1
∑
=
1
∣
(
)
−
y
^
e
(
)
∣
frac 1 m displaystylesum_{i=1}^m |y_{test}^{(i)}-hat y_{test}^{(i)}|
m1i=1∑m∣ytest(i)−y^test(i)∣
RMSE > MAE,因此RMSE 作为误差标准,能够更好的减小误差.
但是以上的指标都带着单位,这意味着我们无法对不同的模型进行比较,因此我们需要一种没有单位的指标 R Squared(
R
2
R^2
R2)

案例代码
我们将使用scikit–learn内置的波士顿房价数据集。波士顿房价数据集是一个经典的机器学习数据集,包含506个样本,每个样本有13个特征,如犯罪率、房产税率等。我们的目标是根据这些特征预测房屋价格
import numpy as np
import pandas as pd
## 准备数据, 因为官方内置函数load_boston在1.2版本移除了
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :3]])
y = raw_df.values[1::2, 2]
## 选择回归器,将使用线性回归作为我们的回归器
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
## 拆分数据集,我们通常将数据集拆分为训练集和测试集。训练集用于训练模型,测试集用于评估模型的性能。我们将数据集拆分为70%的训练集和30%的测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征工程-标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.fit_transform(X_test)
## 训练回归器
reg.fit(X_train, y_train)
## 评估回归器:当回归器训练完成后,我们需要使用测试集来评估回归器的性能。我们可以使用predict()函数对测试集进行预测,并使用score()函数计算回归器的性能指标,如均方误差、R平方等
y_pred = reg.predict(X_test)
mse = np.mean((y_pred - y_test) ** 2)
r2 = reg.score(X_test, y_test)
print("Mean Squared Error: ", mse)
print("R Squared: ", r2)
多元线性回归
我们将一元变量推广到多原变量,设多元函数式为

我们使用线性代数的向量概念对该式进行整理,记
w
0
=
w_0=b
w
w
w和特征向量
x

f
(
x
)
=
w
T
x
f(x)=w^Tx



对L(w)求偏导:

- 正规方程仅适用于线性回归模型,不可乱用;
- 若
X
T
X
X^TX
XTX为奇异矩阵则无法求其逆矩阵 - 使用正规方程时应该注意当特征数量规模大于10000时,
(
X
T
X
)
−
1
(X^TX)^{-1}
(XTX)−1求其逆矩阵的时间复杂度会很高
梯度下降法
梯度下降法是用来计算函数最小值的。它的思路很简单,想象在山顶放了一个球,一松手它就会顺着山坡最陡峭的地方滚落到谷底:

由导数知识我们不难发现,要使损失函数L(w)的值减小,我们只需让回归系数向与当前位置偏导数符号相反的方向更新即可,如下图所示:

于是,我们可以得到最基本的梯度下降算法的更新步骤:

其中,超参数
η
η代表学习速率(learning_rate),即单次更新步长。
η
η值的选择需谨慎,如果太小更新速率太慢则很难到达;如果太大则容易直接越过极值点。

寻找合适的步长
η

-
f
(
x
)
f(x)
f(x)往上走(红线),自然是η
η过大,需要调低 -
f
(
x
)
f(x)
f(x)一开始下降特别急,然后就几乎没有变化(棕线),可能是η
η较大,需要调低 -
f
(
x
)
f(x)
f(x)几乎是线性变化(蓝线),可能是η
eta
η过小,需要调高
另一个问题,并不是函数都有唯一的极值,有可能找到的是:局部最优解

解决方法: 多运行几次,随机初始点
由于不同特征的单位不同,梯度下降的方向也会受到一些数据偏大或者偏小的数字的影响,导致数据溢出,或者无法收敛到极小值。
解决方法: 数据归一化
小批量梯度下降(MBGD)
 因为要跳出“局部最优解”, 那么学习率eta这个参数就更加重要了,如果一直取个不变的学习率,很有可能到达最优解之后还会跳出去。因此,在实际的使用过程中,在随机梯度下降法中需要让学习率逐渐递减。
因为要跳出“局部最优解”, 那么学习率eta这个参数就更加重要了,如果一直取个不变的学习率,很有可能到达最优解之后还会跳出去。因此,在实际的使用过程中,在随机梯度下降法中需要让学习率逐渐递减。

案例代码
from sklearn.linear_model import SGDRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
import pandas as pd
# 导入必要的库
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :3]])
y = raw_df.values[1::2, 2]
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征工程-标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.fit_transform(X_test)
# 使用指定参数创建SGDRegressor
sgd_regressor = SGDRegressor(loss="squared_error", fit_intercept=True,max_iter=100000, learning_rate='invscaling', eta0=0.01)
# 将模型拟合到训练数据
sgd_regressor.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = sgd_regressor.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)
- loss=“squared_loss”: 此参数指定用于优化的损失函数。在线性回归中,通常使用平方损失,最小化残差的平方和。
- fit_intercept=True: 将该参数设置为True允许模型对数据进行拟合,引入截距项(偏置),这在数据没有零中心分布时是必要的。
- learning_rate=‘invscaling’: 学习率决定了优化过程中每次迭代的步长。’invscaling’会随着时间调整学习率,这在实现收敛时可能更有优势。
- eta0=0.01: 当使用’invscaling’学习率时,此参数设置了初始学习率。
主成分分析PCA
上述boston数据集收集许多关于房产的维度的数据,但有些维度的数据影响不大(即数据方差小).
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维,属于无监督学习。

如图,是否可以通过线性回归的方式,我们画出了x轴(红色). 即不变子空间,或者说基向量组.
当把所有的点映射到x轴(红色)上以后,点和点之间的距离大,就可拥有更高的可区分度.一般我们会使用方差(Variance),
找到一个轴,使得样本空间的所有点映射到这个轴的方差最大。同样的求最大值也有二种方法
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :3]])
y = raw_df.values[1::2, 2]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征工程-标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
X_train = transfer.fit_transform(X_train)
X_test = transfer.fit_transform(X_test)
## PCA主体分析
from sklearn.decomposition import PCA
pca = PCA(n_components=X_train.shape[1])
pca.fit(X_train)
## explained_variance_ratio_ 反映的是降维后的各主成分的方差值占总方差值的比例。这个比例越大,说明越是重要的主成分。
import matplotlib.pyplot as plt
plt.plot([i for i in range(X_train.shape[1])],
[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
plt.show()

import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep=r"s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :3]])
y = raw_df.values[1::2, 2]
# 特征工程-标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
X = transfer.fit_transform(X)
## PCA主体分析.0.95表示是降维后的各主成分的方差值占总方差值的比例
pca = PCA(0.95)
pca.fit(X)
X = pca.transform(X)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = reg.score(X_test, y_test)
print("Mean Squared Error: ", mse)
print("R Squared: ", r2)
数据降噪
- 对数据进行预处理。在应用PCA之前,需要对数据进行预处理,使其符合PCA的要求。一般来说,需要对数据进行中心化处理,即将每个特征的均值减去,使其均值为零。
- 重构去噪数据。使用选择的主成分,对中心化的数据进行重构。可以使用主成分矩阵的转置与原始数据相乘得到去噪后的数据。
import numpy as np
import matplotlib.pyplot as plt
## 原始数据
X = np.empty((100, 2))
## 制造噪声
X[:, 0] = np.random.uniform(0., 100., size=100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 5, size=100)
## 展示图表
plt.scatter(X[:,0], X[:,1])
plt.show()
## 使用PCA去降维去噪
from sklearn.decomposition import PCA
pca = PCA(n_components=1)
pca.fit(X)
x_reduction = pca.transform(X)
## 重构去噪数据
x_restore = pca.inverse_transform(x_reduction)
## 展示图表
plt.scatter(x_restore[:, 0], x_restore[:, 1])
plt.show()
多项式回归

Y
=
a
n
X
n
+
a
n
−
1
X
n
−
1
+
.
.
.
+
a
1
X
1
+
a
0
Y=a_nX^n+a_{n-1}X^{n-1}+…+a_1X^1+a_0
Y=anXn+an−1Xn−1+…+a1X1+a0
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 模拟出 y= x^2 + x + 2.5 + 误差 的数据
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1, 1)
y = 0.5 + x**2 + x + 2 + np.random.normal(0, 1, size=100)
# 用x创建出x^2的新特征
X2 = np.hstack([X, X**2])
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()

多项式回归在算法并没有什么新的地方,完全是使用线性回归的思路,关键在于为数据添加新的特征,而这些新的特征是原有的特征的多项式组合,采用这样的方式就能解决非线性问题,这样的思路跟PCA这种降维思想刚好相反,而多项式回归则是升维,添加了新的特征之后,使得更好地拟合高维数据
过拟合和欠拟合
- 欠拟合,直接使用简单的一次线性回归不构建新的特征,拟合的结果就是欠拟合(underfiting)

- 过拟合,多项式回归的最大优点就是可以通过增加x的高次项对实测点进行逼近,直至满意为止。但是这也正是它最大的缺点,因为通常情况下试过过高的维度对数据进行拟合,在训练集上会有很好的表现,但是测试集可能就不那么理想了.

欠拟合:underfitting,算法所训练的模型不能完整表述数据关系(即模型选错了)。
过拟合:overfitting,算法所训练的模型过多地表达数据间的噪音关系
通常在机器学习的过程中,主要解决的都是过拟合问题,因为这牵涉到模型的泛化能力。所谓泛化能力,就是模型在验证训练集之外的数据时能够给出很好的解答。只是对训练集的数据拟合的有多好是没有意义的,我们需要的模型的泛化能力有多好。
模型泛化
泛化即是,机器学习模型学习到的概念,在它处于学习的过程中时,模型遇见从未见过的样本时候的表现。
交叉验证
- 假如将所有的训练数据进行训练处一个模型,此时如果模型发生了过拟合却不自知,在训练集上的表现误差很小,但是很有可能模型的泛化能力不足,产生了过拟合。所以相应的我们就要把数据分为训练数据和测试数据,通过测试数据集来判断模型的好坏。
- 通常情况下如果将数据分为训练数据和测试数据,通过测试数据对模型的验证从而调整训练模型,也就说我们在围绕着测试集进行打转,设法在训练数据中找到一组参数,在测试数据上表现最好,既然是这样,就很有可能针对特定的测试数据集产生了过拟合。由此就引出了验证集(从训练集中再分出一部分)。
- 测试数据集作为衡量最终模型性能的数据集。测试数据不参与模型创建,而训练数据参与模型的训练,验证数据集参与模型评判,一旦效果不好就进行相应的调整重新训练,这两者都参与了模型的创建。验证数据集用来调整超参数。其实,这么做还是存在一定的问题,那就是这个验证数据集的随机性,因为很有可能对这一份验证集产生了过拟合。
因此就有了交叉验证(Cross Validation)。

我们将训练数据随机分为k份,上图中分为k=3份,将任意两种组合作为训练集,剩下的一组作为验证集,这样就得到k个模型,然后在将k个模型的均值作为结果调参。显然这种方式要比随机只用一份数据作为验证要靠谱的多。能前文的KNN算法为例子

交叉验证里面还有两种方式
- k-折交叉验证:把训练集分成k份,称为k-folds cross validation.缺点就是,每次训练k个模型,相当于整体性能慢了k倍。不过通常这种方法是最值得信赖的。
- 留一法LOO-CV: 在极端情况下。假设数据集中有m个样本,我们就把数据集分为m份,称为留一法。(Leave-One-Out Cross Validation),这样做的话,完全不受随机的影响,最接近模型真正的性能指标,缺点就是计算量巨大。
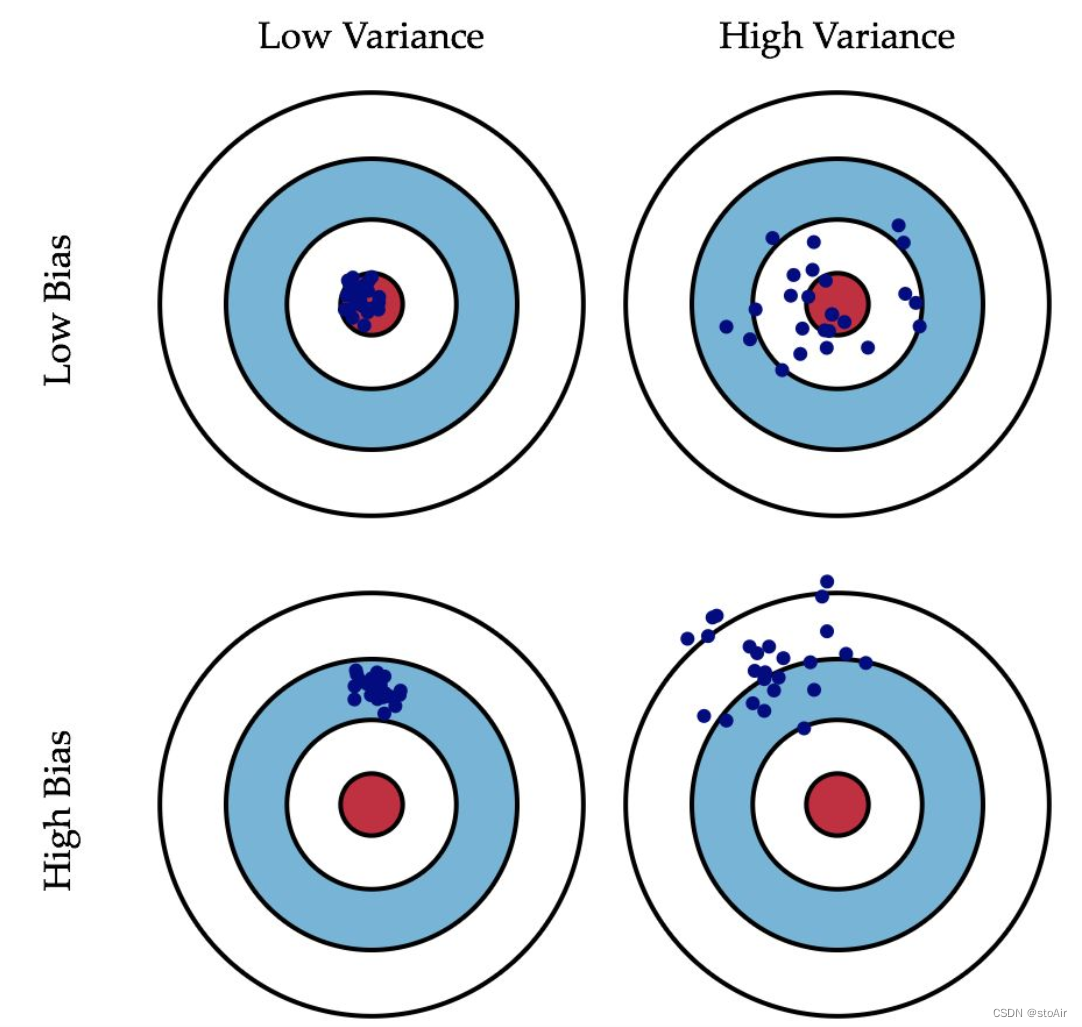
偏差方差权衡
当我们的模型表现不佳时,通常是出现两种问题,一种是 高偏差 问题,另一种是 高方差 问题。
模型误差 = 偏差 + 方差 + 不可避免的误差
- 导致偏差大的原因:对问题本身的假设不正确!如非线性数据使用线性回归。或者特征对应标记高度不相关也会导致高偏差,不过这是对应着特征选择,跟算法没有关系,对于算法而言基本属于欠拟合问题underfitting。
- 导致方差大的原因:数据的一点点扰动都会极大地影响模型。通常原因就是使用的模型太复杂,如高阶多项式回归。这就是所说的过拟合(overfitting)
有些算法天生就是高方差的算法,如KNN,非参数学习的算法通常都是高方差的,因为不对数据进行任何假设。还有一些算法天生就是高偏差的,如线性回归。参数学习通常都是高偏差算法,因为对数据具有极强的假设。
偏差和方差通常是矛盾的,降低偏差,会提高方差,降低方差,会提高偏差,因此在实际应用中需要进行权衡。机器学习的主要挑战,在于方差。这句话只针对算法,并不针对实际问题。因为大多数机器学习需要解决过拟合问题。
模型正则化
正则化项 (又称惩罚项),惩罚的是模型的参数,其值恒为非负.从而限制参数的大小。常常用来解决过拟合问题。

通过加入的正则项
λ
f
(
w
)
lambda f(w)
λf(w)
来控制系数不要太大,从而使曲线不要那么陡峭,变化的那么剧烈。
系数太大,
λ
f
(
w
)
lambda f(w)
λf(w)就会变大.假如一项为wx,为了满足x=5,y=1000,拟合参数w=1000.此时有了正则项的加入,破使wx项系变小.
岭回归(Ridege Regression)
以线性回归的损失函数为例子


LASSO Regularization
以线性回归的损失函数为例子


比较Ridge和Lasso


从梯度方面来看,当w处于
[
1
,
+
∞
]
[1, +infty]
[1,+∞]时,L2(Ridge)比L1(Lasso)获得更大的减小速率,而当w处于(0,1)时,L1(Lasso)比L2(Ridge)获得更快的减小速率,并且当w越小,Ridge更容易接近到0,而Lasso更不容易变化。
Lasso则是趋向于使得一部分w 的值变为0。所以可以作为特征选择用。不过也正是因为这样的特性,使得Lasso这种方法有可能会错误将原来有用的特征的系数变为0,所以相对Ridge来说,准确率还是Ridge相对较好一些,但是当特征特别大时候,此时使用Lasso也能将模型的特征变少的作用。
主要参考
《机器学习理论(二)简单线性回归》
《机器学习理论(三)多元线性回归》
《机器学习理论(四)线性回归中的梯度下降法》
《机器学习理论(五)主成分分析法》
《机器学习理论(六)多项式回归》
《机器学习理论(七)模型泛化》
《PCA(主成分分析)》
《非常详细的线性回归原理讲解》
《什么是梯度下降法?》
《L1正则化和L2正则化》
原文地址:https://blog.csdn.net/y3over/article/details/134653130
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36678.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!