本文介绍: 今年4月,IDEA研究院发布的Grounded SAM (Grounding DINO + SAM),在Github已获得 11K Star,区别于只支持文字提示的Grounded SAM,T-Rex模型着重打造强交互的视觉提示功能。仔细思考,大模型的意义是让我们从判别式AI走向深层次判别式的AI,前者从数据和信号中去提取特征进行识别,完成像人脸识别语音识别、图像识别等任务,后者可以基于海量数据训练生成文字、语言、图片、视频等,更加智能、高效,有效提高生产力。在此情况下,视觉提示显然是更高效的方法。
目标检测作为当前计算机视觉落地的热点技术之一,已被广泛应用于自动驾驶、智慧园区、工业检测和卫星遥感等场景。开发者在研究相关目标检测技术时,通常需熟练掌握图像目标检测框架,如通用目标检测框架 YOLO 系列,旋转目标检测框架 R3Det 等技术,学习门槛较高,还需不断优化和改进算法,来获得理想的目标检测效果。随着大模型的发展,有效帮助开发者降低目标检测的使用门槛。
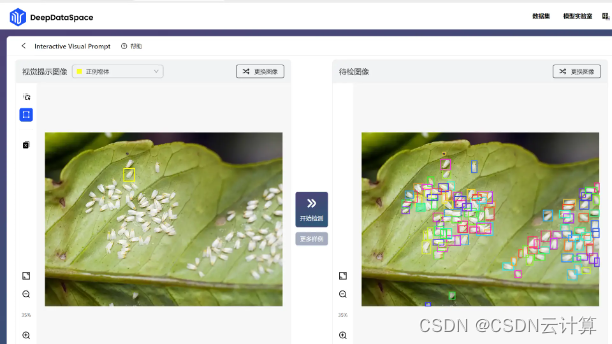
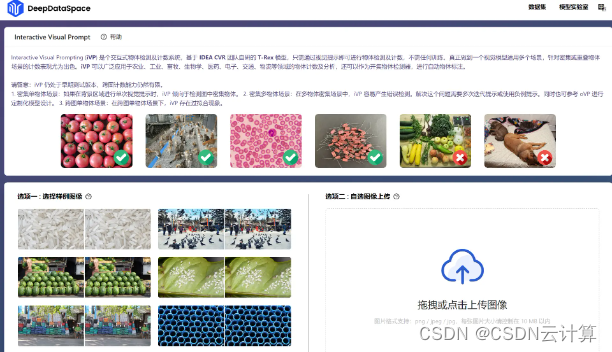
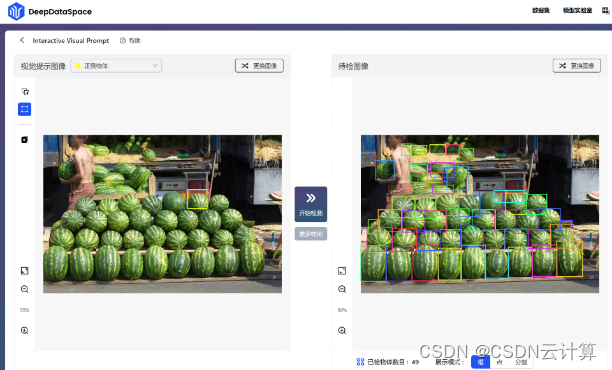
在2023 IDEA大会,IDEA研究院发布最新视觉提示(Visual Prompt)模型T-Rex,帮助释放计算机视觉更多应用场景。小编在上手使用T-Rex模型,直呼太香了!无需设计算法,开箱即用,简单通过拖拽方框,框住想识别的物体,点击“开始检测”,就自动将相似的结果识别出来:

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。