❀My学习Linux命令小记录(6)❀
26.ps指令
(ps.ps命令 用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。)
选项:
ps 的参数非常多, 在此仅列出几个常用的参数并大略介绍含义
–ef:显示系统中所有进程信息,包括系统进程和用户进程。它会显示出每个进程的PID、PPID(父进程ID)、C(CPU使用率)、STIME(进程启动时间)、TTY(终端)、CMD(进程命令)等信息。通过这个参数我们可以快速了解系统正在运行的进程情况
–aux:这个参数遇上一个参数类似,也可以显示系统中的所有进程信息。但不同的是,它会显示出进程的用户信息,包括进程的所有者、所属组等。这个参数对于查找特定用户的进程非常有用
-l:显示进程的长格式信息。他会显示出进程的所有详细信息,包括进程的状态(S)、CPU占用率(%CPU)、内存占用率(%MEM)、优先级(PRI)、进程运行时间(TIME)等。
-e:显示系统中正在运行的进程信息,但不包括僵尸进程(Zombie)。僵尸进程是指已经结束单父进程还没有处理的进程。使用这个参数可以过滤掉僵尸进程,使进程列表更加清晰
-A:列出所有的进程信息
-w:显示加宽可以显示较多的资讯
-C:显示指定命令的进程信息
实例:
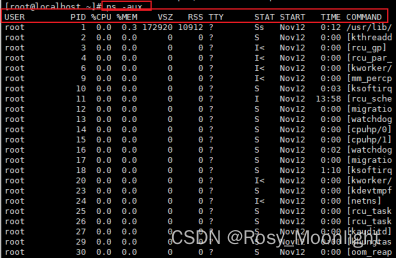
USER: 行程拥有者
PID: pid
TTY: 终端的次要装置号码 (minor device number of tty)
STAT: 该行程的状态:
R: 正在执行中
S: 静止状态
T: 暂停执行
<: 高优先序的行程
N: 低优先序的行程
L: 有记忆体分页分配并锁在记忆体内 (实时系统或捱A I/O)
START: 行程开始时间
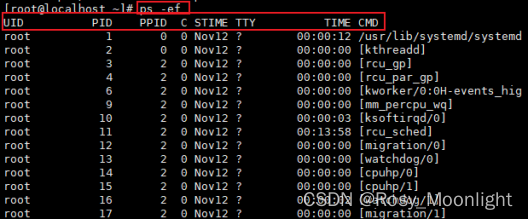
#ps -l #显示进程长格式信息

F代表这个程序的旗标 (flag), 4 代表使用者为 super user
UID 程序被该 UID 所拥有
PPID 则是其上级父程序的ID
ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running的程序,一般就是 “-“
WCHAN 目前这个程序是否正在运作当中,若为 – 表示正在运作
CMD 所下达的指令为何
27.grep指令
(ps.grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。)
grep [options] pattern [files]
或
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][–help][范本样式][文件或目录…]
files :表示要查找的文件名,可以同时查找多个文件,如果省略 files 参数,则默认从标准输入中读取数据。
选项:
^ # 锚定行的开始 如:’^grep’匹配所有以grep开头的行。
$ # 锚定行的结束 如:’grep$’ 匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:’gr.p’匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:’*grep’匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。
[] # 匹配一个指定范围内的字符,如'[Gg]rep’匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep’匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
(..) # 标记匹配字符,如'(love)’,love被标记为1。
< # 锚定单词的开始,如:'<grep’匹配包含以grep开头的单词的行。
> # 锚定单词的结束,如’grep>’匹配包含以grep结尾的单词的行。
x{m} # 重复字符x,m次,如:’0{5}’匹配包含5个o的行。
x{m,} # 重复字符x,至少m次,如:’o{5,}’匹配至少有5个o的行。
x{m,n} # 重复字符x,至少m次,不多于n次,如:’o{5,10}’匹配5–10个o的行。
w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:’Gw*p’匹配以G后跟零个或多个文字或数字字符,然后是p。
W # w的反置形式,匹配一个或多个非单词字符,如点号句号等。
更多参数说明:
– -A<显示行数> 或 —after–context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
– –b 或 —byte–offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
– -B<显示行数> 或 —before–context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
– -C<显示行数> 或 —context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
– –d <动作> 或 —directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
– -e<范本样式> 或 —regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
– -E 或 —extended–regexp : 将样式为延伸的正则表达式来使用。
– -f<规则文件> 或 —file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
– -F 或 —fixed–regexp : 将样式视为固定字符串的列表。
– -G 或 —basic–regexp : 将样式视为普通的表示法来使用。
– –h 或 —no–filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
– -H 或 —with–filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
– –i 或 —ignore–case : 忽略字符大小写的差别。
– -l 或 —file–with-matches : 列出文件内容符合指定的样式的文件名称。
– -L 或 —files–without-match : 列出文件内容不符合指定的样式的文件名称。
– -n 或 —line–number : 在显示符合样式的那一行之前,标示出该行的列数编号。
– -o[[ 或 —only–matching : 只显示匹配PATTERN 部分。
– -q 或 –quiet或–silent : 不显示任何信息。
– -r 或 –recursive : 此参数的效果和指定”-d recurse”参数相同。
– -s 或 —no–messages : 不显示错误信息。
– –v 或 —invert–match : 显示不包含匹配文本的所有行。
– -w 或 —word–regexp : 只显示全字符合的列。
– -x —line-regexp : 只显示全列符合的列。
实例:
#grep hello 1.txt #在文件file.txt 中查找字符串 “hello“,并打印匹配的行
![]()
#grep -r -n happy moon/ #在文件夹moon中递归(-r)查找所有文件中匹配正则表达式 “happy” 的行,并打印匹配行所在的文件名和行号(-n)
![]()
#echo “hello world” ./1.txt | grep –c world #在当前目录的1.txt文件中中查找字符串 “world“,并只打印匹配的行数(-c)
![]()
#grep -r update ~/moon #以递归(-r)的方式查找符合条件的文件。例如,查找指定目录~/moon及其子目录(如果存在子目录的话)下所有文件中包含字符串“update“的文件,并打印出该字符串所在行的内容

#grep –v test *1.txt* #查找文件名(1.txt)中包含 test 的文件中不包含test的行

#ifconfig eth1 |grep -E “([0-9]{1,3}.){3}” |awk ‘{print $2}’ #-E使用正则表达式提取出网卡的ip地址
![]()
28.awk指令
功能说明:AWK 是一种处理文本文件的语言(取列),是一个强大的文本分析工具。
(ps.awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。)
基本语法:
awk [选项参数] ‘script‘ var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
选项:
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F:
–v var=value 赋值一个用户定义变量,将外部变量传递给awk
-m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
BEGIN语句块、pattern语句块、END语句块:参见awk的工作原理
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
**$n** 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
[G] **ARGIND** 命令行中当前文件的位置(从0开始算)。
[G] **CONVFMT** 数字转换格式(默认值为%.6g)。
[G] **FIELDWIDTHS** 字段宽度列表(用空格键分隔)。
[A] **FILENAME** 当前输入文件的名。
[P] **FNR** 同NR,但相对于当前文件。
[G] **IGNORECASE** 如果为真,则进行忽略大小写的匹配。
[A] **NF** 表示字段数,在执行过程中对应于当前的字段数。
[A] **NR** 表示记录数,在执行过程中对应于当前的行号。
[A] **OFMT** 数字的输出格式(默认值是%.6g)。
[A] **OFS** 输出字段分隔符(默认值是一个空格)。
[A] **ORS** 输出记录分隔符(默认值是一个换行符)。
[N] **RSTART** 由match函数所匹配的字符串的第一个位置。
[N] **RLENGTH** 由match函数所匹配的字符串的长度。
[N] **SUBSEP** 数组下标分隔符(默认值是34)。
实例:
#awk ‘{print $1,$2,$5}’ OFS=” $ “ log.txt #指定字段分隔符$

用法一:
awk ‘{[pattern] action}’ {filenames} # 行匹配语句 awk ‘ ‘ 只能用单引号
实例:
#awk ‘{print $1,$4}’ log.txt # 每行按空格或TAB分割,输出文本中的1、4项

用法二:
实例:
#awk -F , ‘{print $1,$2}’ log.txt # -F使用”,“分割

#awk ‘BEGIN{FS=”,”} {print $1,$2}’ log.txt #或者使用内建变量指定字段分隔符,
#awk ‘ BEGIN{FS=” —- “} {print $1,$2,$3}’ 111 #指定字段分隔符—-

用法三:
实例:
#awk –v a=1 ‘{print $1,$1+a}’ log.txt #-v设置变量a=1,打印1,2项

#awk –v a=1 -v b=s ‘{print $1,$1+a,$1b}’ log.txt #-v设置变量a=1,b=s,打印1,2项并加上s

用法四:
awk -f {awk脚本} {文件名}
实例:
使用正则字符串匹配
#awk ‘$2 ~ /th/ {print $2,$4}’ log.txt # 输出第二列包含 “th”,并打印第二列与第四列
#awk ‘ /re/ ‘ log.txt # 输出包含 “re” 的行
#awk ‘BEGIN{IGNORECASE=1} /this/’ log.txt # 忽略大小写
awk ‘BEGIN{ print “start” } pattern{ commands } END{ print “end” }’ file
一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被 单引号 或 双引号 中,例如:
awk ‘BEGIN{ i=0 } { i++ } END{ print i }’ filename
awk “BEGIN{ i=0 } { i++ } END{ print i }” filename
awk ‘BEGIN{ commands } pattern{ commands } END{ commands }’
第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块 在awk开始从输入流中读取行 之前 被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块 在awk从输入流中读取完所有的行 之后 即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块 中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块。
29.sed指令
功能说明:功能强大的流式文本编辑器,利用脚本来处理文本文件。(替换和取行)。
(ps.sed 是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。)
基本语法:sed [-hnV][-e<script>][-f<script文件>][文本文件]
选项:
参数说明:
-e<script>或–expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或–file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或–help 显示帮助。
-n或–quiet或–silent 静默输出,仅显示script处理后的结果。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行)
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :取代,可以直接进行取代的工作,通常这个s的动作可以搭配正则表达式!例如 1,20s/old/new/g
实例:
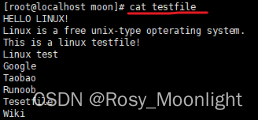
#sed -e 4anewLine testfile 在 testfile 文件的第四行(4)后添加(a)一行,并将结果输出到标准输出
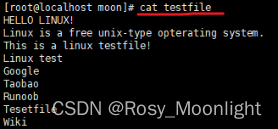
#nl testfile | sed ‘2,5d’ #将 testfile 的内容列出并且列印行号,将第 2~5 行删除
sed 的动作为 2,5d,那个 d 是删除的意思,因为删除了 2-5 行,所以显示的数据就没有 2-5 行了, 另外,原本应该是要下达 sed -e 才对,但没有 -e 也是可以的,同时也要注意的是, sed 后面接的动作,请务必以 ‘…’ 两个单引号括住喔!

#nl testfile | sed ‘3,$d’ #要删除第 3 到最后一行
#nl testfile |sed ‘2a drink tea?’ #在第二行后 加上drink tea?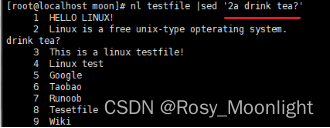
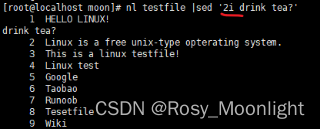
#nl testfile |sed ‘2i drink tea?’ #在第二行前加上drink tea?
#nl testfile | sed ‘2a Drink tea or……
>drink beer?’ #要增加两行以上,在第二行后面加入两行字,例如 Drink tea or ……与 drink beer?
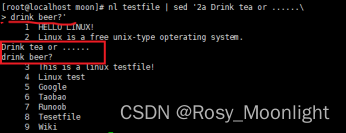
每一行之间都必须要以反斜杠 来进行新行标记。上面的例子中,我们可以发现在第一行的最后面就有 存在。
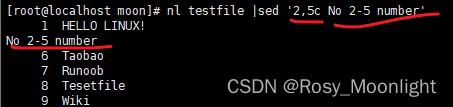
#nl testfile |sed ‘2,5c No 2-5 number’ #将第 2-5 行的内容取代(c)成为 No 2-5 number
#nl testfile |sed -n ‘5,7p’ #仅列出 testfile 文件内的第 5-7 行(打印p)

#nl testfile | sed -n ‘/oo/p’ #搜索 testfile 有 oo 关键字的行:(-n仅显示script处理后的结果)
![]()
#nl testfile |sed ‘/oo/d’ #删除 testfile 所有包含 oo 的行,其他行输出
#nl testfile | sed -n ‘/oo/{s/oo/kk/;p;q}’ #搜索 testfile,找到 oo 对应的行,执行后面花括号中的一组命令,每个命令之间用分号分隔,这里把 oo 替换为 kk,再输出这行,最后的 q 是退出,p是打印,s是取代。
![]()
#sed -e ‘s/oo/kk/g‘ testfile #g 标识符表示全局查找替换,使 sed 对文件中所有符合的字符串都被替换,修改后内容会到标准输出,不会修改原文件
#sed -i ‘s/oo/kk/g’ testfile #选项 i 使 sed 修改文件
sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!那怎办?就利用 sed 啊!透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订!
30.wc指令
(ps.wc命令 统计指定文件中的字节数、字数、行数,并将统计结果显示输出。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为“-”,则wc指令会从标准输入设备读取数据。wc同时也给出所指定文件的总统计数。)
语法:
wc(选项)(参数)
wc [选项]… [文件]…
选项:
-c :统计字节数,或–bytes或——chars:只显示Bytes数
-l :统计行数,或——lines:只显示列数
-m : 统计字符数。这个标志不能与 -c 标志一起使用
-w :统计字数,或——words:只显示字数。一个字被定义为由空白、跳格或换行字符分隔的字符串
-L :打印最长行的长度
–help :显示帮助信息
实例:
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
# wc testfile
(-l)行数为11,(-w)单词数为23,(-c)字节数为148
![]()
原文地址:https://blog.csdn.net/m0_62022097/article/details/134668080
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36874.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





