Slurm简介
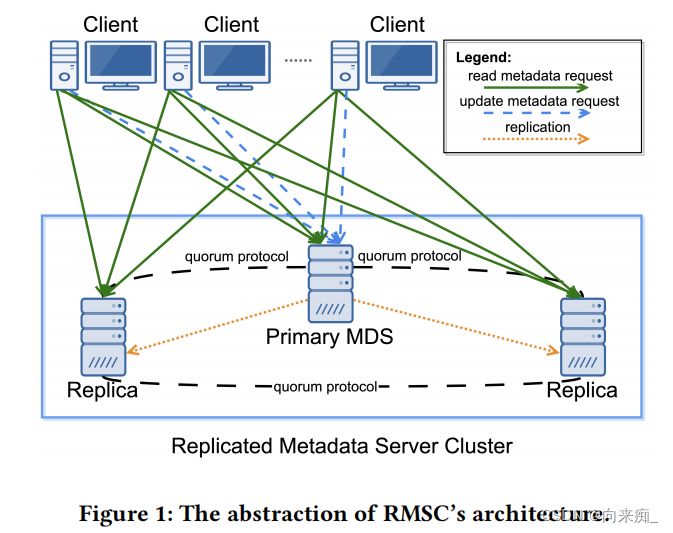
SLURM(Simple Linux Utility for Resource Management)是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统,被世界范围内的超级计算机和计算集群广泛采用。它是一个开源,容错,高度可扩展的集群管理和作业调度系统,适用于大型和小型Linux集群。Slurm不需要对其操作进行内核修改,并且相对独立。作为集群工作负载管理器,Slurm有三个关键功能:
Slurm组件简介
1 资源(Resource)
作业运行过程中使用的可量化实体都是资源;
包括硬件资源(节点、内存、CPU 、GPU等)和软件资源( License )
2 集群(Cluster)
包含计算、存储、网络等各种资源实体且彼此联系的资源集合;
在物理上,一般由计算处理、互联通信、I/O 存储、操作系统、编译器、运行环境、开发工具等多个软硬件子系统组成;
节点是集群的基本组成单位,从角色上一般可以划分为管理节点、登陆节点、计算节点、存储节点等。一般用户接触到的有管理节点和计算节点,登录和存储节点一般用户不可直接接触。
3 作业(Job)
物理构成,一组关联的资源分配请求,以及一组关联的处理过程;
交互方式,可以分为交互式作业和非交互式作业;
资源使用,可以分为串行作业和并行作业;
4 分区(Partition)
5 作业调度系统(Job Schedule System)
负责监控和管理集群中资源和作业的软件系统;
通常由资源管理器、调度器、任务执行器,以及用户命令和API组成
Slurm作业调度系统主要作用
1、单一系统映像
2、系统资源整合
3、多任务管理
4、资源访问控制
Slurm三种模式
1 批处理作业(采用sbatch命令提交,最常用方式)
2 交互式作业提交(采用srun命令提交)
3 实时分配模式作业(采用salloc命令提交)
4 隐藏细节
Slurm常用命令

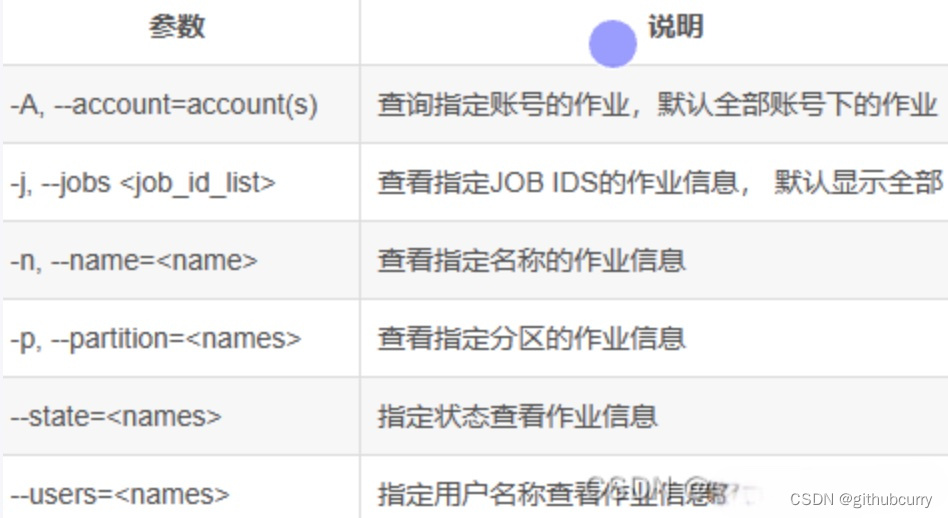
命令详情

Slurm常用单元
Slurm常用环境变量
Slurm作业提交
脚本文件基本格式:
作业脚本基本结构如下:
作业提交完整实例:
脚本常用命令
命令参数解释
squeue执行后的显示

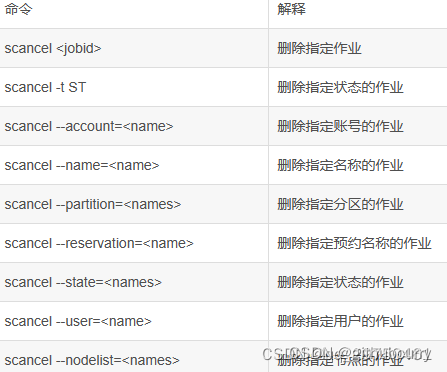
scancel 取消任务
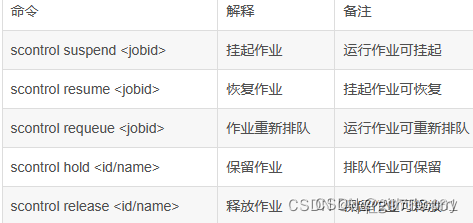
挂起作业
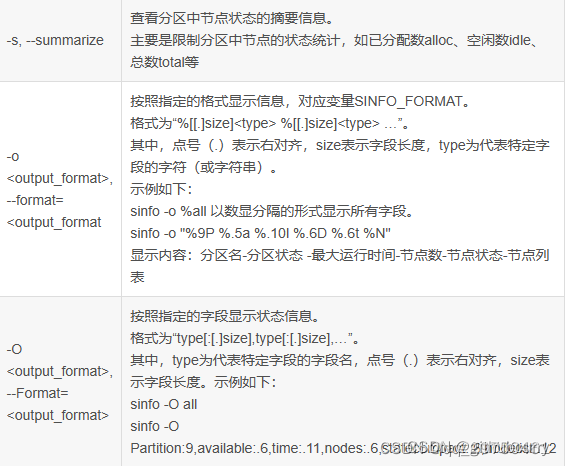
sinfo

查看节点信息
查看分区信息
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。