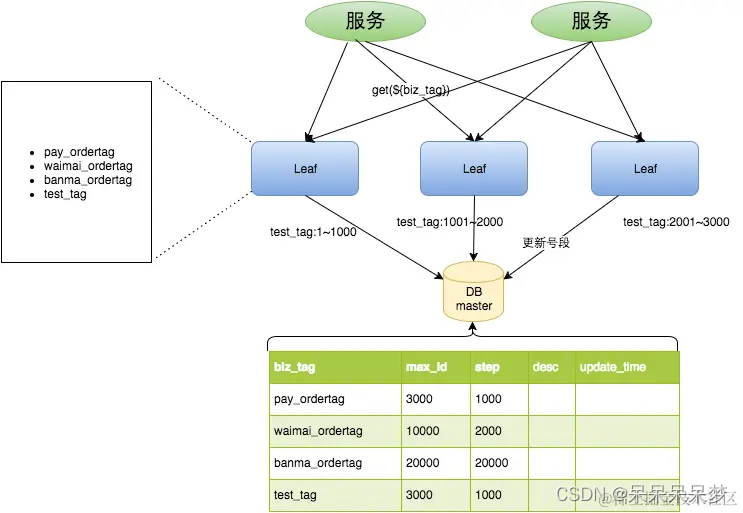
1、通过group by 和count(1)>1找出有重复的数据
前期准备:建表插入数据
1、通过group by 和count(1)>1找出有重复的数据
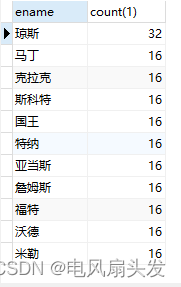
2、通过每个分组中的最小id来去重
2.1、添加主键id列
2.2 去重
2.2.1、首先找出每个分组中count(1) >1的数据中的最小id【min(id)】,sql语句如下:
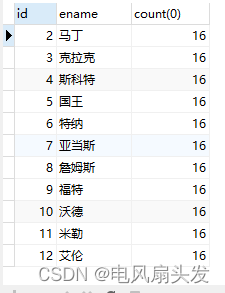
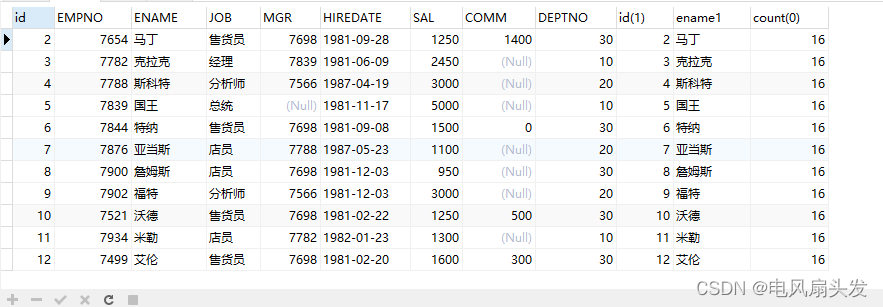
2.2.2、再将上表和emp表做表连接,sql语句如下:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。