抓取检测
抓取检测被定义为能够识别任何给定图像中物体的抓取点或抓取姿势。抓取策略应确保对新物体的稳定性、任务兼容性和适应性,抓取质量可通过物体上接触点的位置和手的配置来测量。为了掌握一个新的对象,完成以下任务,有分析方法和经验方法。分析方法根据抓取稳定性或任务要求的运动学和动力学公式,选择手指位置和手部构型,经验方法根据具体任务和目标物体的几何结构,使用学习算法选择抓取。
根据是否需要进行目标定位,需要确定目标的姿态,进一步将其分为三类:具有已知定位和姿势的方法、具有已知定位和无姿态的方法、无定位和无姿态的方法。
1.1 具有已知定位和姿势
针对已知目标的经验方法,利用姿态将已知目标的抓取点转换为局部数据。主要算法有:
Multi–view self–supervised deep learning for 6d pose estimation in the amazon picking challenge.
Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge | Papers With Code
近年来,机器人仓库自动化引起了人们的极大兴趣 年,也许最明显的是亚马逊拣选挑战赛 (APC)。一个完全 自主仓库拾取和放置系统需要可靠的视觉 在杂乱的环境、自遮挡、 传感器噪声和各种各样的物体。在本文中,我们提出了一个 利用多视图 RGB-D 数据和自监督、数据驱动的方法 学会克服这些困难。该方法是 麻省理工学院-普林斯顿团队系统在装载和 拣选任务,分别在 APC 2016 上。在所提出的方法中,我们将 并使用全卷积神经网络标记场景的多个视图, 然后将预先扫描的 3D 对象模型拟合到生成的分割中,以获得 6D 对象姿势。训练深度神经网络进行分割,通常 需要大量的训练数据。我们提出了一种自监督方法 生成大型标记数据集,而无需繁琐的手动分割。我们 证明我们的系统可以可靠地估计物体的 6D 位姿 多种场景。所有代码、数据和基准测试均可在 http://apc.cs.princeton.edu/

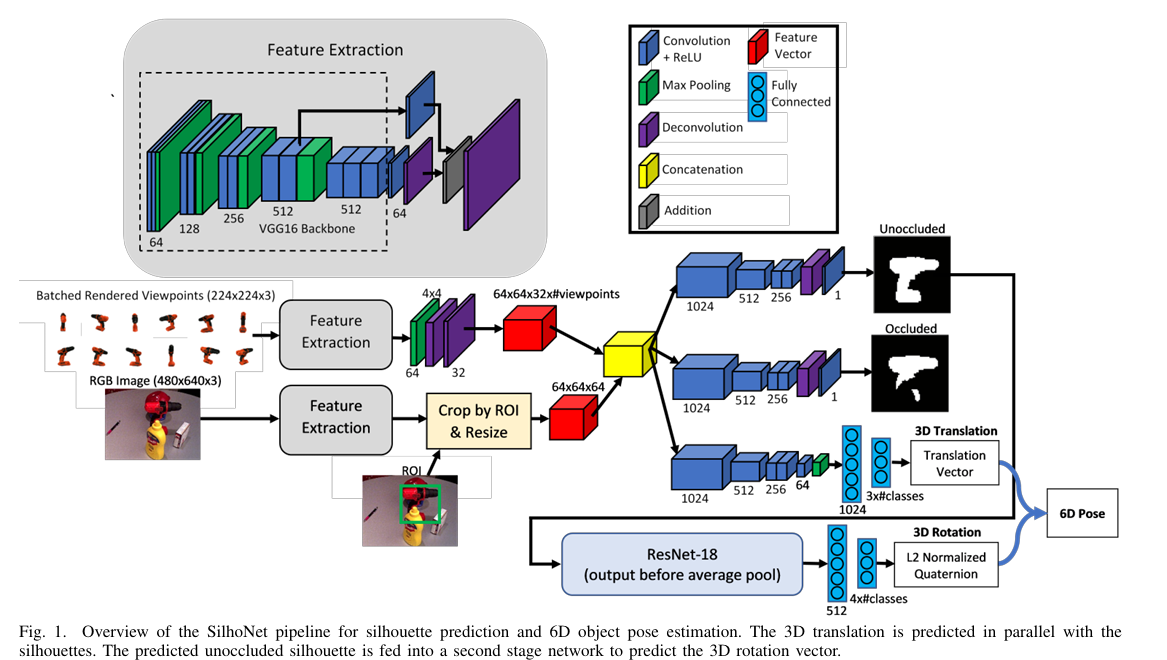
Silhonet: An RGB method for 3d object pose estimation and grasp planning.
SilhoNet: An RGB Method for 6D Object Pose Estimation | Papers With Code
自主机器人操作涉及将要操纵的物体的平移和方向估计为 6 自由度 (6D) 姿势。使用RGB-D数据的方法在解决这个问题方面取得了巨大的成功。但是,在某些情况下,成本限制或工作环境可能会限制RGB-D传感器的使用。当仅限于单目相机数据时,物体姿态估计问题非常具有挑战性。在这项工作中,我们引入了一种名为SilhoNet的新方法,该方法可以从单目图像中预测6D物体姿态。我们使用卷积神经网络 (CNN) 管道,该管道接受感兴趣区域 (ROI) 建议,以同时预测具有相关遮挡蒙版和 3D 平移矢量的对象的中间轮廓表示。然后,将 3D 方向从预测的轮廓回归。我们表明,与两个最先进的网络相比,我们的方法在YCB-Video数据集上实现了更好的整体性能,用于从单目图像输入进行6D位姿估计。
1.2 具有已知定位和无姿态的方法
主要方法:
Automatic grasp planning using shape primitives.
Part–based grasp planning for familiar objects.
Transferring grasp configurations using active learning and local replanning.
Dex–net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics.
1.3 无定位无姿态的方法
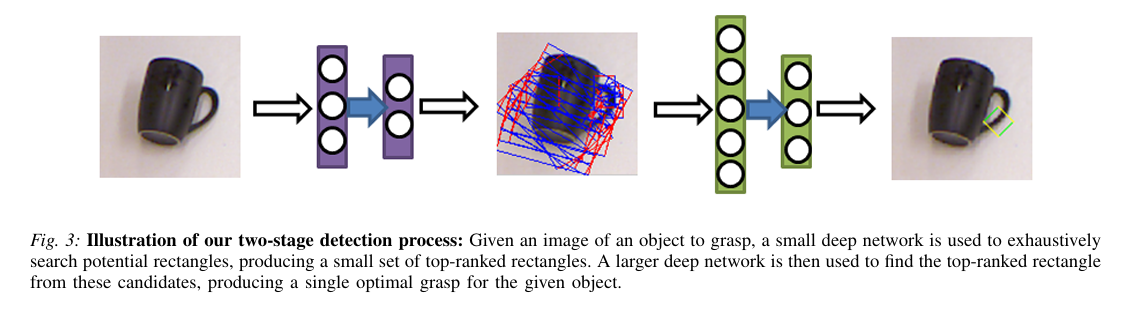
Deep learning for detecting robotic grasps.
Deep Learning for Detecting Robotic Grasps | Papers With Code
我们考虑了在RGB-D视图中检测机器人抓取的问题。 包含对象的场景。在这项工作中,我们将深度学习方法应用于 解决了这个问题,从而避免了耗时的功能手工设计。这 提出了两个主要挑战。首先,我们需要评估大量的 候选人掌握。为了使检测快速且可靠,我们 呈现具有两个深度网络的两步级联结构,其中顶部 第一个检测结果由第二个检测结果重新评估。第一个网络有 功能更少,运行速度更快,并且可以有效地修剪出不太可能的 候选人掌握。第二个具有更多功能,速度较慢,但只需运行 在前几个检测中。其次,我们需要处理好多模态输入, 为此,我们提出了一种对权重应用结构化正则化的方法 基于多模态群正则化。我们证明了我们的方法 在机器人抓取检测方面优于以前最先进的方法, 并可用于在两个不同的机器人上成功执行抓取平台。
Real-time grasp detection using convolutional neural networks.
Real-Time Grasp Detection Using Convolutional Neural Networks | Papers With Code
我们提出了一种基于卷积神经网络的准确、实时的机器人抓取检测方法。我们的网络在不使用标准滑动窗口或区域建议技术的情况下对可抓取的边界框执行单阶段回归。该模型的性能比最先进的方法高出 14 个百分点,并在 GPU 上以每秒 13 帧的速度运行。我们的网络可以同时执行分类,以便在一个步骤中识别对象并找到一个好的抓取矩形。对此模型的修改通过使用局部约束的预测机制来预测每个对象的多个抓取。局部约束模型的性能明显更好,尤其是在可以通过多种方式抓取的对象上。
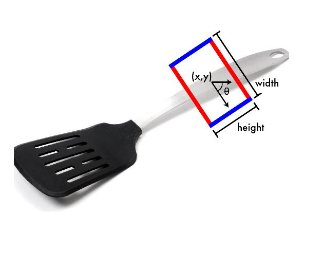
Object discovery and grasp detection with a shared convolutional neural network.
在机器人技术中,从一堆物体中实时抓取一个物体仍然是一个挑战。这就要求机器人具备快速发现物体和抓取检测的能力:首先从堆垛中挑出一个目标物体,然后应用适当的抓取配置来抓取物体。在本文中,我们提出了一种共享卷积神经网络(CNN),可以同时实时实现这两个任务。该模型在GPU上的处理速度约为每秒100帧,这在很大程度上满足了这一要求。同时,我们还建立了一个标记的RGBD数据集,其中包含用于机器人抓取的堆叠物体的场景。最后,我们演示了共享CNN模型在真实机器人平台上的实现,并展示了机器人可以从堆栈中准确地发现目标对象并成功抓取它。
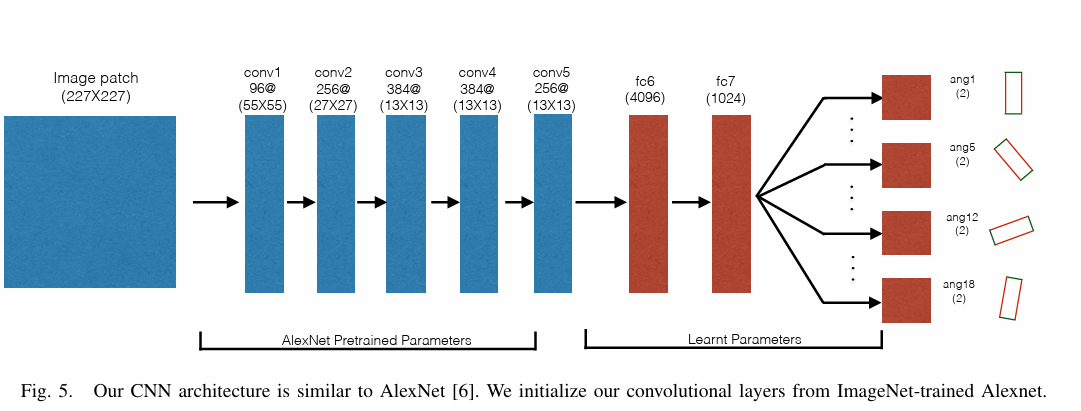
Supersizing self–supervision: Learning to grasp from 50k tries and 700 robot hours.
Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours | Papers With Code目前基于学习的机器人抓取方法利用了人类标记 用于训练模型的数据集。但是,这样的存在两个问题 方法:(a)由于每个对象可以通过多种方式手动抓取 标记抓取位置并非易事;(b) 人类标记的偏差 语义学。虽然有人尝试使用试错法来训练机器人 实验,此类实验中使用的数据量仍然很大 低,因此使学习者容易过度拟合。在本文中,我们采取 将可用训练数据增加到比以前多 40 倍的飞跃 工作,导致在 700 小时内收集的 50K 数据点的数据集大小 机器人抓取尝试。这使我们能够训练卷积神经网络 (CNN)用于预测抓取位置的任务,而不会出现严重的过拟合。在 我们的公式中,我们将回归问题重铸为 18 向二进制 对图像斑块进行分类。我们还介绍了一个多阶段的学习 方法,其中使用在一个阶段训练的 CNN 来收集硬底片 后续阶段。我们的实验清楚地表明了使用 用于抓取任务的大规模数据集(和多阶段训练)。我们 还可以与几个基线进行比较,并在 泛化到看不见的物体进行抓取。
Real-time, highly accurate robotic grasp detection using fully convolutional neural networks with high–resolution images.
Real-Time, Highly Accurate Robotic Grasp Detection using Fully Convolutional Neural Networks with High-Resolution Images | Papers With Code
机器人抓取检测新物体是一项具有挑战性的任务,但在过去几年中,基于深度学习的方法在使用 RGB-D 数据时实现了显着的性能改进,准确率高达 96.1%。在本文中,我们提出了基于全卷积神经网络(FCNN)的机器人抓取检测方法。我们的方法还实现了最先进的检测精度(高达96.6%),以及康奈尔数据集上高分辨率图像(每张360x360图像6-20ms)的最先进的实时计算时间。由于FCNN,我们提出的方法可以应用于任何尺寸的图像,以检测多目标上的多抓取。使用带有小型平行夹持器和RGB-D相机的4轴机械臂评估了所提出的方法,以抓取具有挑战性的小型新物体。通过我们提出的基于学习的全自动方法进行精确的视觉-机器人坐标校准,我们提出的方法产生了 90% 的成功率。
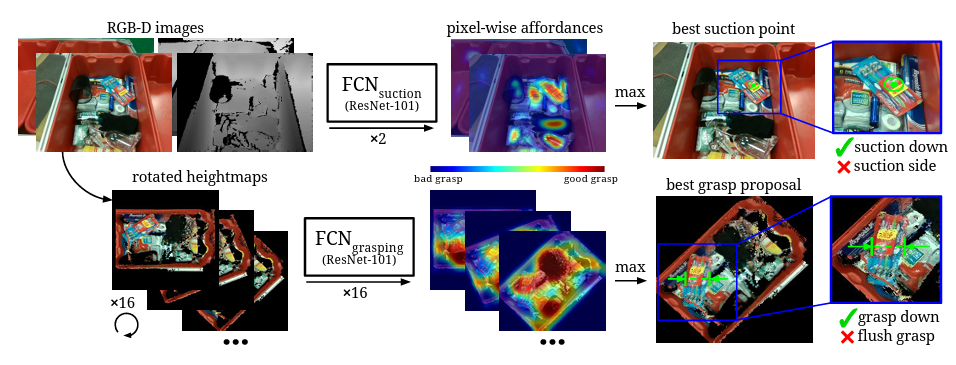
Robotic pick–and–place of novel objects in clutter with multi-affordance grasping and cross–domain image matching.
Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching | Papers With Code
本文提出了一种机器人拾取和放置系统,该系统能够在杂乱的环境中抓取和识别已知和新颖的物体。该系统的主要新功能是它可以处理广泛的对象类别,而无需对新对象进行任何特定于任务的训练数据。为了实现这一点,它首先使用与类别无关的可得性预测算法在四种不同的抓取基元行为中进行选择和执行。然后,它使用跨域图像分类框架识别选取的对象,该框架将观察到的图像与产品图像相匹配。由于产品图像可用于各种对象(例如,来自网络),因此该系统可以开箱即用地处理新对象,而无需任何额外的训练数据。详尽的实验结果表明,我们的多可用性抓取对杂乱中的各种物体都实现了很高的成功率,并且我们的识别算法对已知和新抓取的目标都实现了较高的准确率。这种方法是麻省理工学院-普林斯顿团队系统的一部分,该系统在 2017 年亚马逊机器人挑战赛的装载任务中获得了第一名。所有代码、数据集和预训练模型均可在 http://arc.cs.princeton.edu 在线获取
原文地址:https://blog.csdn.net/cocapop/article/details/134753461
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_36930.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!