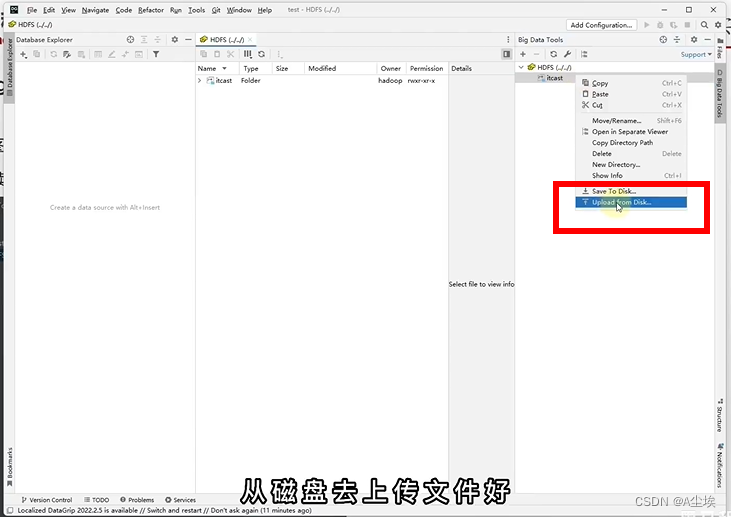
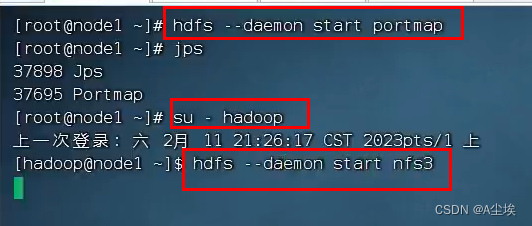
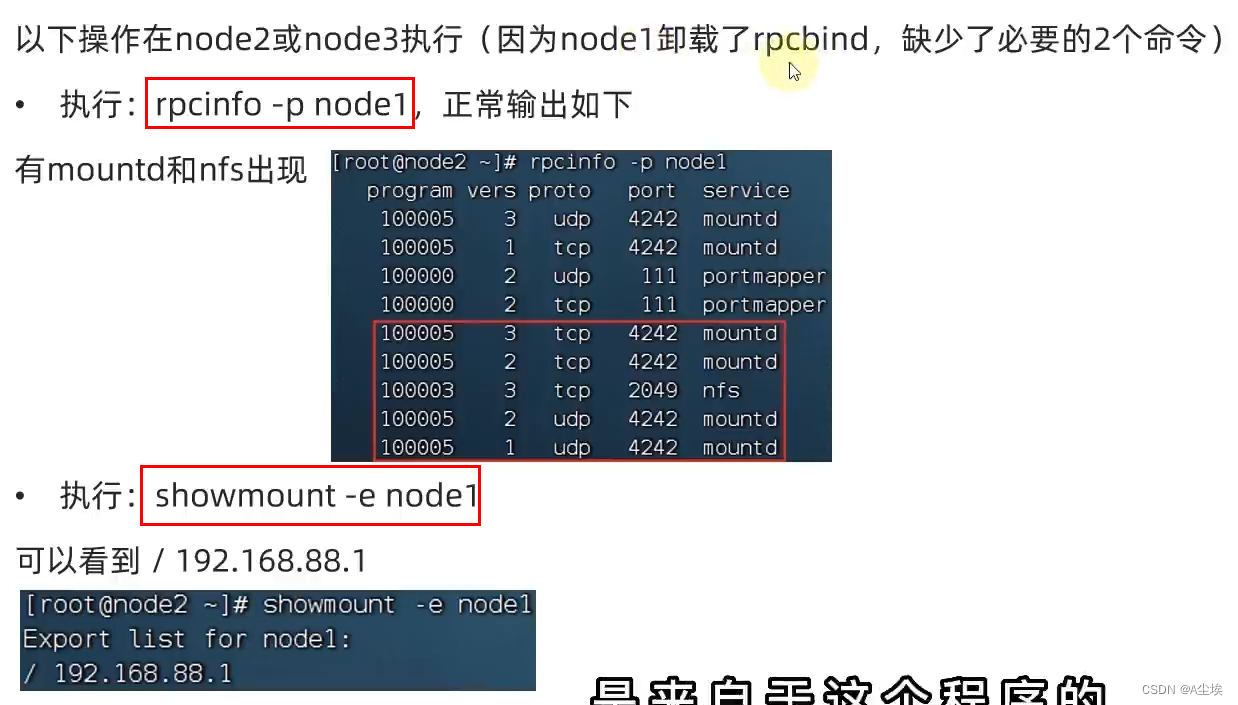
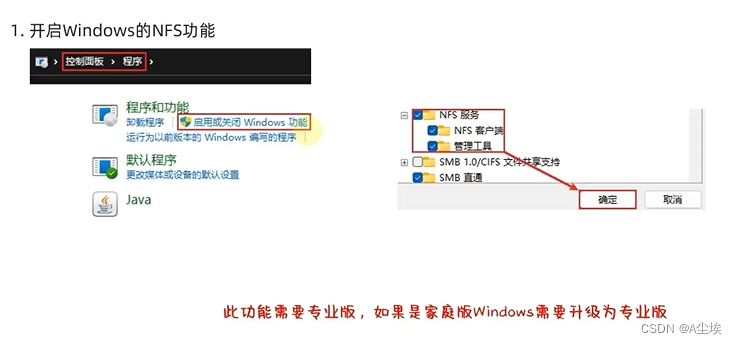
HDFS的Shell操作












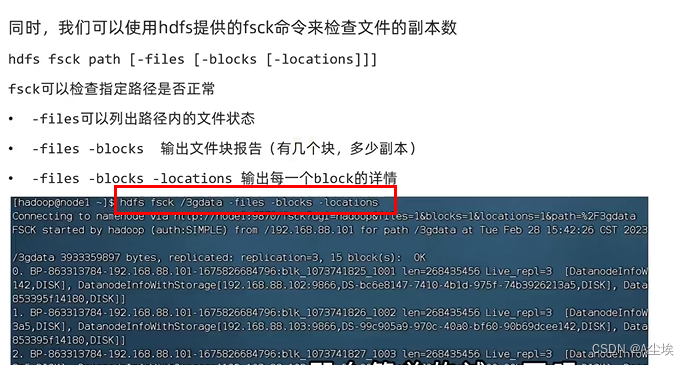
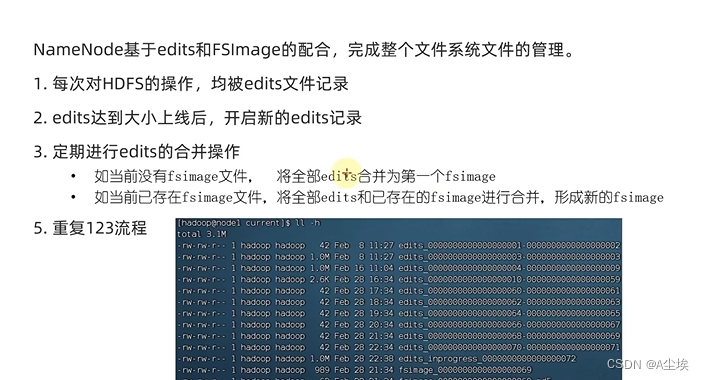
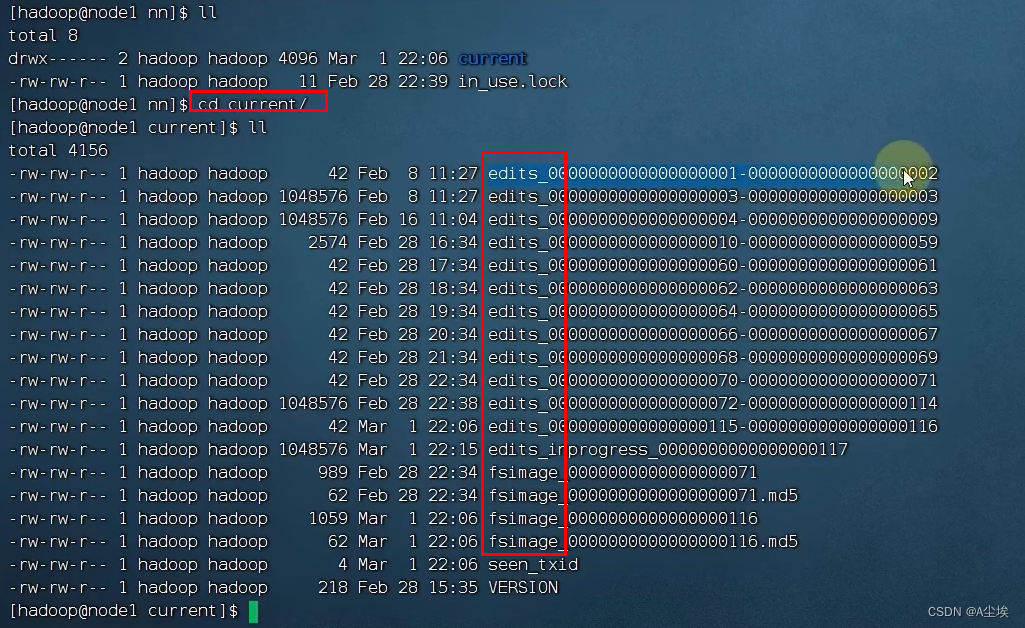
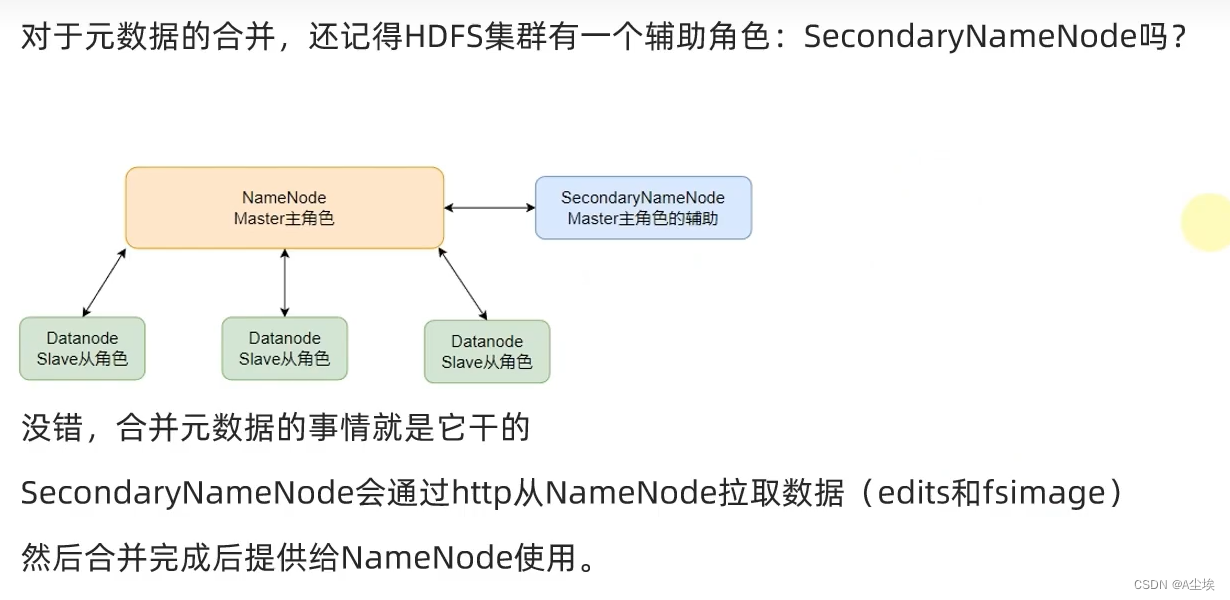
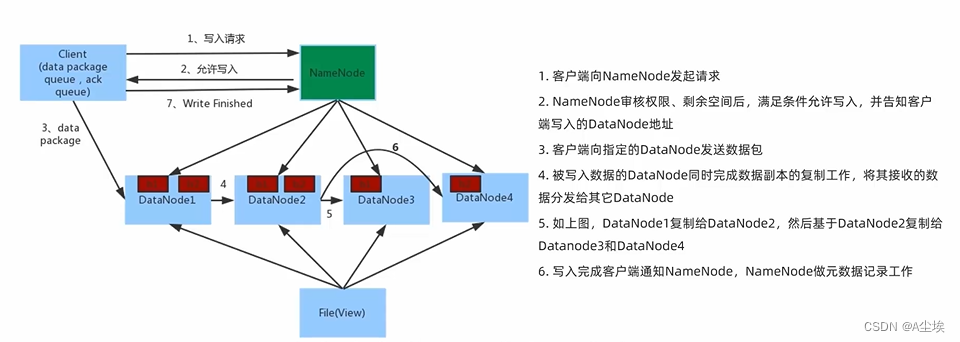
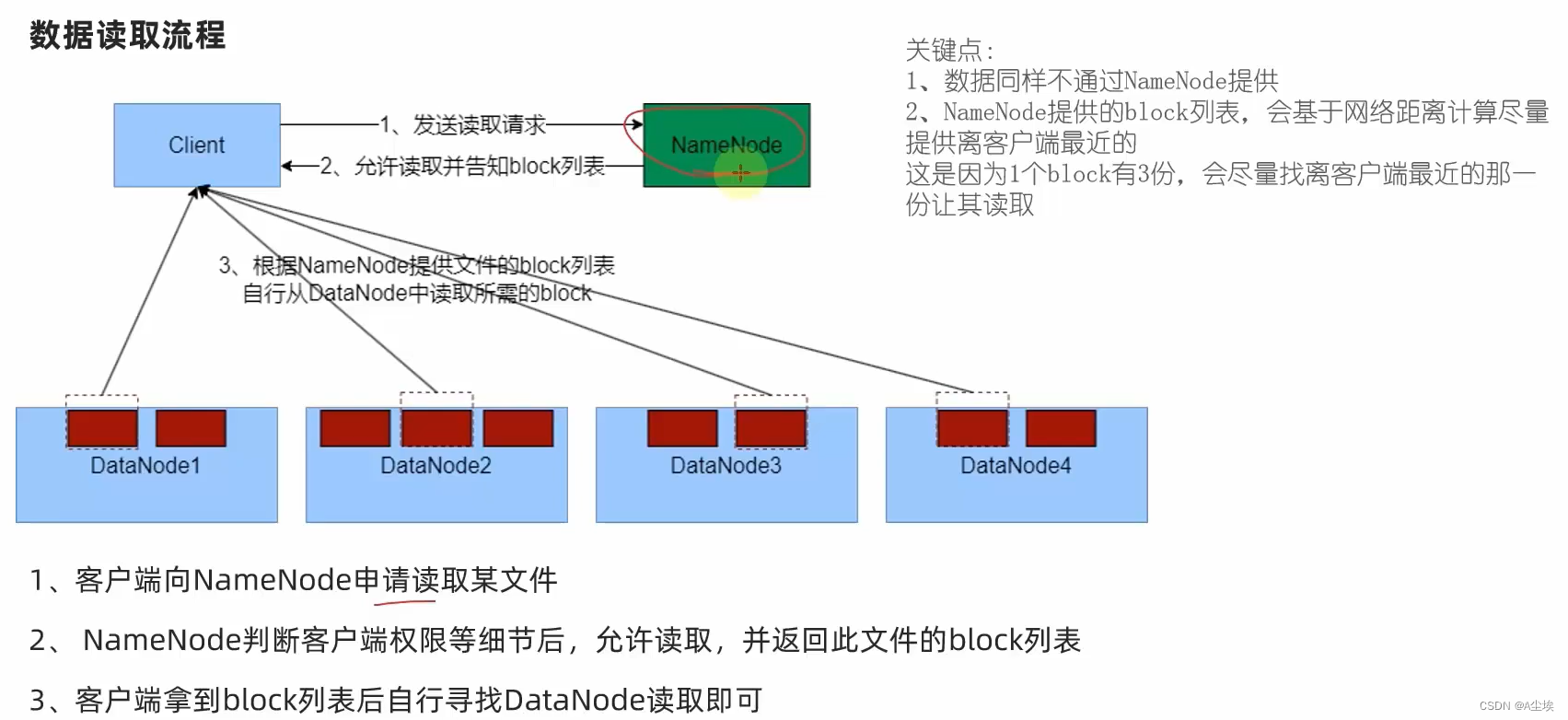
HDFS的存储原理








声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。