确定url
找到你所需要的网站 然后进行分析检查 。
==注意: 进行搜索元素时 会有一个ctrl+f的操作
看class 或者 id 后面等于的值的时候 match 不一定是1 但是只要 这个标签下id=的这个值是唯一标识的即可 ,因为你搜索的是全部的整个页面下的这个值 但是class[id=xxx]这个会可能是唯一的。
进行分析页面在爬取
可以发现都在dd标签下
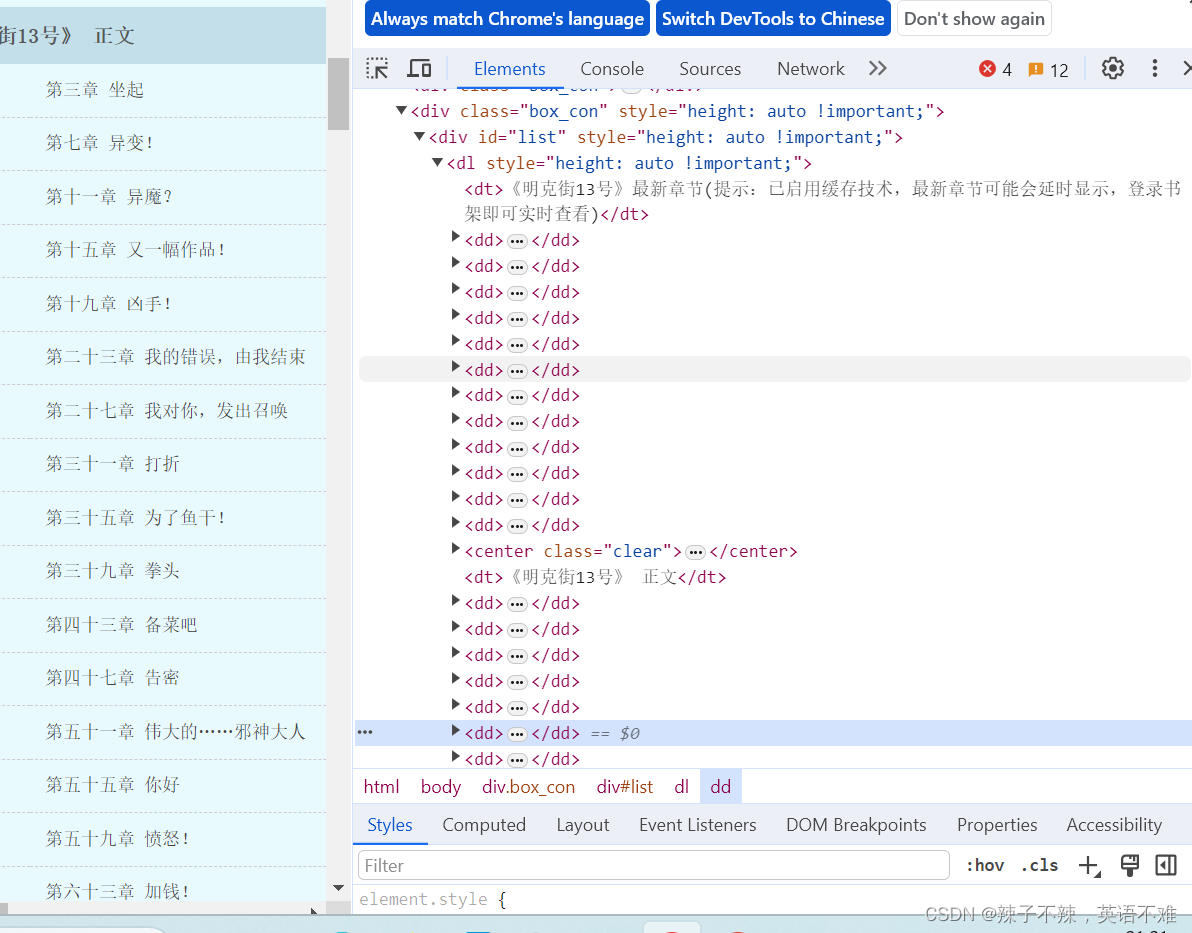
多层爬取 进入这个页面 然后爬取这一章的内容

可以发现内容都在这个标签下

爬虫代码
爬取的结果
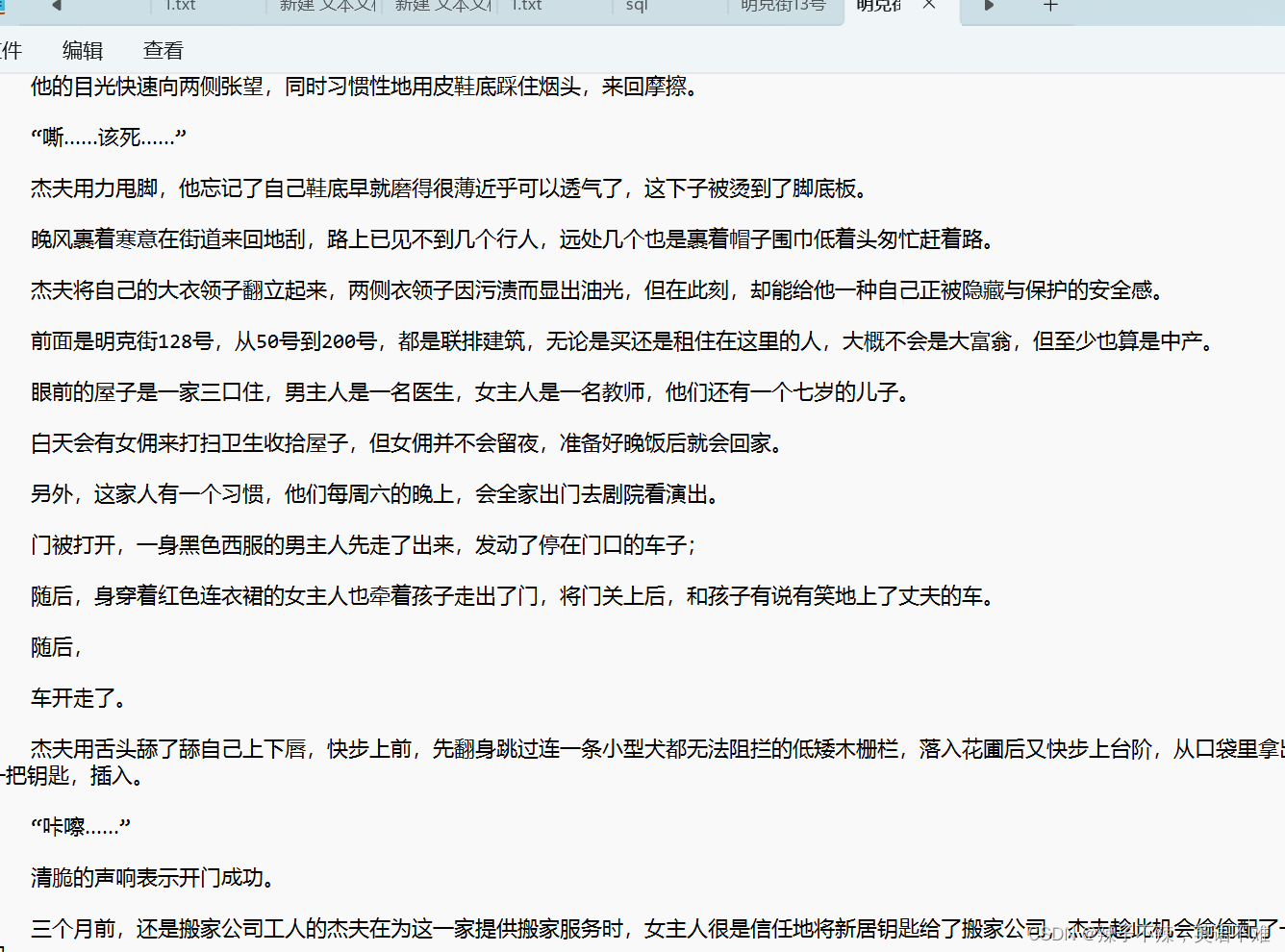
欢迎批评指正
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。